DDD领域模型的抽象概念 首先,来一段大家可能经常看到,但没实践时总是一脸懵的一段DDD领域模型的介绍:
DDD领域模型是指将业务领域中的核心概念和业务规则映射为软件系统中的对象和方法。这种方法将业务领域划分为不同的子领域,每个子领域都有自己的领域模型。
领域模型的设计要基于业务需求,通过对业务需求的深入理解来实现领域模型的设计,以实现软件系统的可扩展性、可维护性、可理解性和高内聚性。
在DDD中,领域模型是通过一系列领域对象来实现的。领域对象是指在业务领域中有实际存在并且在业务过程中具有明确角色和行为的概念,如订单、客户等。领域对象通过各种行为来实现业务逻辑,并且在应用程序中通过数据持久化来存储和恢复领域对象的状态。
领域模型的设计需要深入了解业务领域,同时还需要考虑系统的性能和可扩展性等因素,以实现系统的最佳性能和灵活性。在设计领域模型时,应该遵循领域驱动设计的原则,例如将业务逻辑放置在领域对象中,尽可能减少数据转换的操作等。
是不是感觉很抽象?但如果能和我们常见的开发代码模式做对比,可能就好理解很多了。
传统的三层结构 如果你的项目是比较传统的java服务项目,那么大概率是 先定义一个controller(接口类),定义一个实体类(用于定义请求体和返回体) 然后定义一个service(数据处理类), 再定义一个dao(数据库处理类) 。这种模式的主要问题在于:
分层过度:控制器、模型和数据访问对象之间的关系非常紧密,这导致应用程序的层次结构非常深,代码也变得非常复杂。开发人员需要花费大量的时间和精力来维护这种复杂的层次结构。
基于数据模型:传统的Spring MVC模式通常是基于数据模型来设计和开发的。这种模式会将业务逻辑和数据访问逻辑混杂在一起,导致代码变得难以维护和扩展。
依赖于框架:传统的Spring MVC模式通常依赖于特定的框架和库,例如Spring、MyBatis等。这种依赖关系会使得应用程序的可移植性和可扩展性变得非常差。
举个java代码的例子, 假设我们有一个用户管理系统,其中包含用户的基本信息和订单信息。我们使用传统的Spring MVC模式来设计这个系统,代码可能如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 @RestController @RequestMapping("/users") public class UserController { @Autowired private UserService userService; @GetMapping("/{id}") public UserDTO getUser (@PathVariable Long id) { User user = userService.getUserById(id); return new UserDTO (user.getId(), user.getName(), user.getEmail()); } @PostMapping public UserDTO createUser (@RequestBody UserDTO userDTO) { User user = new User (userDTO.getName(), userDTO.getEmail()); user = userService.createUser(user); return new UserDTO (user.getId(), user.getName(), user.getEmail()); } } UserDTO.java (数据传输对象) public class UserDTO { private Long id; private String name; private String email; } UserService.java (服务层) @Service public class UserService { @Autowired private UserDao userDao; public User getUserById (Long id) { return userDao.findById(id); } public User createUser (User user) { return userDao.save(user); } } UserDao.java (数据访问层) @Repository public class UserDao { @Autowired private JdbcTemplate jdbcTemplate; public User findById (Long id) { String sql = "SELECT * FROM users WHERE id = ?" ; User user = jdbcTemplate.queryForObject(sql, new Object []{id}, new UserRowMapper ()); return user; } public User save (User user) { return user; } }
其中,UserController负责处理用户请求,UserService负责处理业务逻辑,UserDao负责与数据库交互。
让我们考虑以下情况,在我们的用户管理系统中,我们需要添加一种新的角色类型,比如“管理员”。为了实现这个功能,我们需要在应用程序中进行以下更改:
首先,在用户服务中,我们需要更新User实体类的构造函数,以添加新的角色类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class User { private Long id; private String name; private String email; private String role; public User (String name, String email, String role) { this .name = name; this .email = email; this .role = role; } }
这样虽然可以实现需求,但是这个方法的实现涉及到多个对象(UserController, User, UserService、 UserDao ),代码耦合度比较高,如果需要增加更多的功能,可能会变得越来越复杂,难以维护。
我们来看一下如何使用DDD领域模型来实现用户管理系统,并添加一个新的角色类型。在这个例子中,我们使用以下核心概念:
一个User实体,将表示一个用户对象
一个Role实体,将表示用户角色
一个UserRepository接口,将提供对用户实体进行持久化的方法
一个UserService服务,将提供对用户对象的操作,包括创建、获取、更新和删除
首先,我们定义一个User实体,并将其映射到数据库表users中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Entity @Table(name = "users") public class User { @Id @GeneratedValue private Long id; private String name; private String email; @ManyToOne @JoinColumn(name = "role_id") private Role role; }
然后,我们定义一个Role实体,并将其映射到数据库表roles中,以及相关的User和Role之间的关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Entity @Table(name = "roles") public class Role { @Id @GeneratedValue private Long id; private String name; }
然后,我们定义一个UserRepository接口,并使用ORM框架(如Hibernate)来实现它:
1 2 3 4 5 @Repository public interface UserRepository extends JpaRepository <User, Long> { }
接下来,我们定义一个UserService服务,该服务封装了对用户对象的所有操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @Service @Transactional public class UserService { private final UserRepository userRepository; private final RoleRepository roleRepository; @Autowired public UserService (UserRepository userRepository, RoleRepository roleRepository) { this .userRepository = userRepository; this .roleRepository = roleRepository; } public User createUser (String name, String email, Role role) { User user = new User (); user.setName(name); user.setEmail(email); user.setRole(role); userRepository.save(user); return user; } public User getUserById (Long id) { return userRepository.findById(id).orElseThrow(() -> new EntityNotFoundException ("User not found" )); } public List<User> getAllUsers () { return userRepository.findAll(); } }
最后,我们需要更新我们的UserController并向我们的UserDTO添加role属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @RestController @RequestMapping("/users") public class UserController { private final UserService userService; @Autowired public UserController (UserService userService) { this .userService = userService; } @PostMapping public UserDTO createUser (@RequestBody UserDTO userDTO) { Role role = userService.getRoleById(userDTO.getRoleId()); User user = userService.createUser(userDTO.getName(), userDTO.getEmail(), role); return new UserDTO (user.getId(), user.getName(), user.getEmail(), user.getRole().getName()); } }
现在,当我们需要添加一个新的角色类型时,我们只需在我们的Role实体中添加一个新的属性即可。然后,我们更新User实体的映射和UserController中的DTO,以便使用新的Role属性。这样,我们就可以通过更新领域对象来实现功能的扩展,而不会对整个系统造成过多的影响。
为什么说“使用了DTO对象来进行数据传输,会使得应用程序的业务逻辑难以实现或者出现其他问题”,这个问题请仔细思考后,告诉我为什么,必须要让我心服口服的那种 ?
DTO(Data Transfer Object)是用于在不同层之间传递数据的对象,通常由Controller层创建并传递给Service层或者Dao层。DTO通常只包含数据,不包含业务逻辑。在传输数据时,DTO对象会被序列化和反序列化,而这个过程需要消耗额外的资源和时间。
在三层架构中,Controller层和Service层之间通常使用DTO对象来传输数据,这样做的好处是可以使得Controller层和Service层解耦,降低它们之间的依赖关系。但是,使用DTO对象也会带来一些问题:
增加开发复杂度:使用DTO对象会增加开发复杂度,因为需要定义DTO对象、编写DTO对象的转换代码等。同时,DTO对象的设计也需要考虑到不同层之间数据的传输,这增加了设计的难度。
难以实现业务逻辑:在Controller层和Service层之间使用DTO对象传输数据,会使得Service层无法访问Controller层的请求参数,从而难以实现业务逻辑。如果Service层需要访问Controller层的请求参数,就需要将这些参数也包含在DTO对象中,这样就增加了DTO对象的复杂度。
代码重复和不一致性:使用DTO对象可能会导致代码重复和不一致性的问题。例如,在Controller层和Service层之间传输数据时,可能会出现多个DTO对象定义相同的字段,这会导致代码重复。另外,DTO对象的定义可能会因为不同的开发人员而产生不一致性,这也会导致代码的不一致性。
因此,在DDD领域模型中,建议使用领域对象(Domain Object)来传输数据,而不是使用DTO对象。领域对象是具有业务逻辑的对象,它们不仅包含数据,还包含业务逻辑。使用领域对象可以减少代码的复杂度和重复性,同时也可以更好地支持业务逻辑的实现。
DDD领域模型是怎么解决上面的“开发复杂度”这个问题的? ?
DDD领域模型通过将业务逻辑放在领域对象中,以及将数据访问逻辑封装在领域仓库中来解决开发复杂度问题。
在DDD中,领域对象包含了业务逻辑和状态,它们封装了数据和行为,代表了业务上的概念和操作。在领域对象中实现了业务逻辑后,应用程序的其他部分只需要关心领域对象的输入和输出,而不必关心具体的实现细节。
此外,领域仓库则负责封装数据访问逻辑,将数据存储和检索细节与领域对象分离,使得领域对象能够独立地进行业务逻辑处理。通过领域仓库,应用程序能够对领域对象进行存储和检索,而不必关心底层的数据存储技术和细节。
总之,DDD领域模型通过将业务逻辑和数据访问逻辑封装在领域对象和领域仓库中,从而将复杂性分散和隔离,使得应用程序能够更加灵活和可扩展,从而降低开发的复杂度和难度。
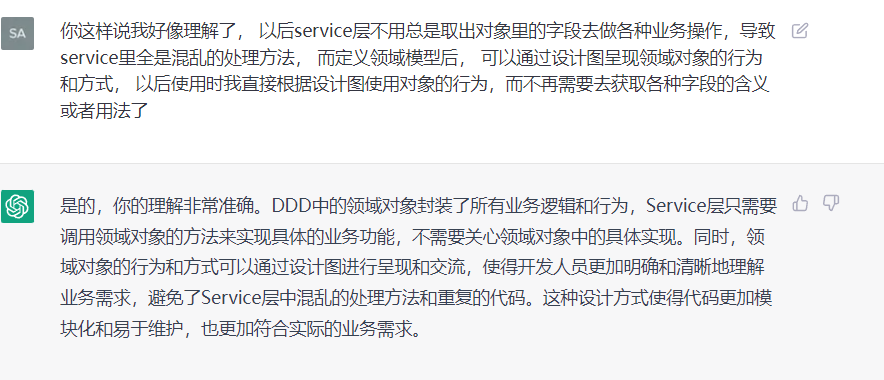
之前三层结构中, 业务逻辑全是service里定义各种方法去处理生成新的对象之类的, 而DDD里,则各种业务逻辑行为都是在领域对象里, 领域对象去触发行为, 最后service只负责调用数据库层去存储,而不关心对象里有哪些字段,只关心对象有哪些行为,是这样吗 ?
是的,DDD的思想是将业务逻辑放在领域对象中,这样可以将领域逻辑尽量地与技术实现分离,从而更好地聚焦业务需求,而不是技术实现。
在DDD中,领域对象是具有行为的,即领域对象应该封装着相关的业务行为,例如订单对象可能会有下单、支付、取消等行为。这些行为由领域对象自身触发,而不是通过Service来调用。
在这样的设计中,Service层不再是一个简单的CRUD操作集合,而是将领域对象协调起来进行业务流程处理的一个过程,它的作用更多是组织和协调各个领域对象完成业务流程,而不是实现具体的业务逻辑。同时,Service层也会负责将领域对象持久化到数据库中,但是Service层并不关心对象有哪些字段,只需要将对象交给数据访问层进行保存即可。
因此,DDD通过将领域逻辑封装在领域对象中,将应用程序的业务逻辑聚焦到领域对象中,从而提高了代码的可读性、可维护性和可扩展性。
用DDD领域模型进行重构 那么基于上述内容,我将用DDD领域模型进行重构,完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 @RestController @RequestMapping("/users") public class UserController { @Autowired private UserService userService; @GetMapping("/{id}") public UserDTO getUser (@PathVariable Long id) { User user = userService.getUserById(id); return UserDTO.from(user); } @PostMapping public UserDTO createUser (@RequestBody UserDTO userDTO) { User user = User.create(userDTO.getName(), userDTO.getEmail()); userService.save(user); return UserDTO.from(user); } } public class User { private Long id; private String name; private String email; private User (Long id, String name, String email) { this .id = id; this .name = name; this .email = email; } public static User create (String name, String email) { return new User (null , name, email); } public void update (String name, String email) { this .name = name; this .email = email; } } public interface UserRepository { User findById (Long id) ; void save (User user) ; } public interface UserService { User getUserById (Long id) ; void save (User user) ; } @Service public class UserServiceImpl implements UserService { @Autowired private UserRepository userRepository; @Override public User getUserById (Long id) { return userRepository.findById(id); } @Override public void save (User user) { userRepository.save(user); } } @Repository public class UserRepositoryImpl implements UserRepository { @Autowired private JdbcTemplate jdbcTemplate; @Override public User findById (Long id) { String sql = "SELECT * FROM users WHERE id = ?" ; User user = jdbcTemplate.queryForObject(sql, new Object []{id}, new UserRowMapper ()); return user; } @Override public void save (User user) { } } public class UserDTO { private Long id; private String name; private String email; public static UserDTO from (User user) { return new UserDTO (user.getId(), user.getName(), user.getEmail()); } }
领域对象之间的交互 有时候 领域对象里的行为,如果比较复杂, 比如涉及2个领域对象A和B的交互, 在DDD中,关于将具体的业务逻辑行为定义在哪个领域对象中,通常会采用聚合根和实体的概念来帮助决策。聚合根代表整个聚合的根实体,实体则是聚合中的其他实体。在一个聚合中,聚合根是负责协调聚合内部实体之间关系的主要实体,因此通常情况下应该将复杂的业务逻辑行为定义在聚合根中。
举个例子,我们假设有一个电子商务网站,用户可以下订单购买商品。在这个场景中,我们可以将订单和商品作为两个独立的领域对象来设计。但是,当一个用户下订单时,订单和商品之间有一定的关联关系。为了维护订单和商品之间的关系,我们可以创建一个聚合根来管理它们。 订单可以作为聚合根,商品则是聚合中的子对象。聚合根负责维护订单和商品之间的关系,包括将商品添加到订单中、更新商品数量、从订单中删除商品等操作。这样,在订单和商品之间就形成了一种聚合关系,订单作为聚合根来管理商品,确保了订单和商品之间的一致性和完整性。
例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 public class Order { private List<OrderItem> items; public void addItem (Product product, int quantity) { boolean productExists = items.stream() .anyMatch(item -> item.getProduct().equals(product)); if (productExists) { items.stream() .filter(item -> item.getProduct().equals(product)) .forEach(item -> item.setQuantity(item.getQuantity() + quantity)); } else { OrderItem item = new OrderItem (product, quantity); items.add(item); } } public void removeItem (Product product) { items.removeIf(item -> item.getProduct().equals(product)); } public double getTotalPrice () { return items.stream() .mapToDouble(item -> item.getProduct().getPrice() * item.getQuantity()) .sum(); } } public class OrderItem { private Product product; private int quantity; public OrderItem (Product product, int quantity) { this .product = product; this .quantity = quantity; } public Product getProduct () { return product; } public void setProduct (Product product) { this .product = product; } public int getQuantity () { return quantity; } public void setQuantity (int quantity) { this .quantity = quantity; } } public class Product { private String name; private double price; public Product (String name, double price) { this .name = name; this .price = price; } public String getName () { return name; } public void setName (String name) { this .name = name; } public double getPrice () { return price; } public void setPrice (double price) { this .price = price; } }
那为什么不可以把商品作为聚合根,订单作为聚合中的子对象呢?
因为一个聚合根应该是具有独立性的实体,可以独立地存在和修改,同时又可以包含其他实体。在这个例子中,商品和订单之间是一个典型的“一对多”的关系,因此更适合将订单作为聚合根,商品作为聚合中的子对象。理由如下:
首先,订单是整个业务的核心实体,所有商品都是基于订单创建的。订单作为聚合根,可以控制整个业务的流程和生命周期,例如订单的创建、修改、支付、发货等等。而商品只是订单的一个组成部分,相对来说具有较低的独立性。
其次,将商品作为聚合根的话,就需要考虑如何处理订单和商品之间的关联关系。如果一个订单中包含多个商品,那么在创建订单时就需要同时创建多个商品,并且需要将商品和订单之间的关联关系保存到数据库中。这样会增加代码的复杂度和维护成本。
综上所述,将订单作为聚合根,商品作为聚合中的子对象更符合业务逻辑,并且更容易实现。
假如我的service层已经有超级多的业务处理方法了, 我怎么安排DDD领域模型的重构呢,
如果你的service层已经有了很多业务处理方法,那么建议你先把这些方法按照领域进行分类,然后针对每个领域设计对应的领域模型。在设计领域模型时,建议首先从核心业务领域开始,逐步扩展到其他相关领域。设计领域模型需要遵循一些原则,例如领域模型应该是领域专家(Domain Expert)来设计的,而不是开发人员,因为领域专家最了解业务领域的需求和规则;领域模型应该是基于业务行为(Behavior)和概念(Concept)而不是技术实现来设计的;领域模型应该是可维护和可扩展的。
在设计完领域模型之后,你需要把原来的业务逻辑代码逐步迁移到领域对象中。在迁移过程中,你需要保证原有的业务逻辑不受影响,并且保持代码的可测试性和可维护性。如果你的领域对象设计得合理,那么你可以通过领域对象的行为来替代原有的业务逻辑代码,使得你的业务逻辑代码更加清晰、易于维护。
需要注意的是,在进行DDD领域模型的重构时,要保证代码的向后兼容性,尽量减少对原有业务逻辑代码的修改。可以通过引入适配器(Adapter)来实现领域对象和原有业务逻辑代码之间的转换。另外,也要考虑到领域对象之间的交互问题,如何保证领域对象之间的协作和协调也是需要考虑的问题。
向chatGpt的提问:


/1711294121143.png)
/1711294137319.png)
/1711294218431.png)