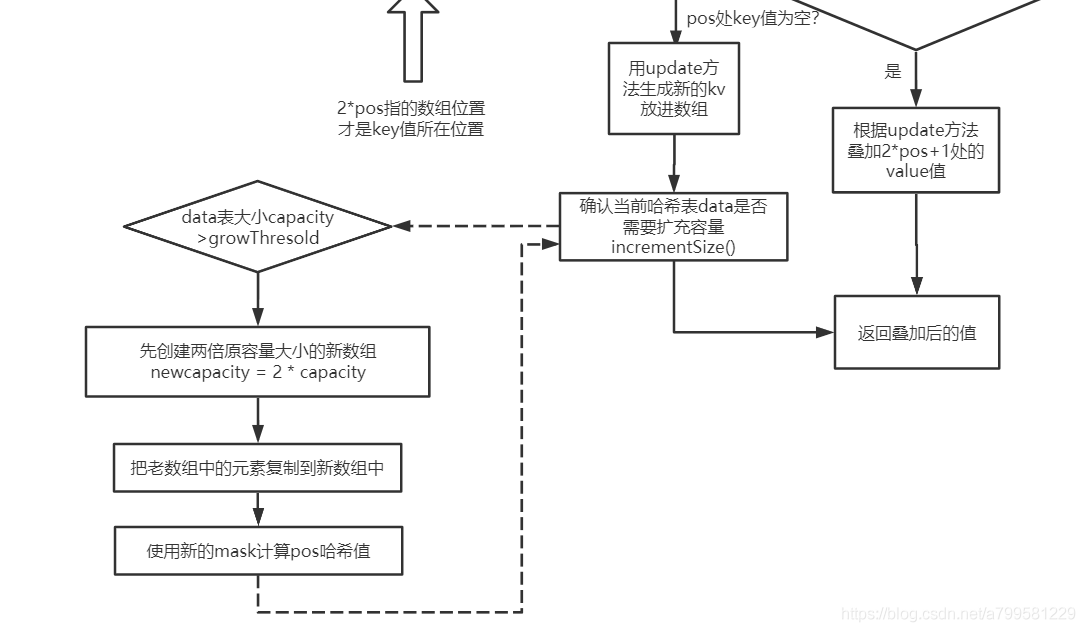
[toc]
首先回顾一下memoryStore是做什么的。
他主要是将没有序列化的java对象数组或者序列化的byteBuffer放到内存中。
但是这就涉及到一些内存管理的问题,如果放不下,是不是要放磁盘?什么时候认为放不下?这里会一一解读。
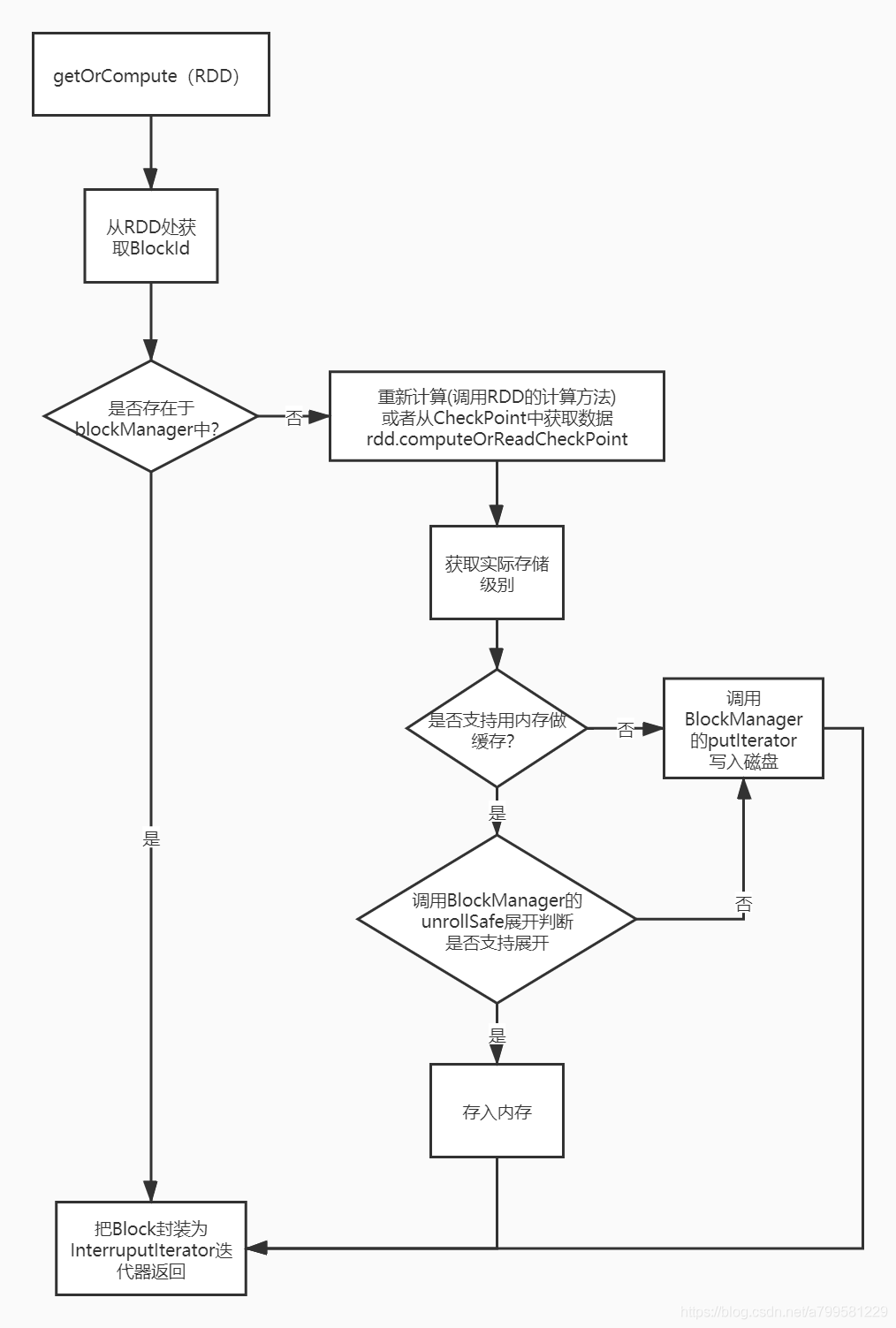
MemoryStore的putIterator
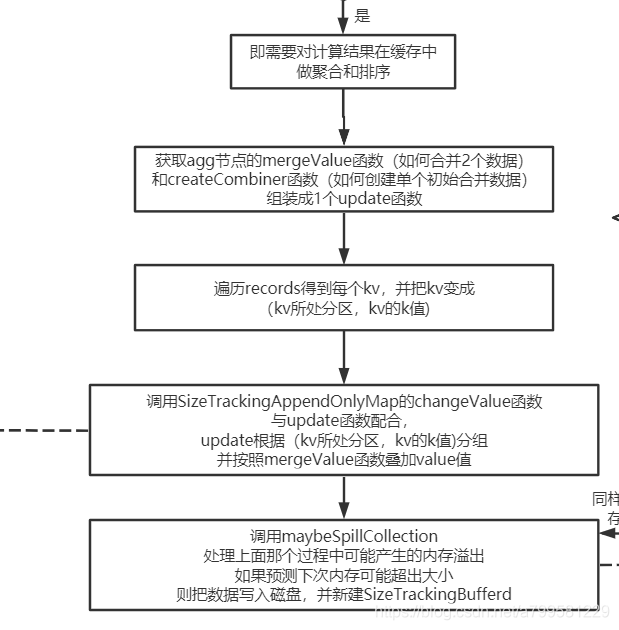
这个方法是把一堆values的数组内容放入内存中(本质上就是放到Map<blockId, blockEntry>中。
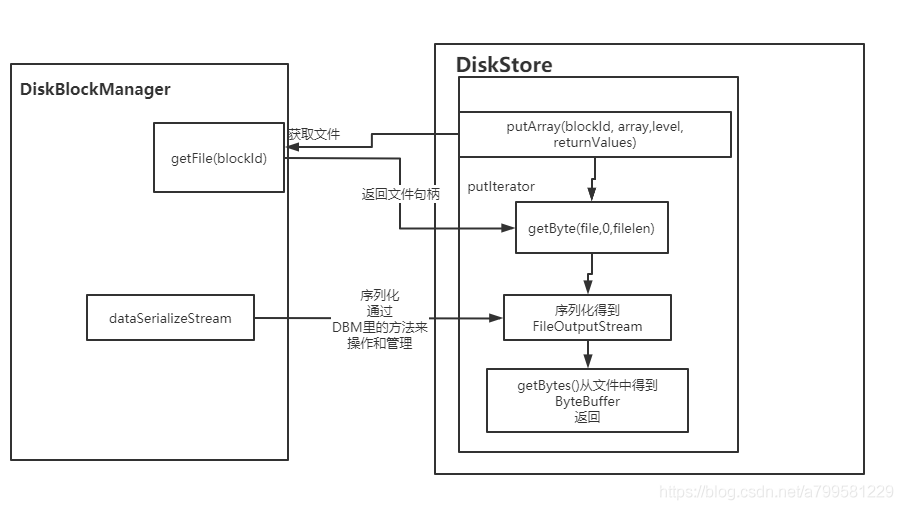
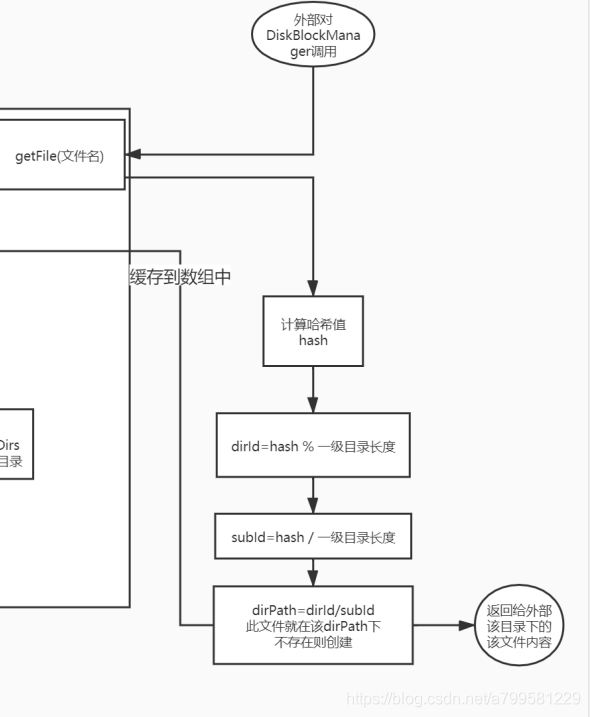
如果发现内存足够,能够申请,则调用putArray把数据写入内存(就是放到map中), 否则就去调用diskStore的接口写入磁盘中。
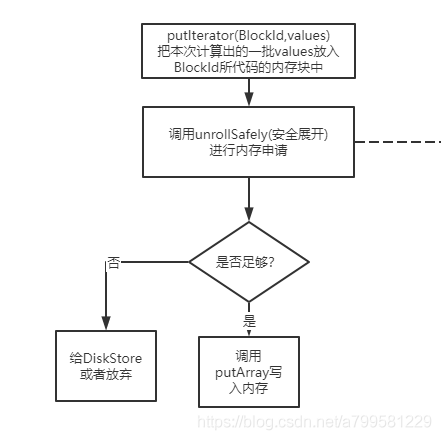
这里我先打住,不直接往下讲,而是给自己假设场景,如果是自己在开发计算引擎,写executor里的block缓存,肯定需要思考这个问题:
什么时候认为内存是足够的?
最简单的一个做法:
- 我给每个memoryStore设定一个阈值MaxMemory,
- 维护一个值currentMemory, 这个值就是memoryStroe里那个Map<BlockId,memoryEntry>所占的大小。
- 然后遍历计算一下输入参数values所占的内存大小 needMemory
- 如果needMemory > maxMemory - currentMemory, 则认为内存不足,写入到磁盘。
这个做法相当于直接把整个values大小都计算好之后,如果ok,马上进行写入内存操作。
如果是memoryStore是单线程的模块那ok, 但如果这个putIterator是一个支持多线程写入的模块呢?
当我觉得100M足够,我写入,可能得花10s, 然后另外一个线程也觉得100M足够,也要写入,结果写到一半发现内存不够,就尴尬了。
因此问题变为:
多线程时,如果确保计算的内存量是有效的?
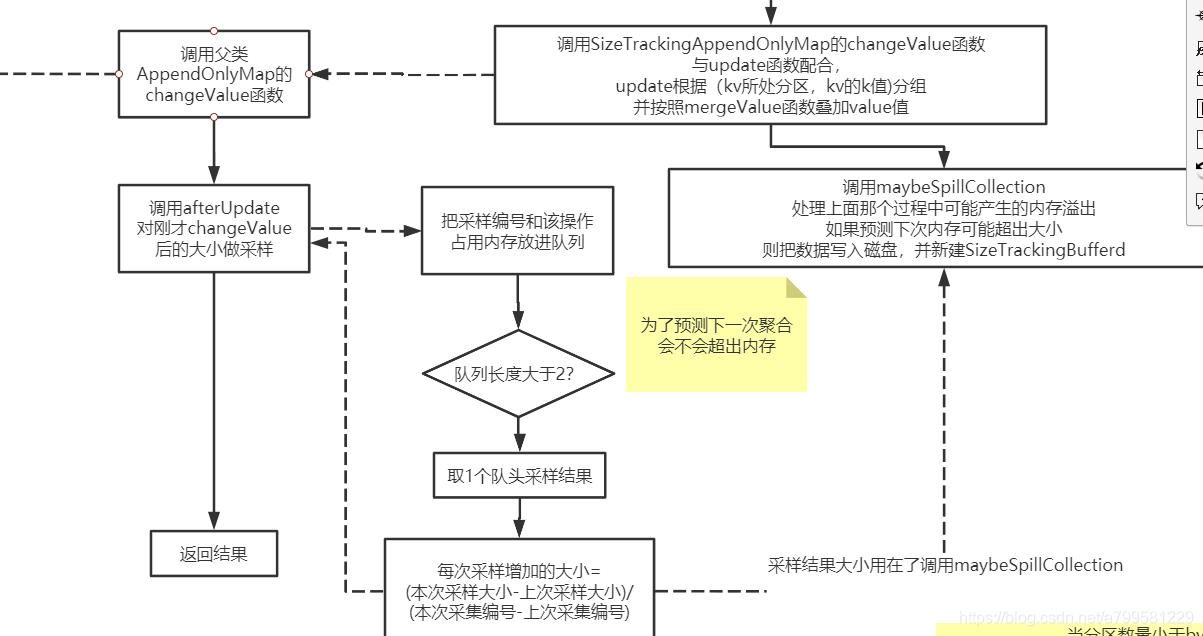
一种方式,就是每次确定要写入时, 把要写入的这100M的量直接加到currentMemory中。 后面的线程要判断时,直接拿最新的curentMemory判断。
但实际上这个数据并没有真正写入map中, 有可能中间出现写入失败或者线程中断, 那这时候已经被处理过的currentMemory就不好搞了。
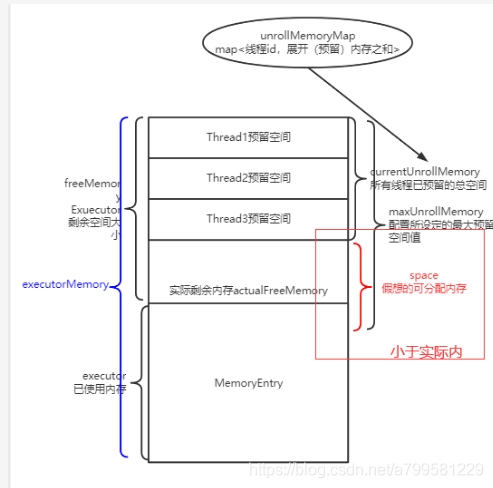
所以引入一个概念,叫展开内存unrollMemory。
每个线程都有自己的unrollMemory, 可以理解为该线程 准备 写入到内存中的大小。
因此我们统计剩余可写入内存时, 实际上是等于 MaxMemory - currentMemory - 所有线程unrollMemory总和。
但是我们又不能让线程展开的这个值正好把剩余内存占满,所以会设定一个展开内存总和maxUnrollMemory,替代MaxMemory。
因此此时我这个线程可用的剩余内存space,实际上为
maxUnrollMemory - cyrrentUnrollMemory。
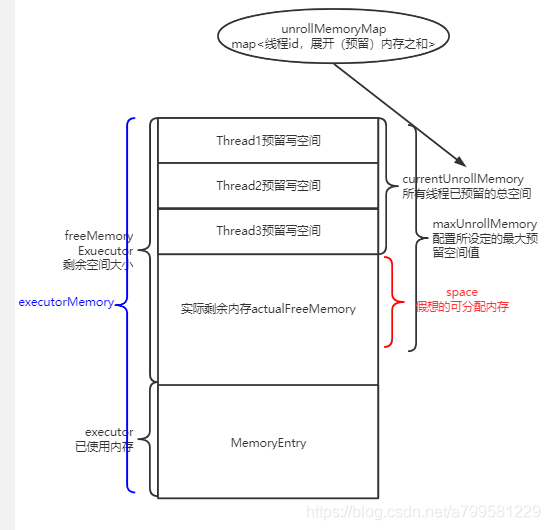
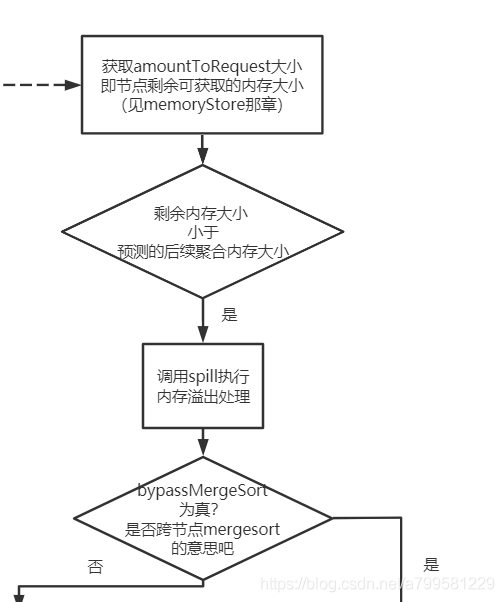
但问题又来了,如果我们假想的可分配内存比实际剩余内存小,怎么办?如下图:
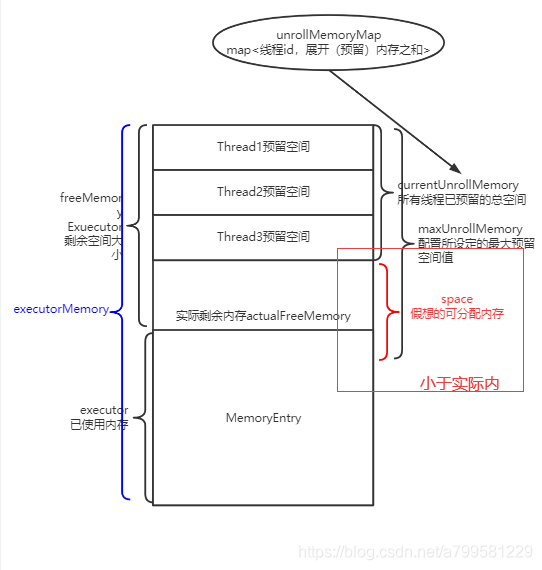
一种方式,是发现假想剩余内存小于实际剩余内存时,认为内存不足,把数据写入磁盘。
但有个问题, 假设我需要写入100M, 实际剩余内存是98M, 其实只差了2M, 那为什么不能挤挤呢?只差2M了啊哥!
然而我肯定不能去动其他线程的unrollMemory,毕竟人家都认为自己是ok的准备写入了,你总不能插队吧?如果能动其他线程准备写入的数据,这管理就太复杂了。
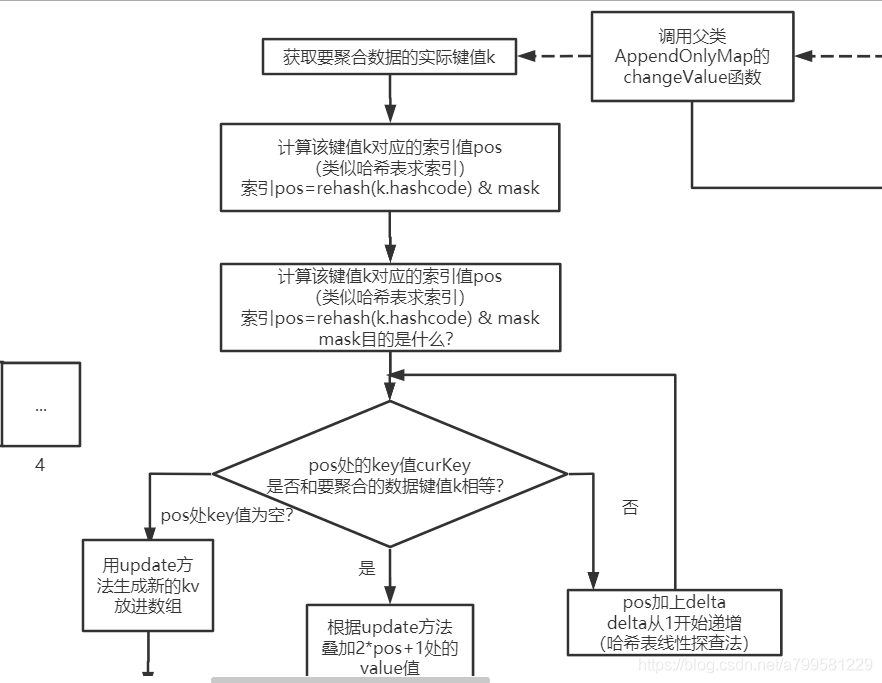
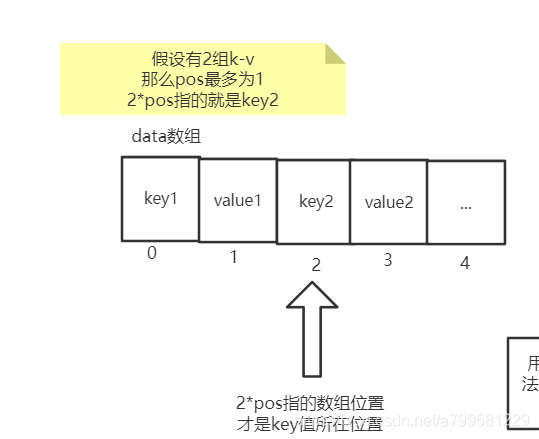
因此我们需要去已使用内存MemoryEntry里面找, 找一下是不是有比较小的block块,比如有一个块只有5M, 那我就把这个block块放入磁盘,那么我就可以塞进去了!
解答完上述问题后,再学习memoryStore的内存写入管理机制,就容易多了。
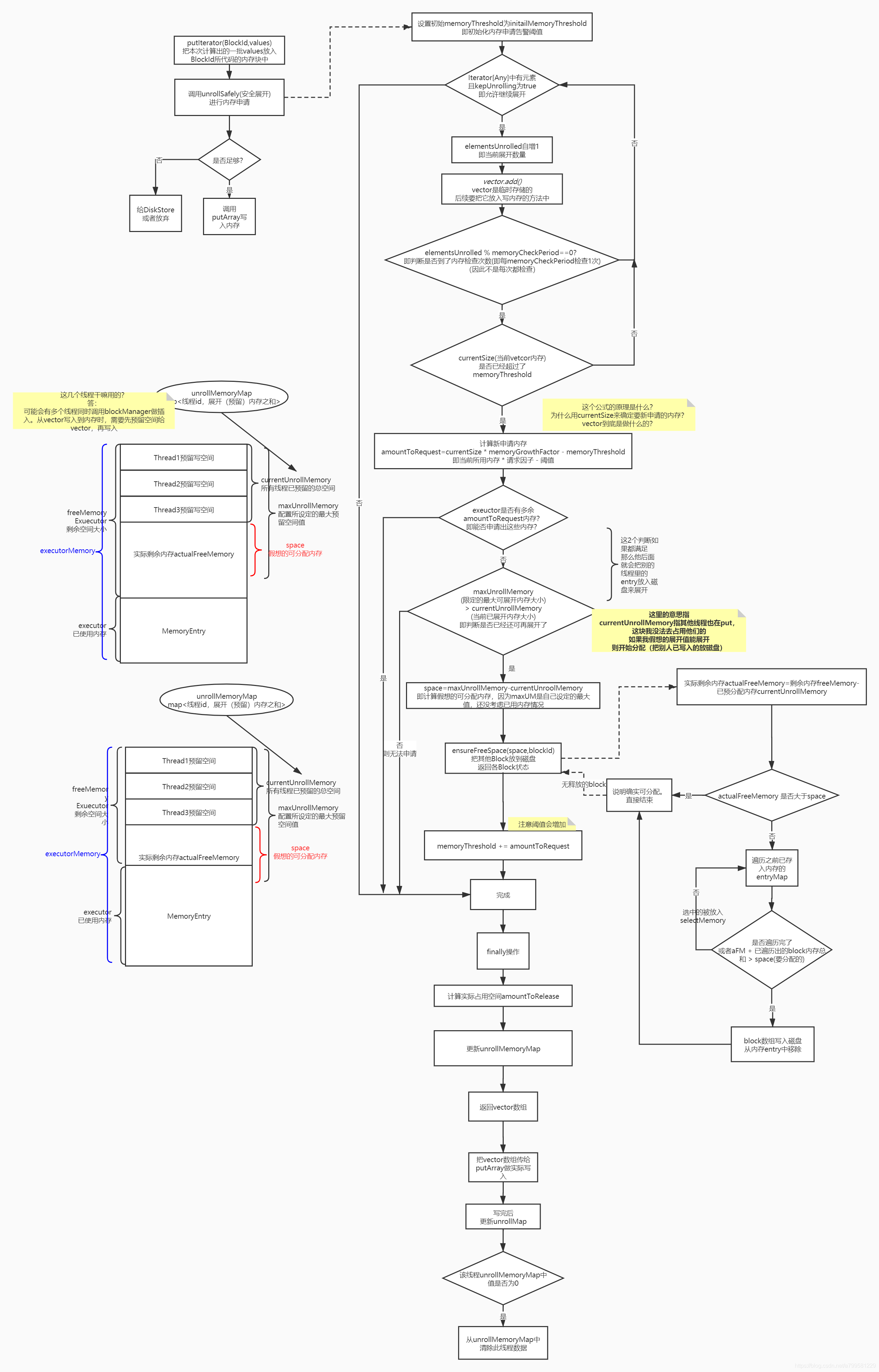
memoryStore完整安全展开流程
1. 计算需要写入的内存大小,是否需要申请新内存
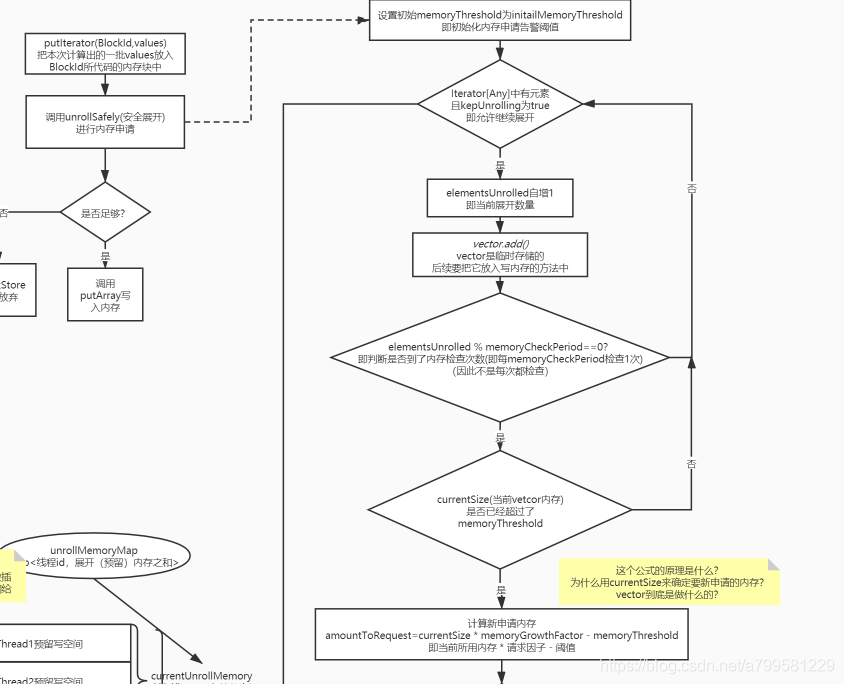
这里的计算不同于上文中提到的直接遍历完之后判断总大小
因为当时传入的是一个迭代器,只能迭代一次,每次迭代时都需要放入vector这个临时存储的列表中,万一超级大,放入vector时超出范围就GG了, 所以它实际时每隔一段就会检查一下是否超出阈值。
2. 计算剩余可用的展开空间
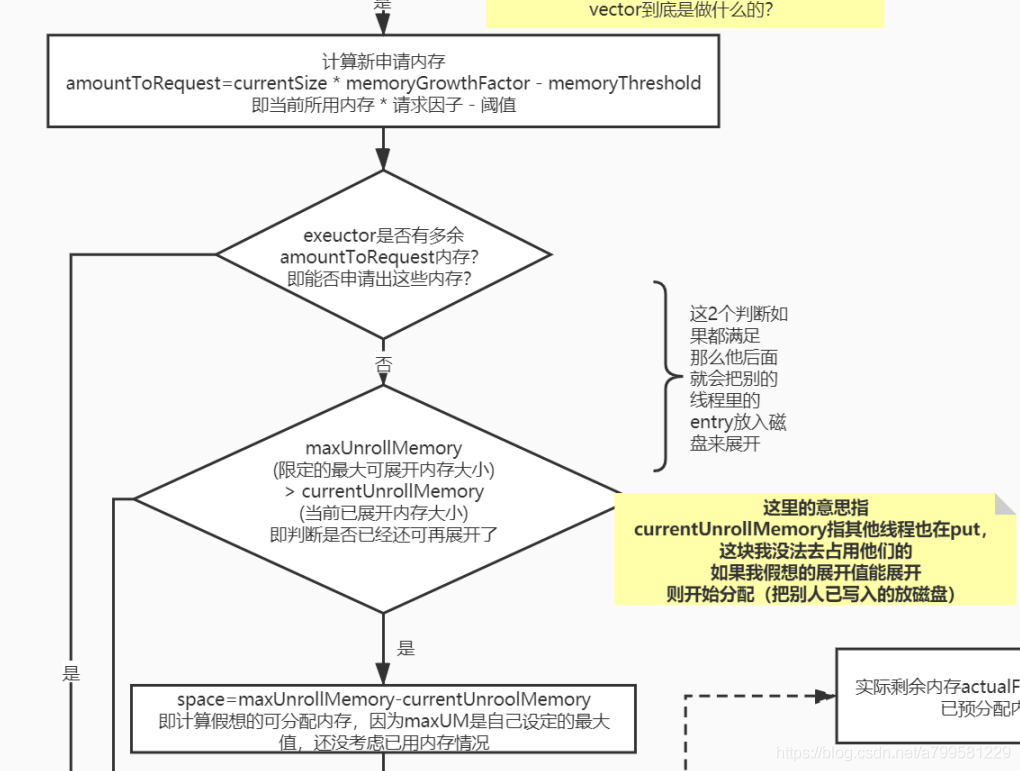
spark就是上文提到的这个:
如果小于实际内存,那么就需要去已分配的内存中找,看下能不能抽一些小朋友去磁盘中。
spark不足时,检查能否抽一些已分配内存区磁盘
核心方法来自ensureFreeSpace,看下它的实现
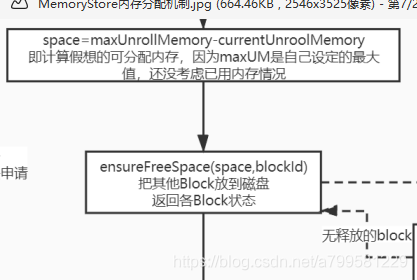
这个过程比较简单,也没做太多优化,不考虑最优情况,否则会有排序的性能问题。
如果发现抽内存也不够用, 那就直接认为不行了。
如果ok,那就认为可行,
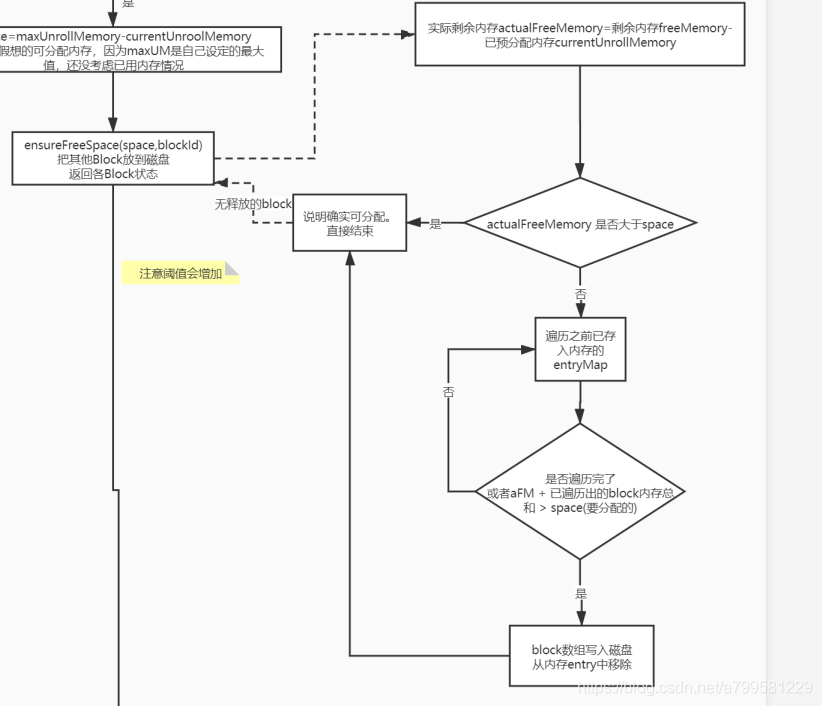
内存足够分配,写入
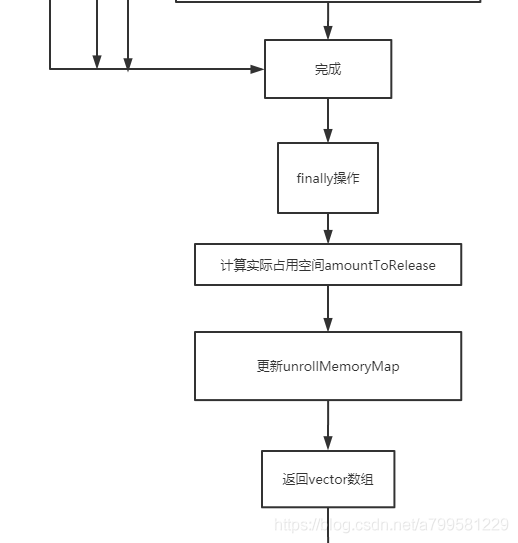
最后会返回一个vector数据
这个vector会拿去做真正的写入操作。
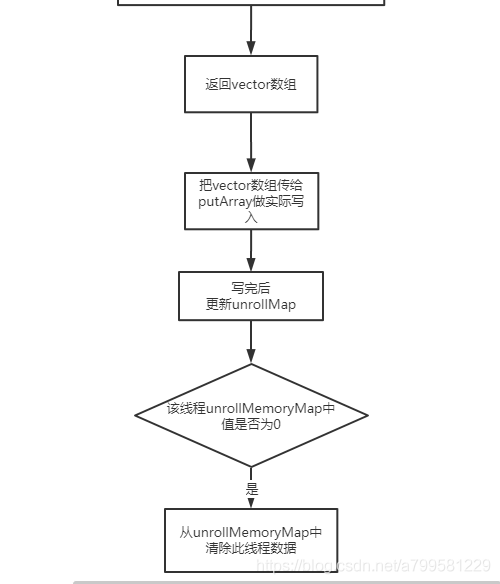
完整过程: