重读了一遍《深入理解java虚拟机》, 发现第一遍读类文件相关内容的时候,真的是囫囵吞枣,很多细节都被我跳过了,无论是符号引用的含义,还是属性表的理解,都没有弄懂,当时想着“反正也用不到,跳过吧”,却没注意到他们包含了许多java底层实现的核心原理。
看来经典书籍要多读多总结,是有道理的。
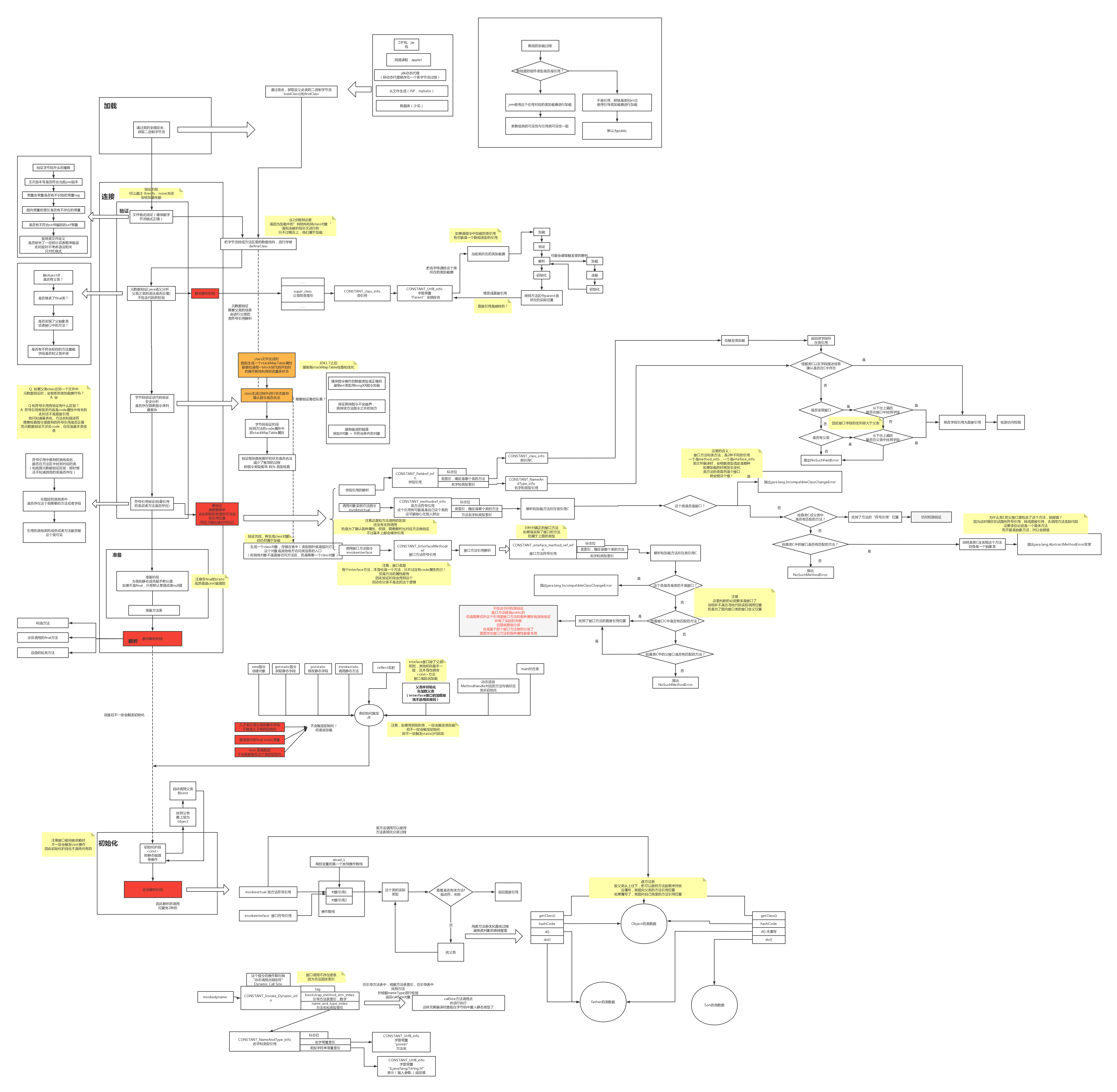
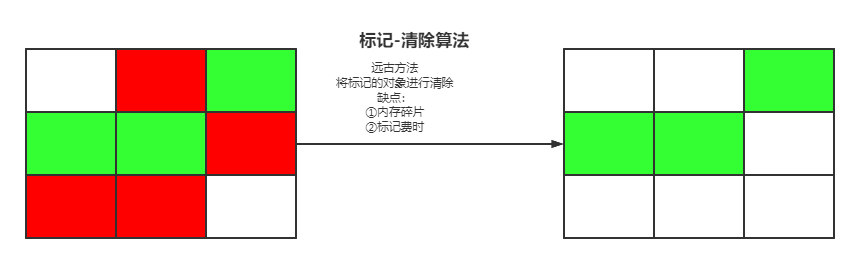
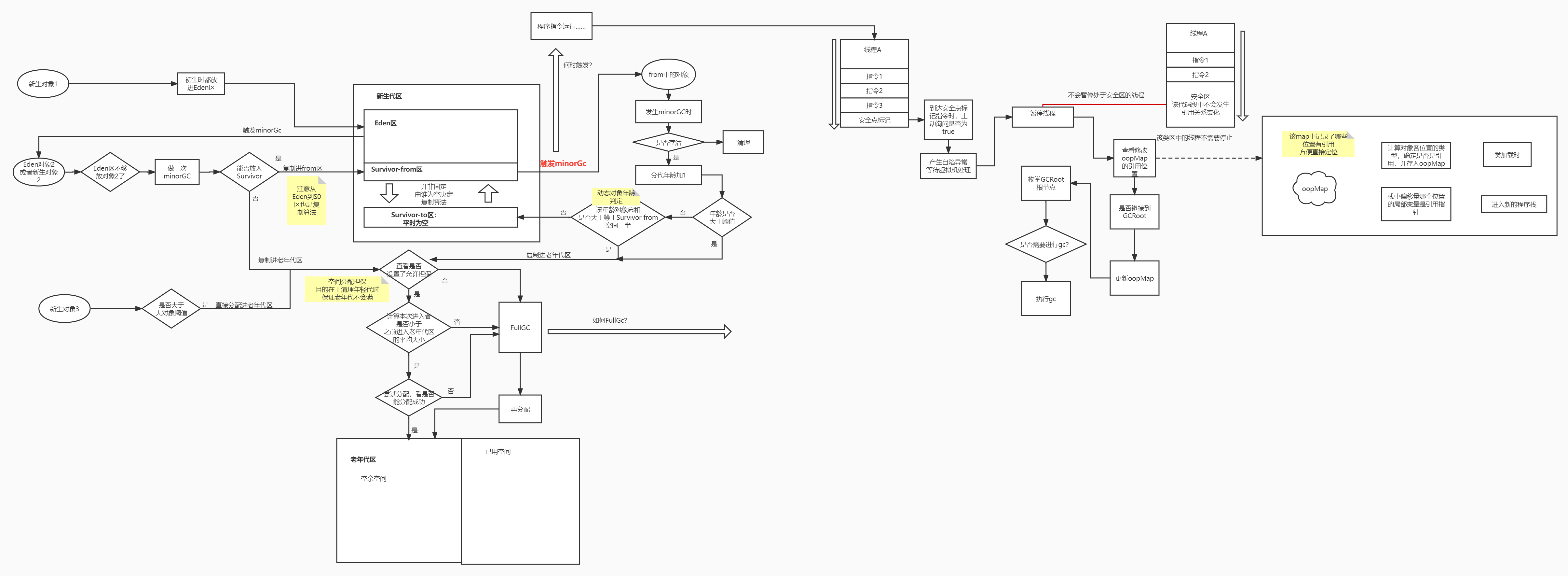
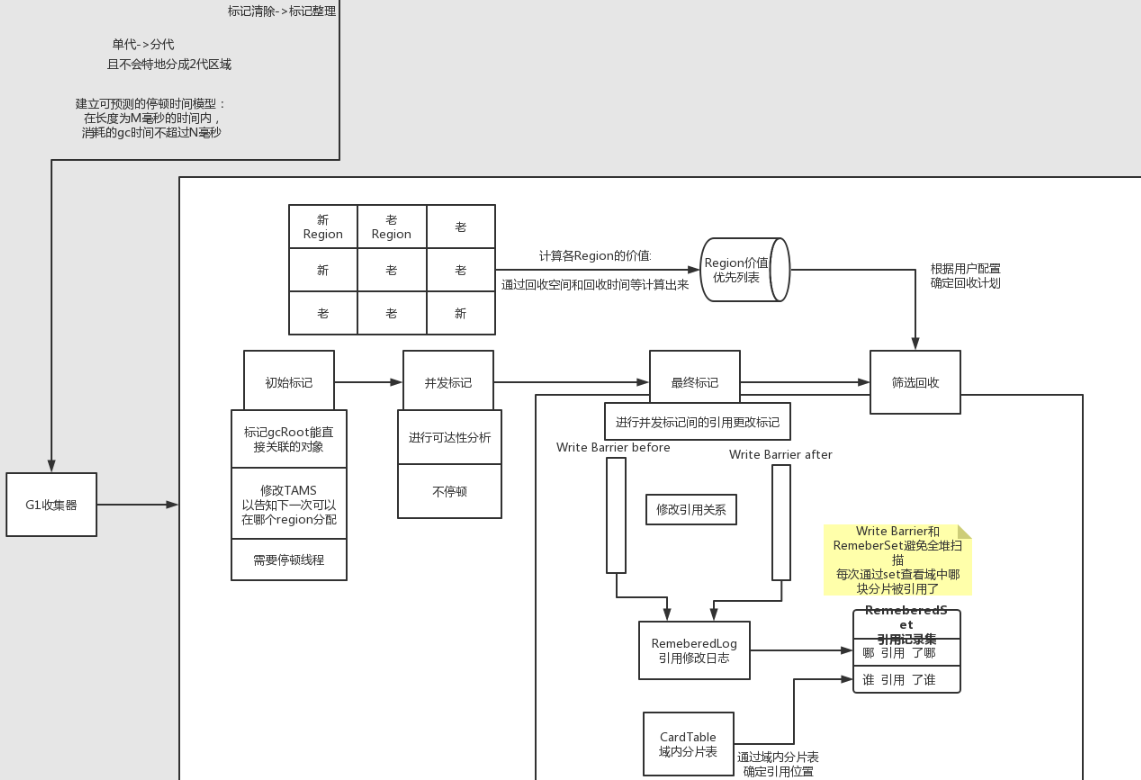
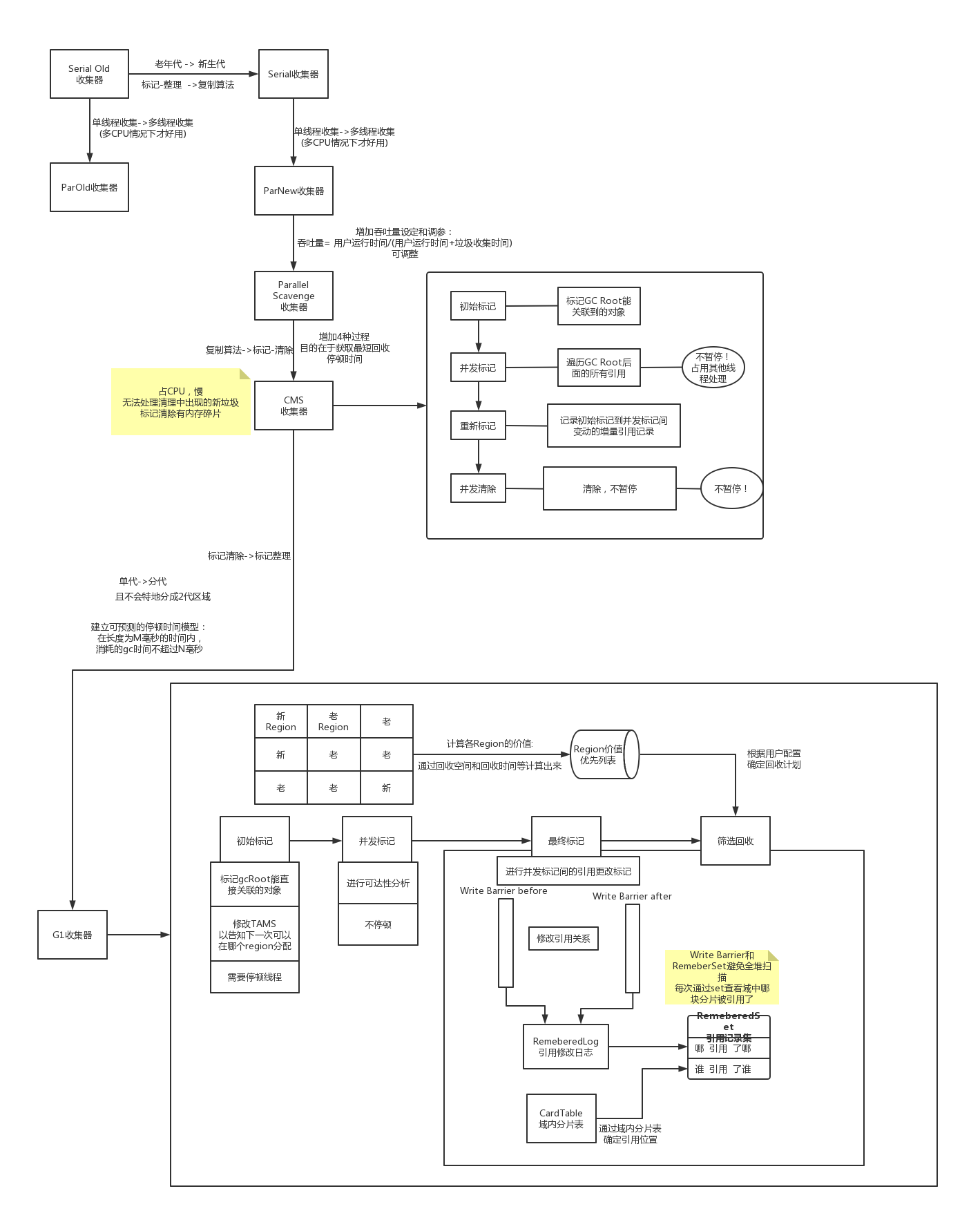
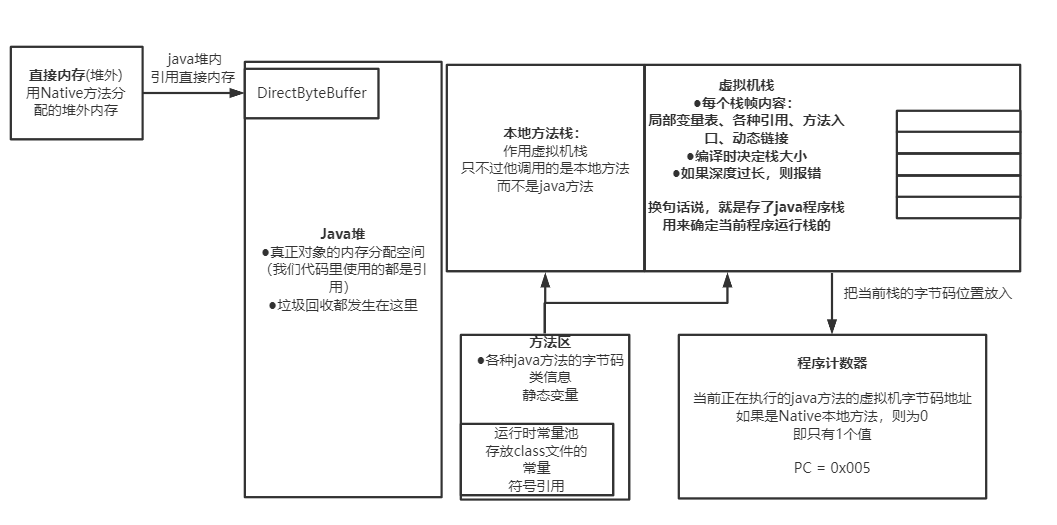
于是在阅读这个章节时,用processorOn做了一副超大的类文件解析图,方便自己通过浏览这个图能马上回忆起class文件的结构以及内部的指令。
下面的内容是拆分后的内容,对于每块拆分的内容,会有详细的解释。
对于完整大图,我放在文末,需要收藏的可以自取
好了下面我们开始,文章内容较长,建议收藏一下分时段阅读。
[toc]
魔数、版本号#

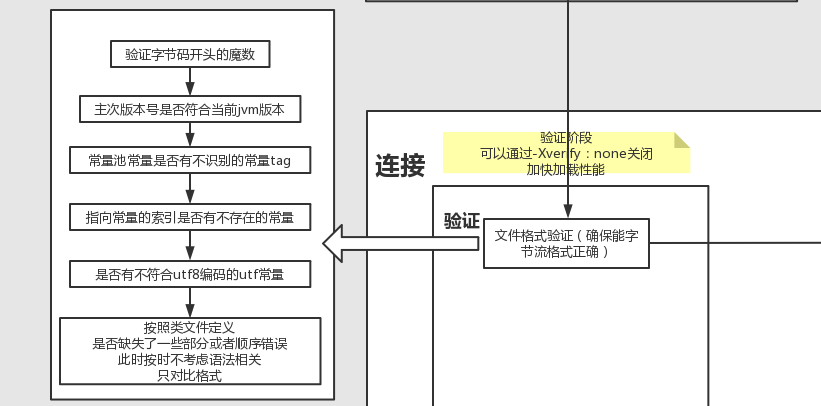
- 每类文件都有一个魔数,用于快速校验文件类型。
- 对于高低版本号,只要明确java11\java8这种版本是主版本号
- 永远向下兼容, 即高版本jvm可以读取低版本的class文件, 但是低版本的jvm无法读取高版本的class文件。
常量池(常量池个数、多个常量项)#
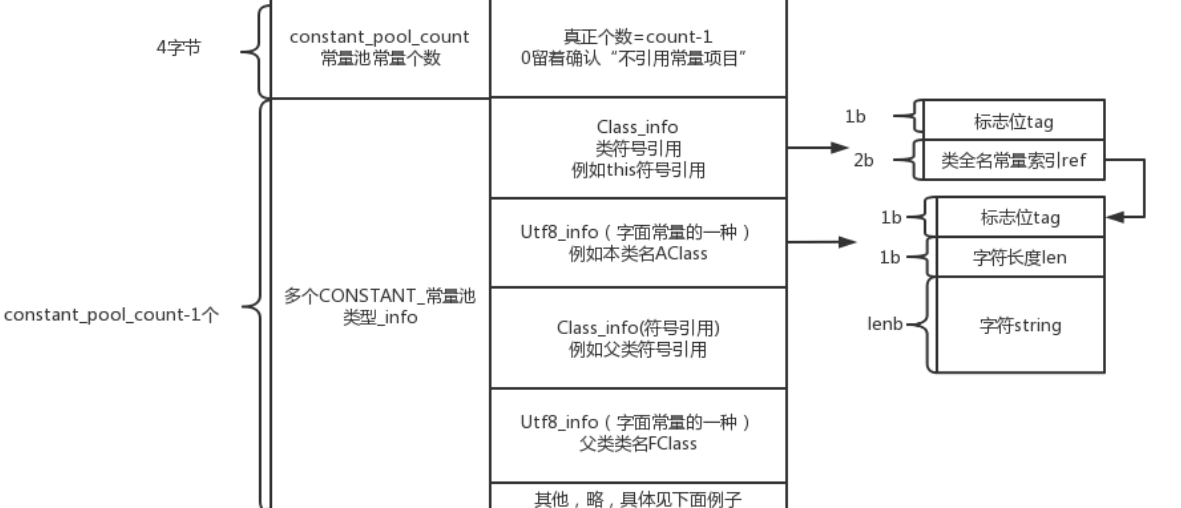
大部分文件协议格式中,都会先给定一个某项的数量长度,再决定某项的个数,方便确认遍历几次才结束。常量池的设置也是这个原理。
因此学习java的class格式,对我们设计某些文件格式或者协议都是一种不错的借鉴。
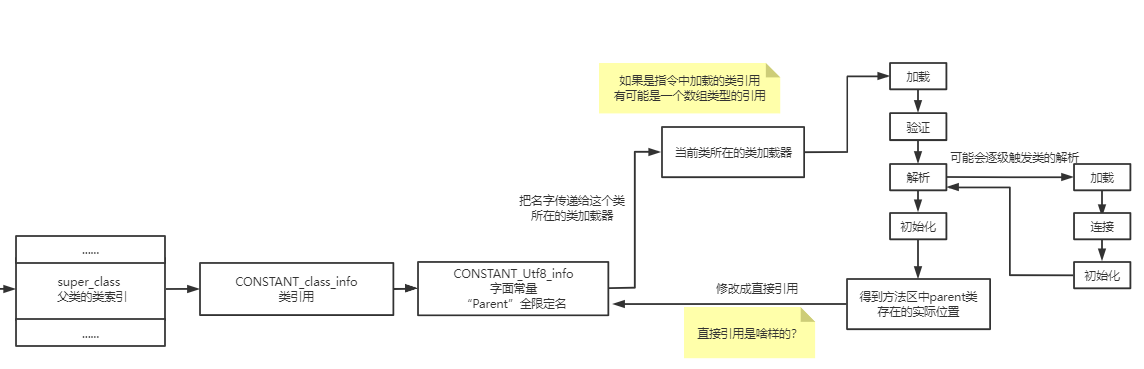
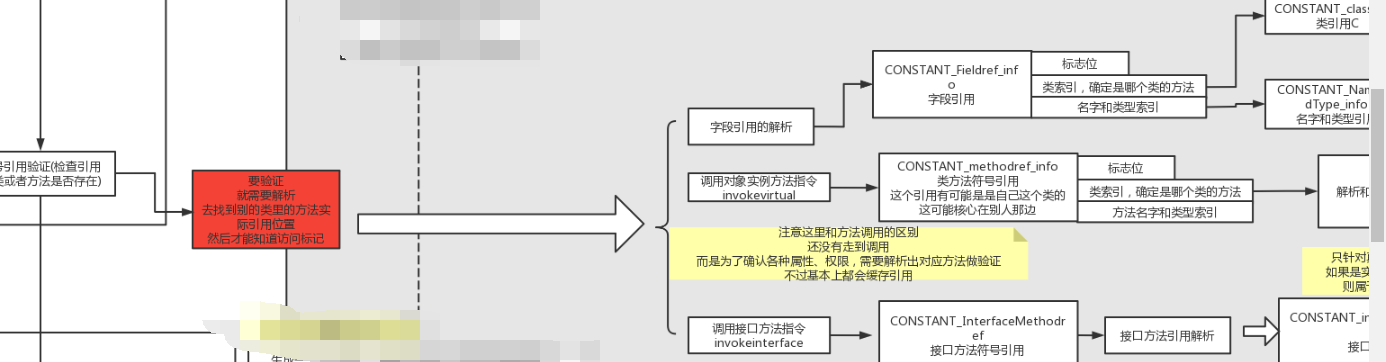
常量池中的常量到底是干嘛的?和我们理解的static final String xxx常量是一个意思吗?#
不对!代码中定义的final类型字符串常量只是一种用途。更重要的一种用途是符号引用。
而对符号引用的理解,是对java类文件原理最难也最重要的地方。
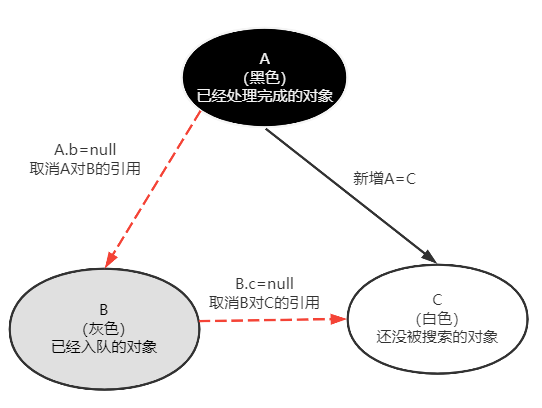
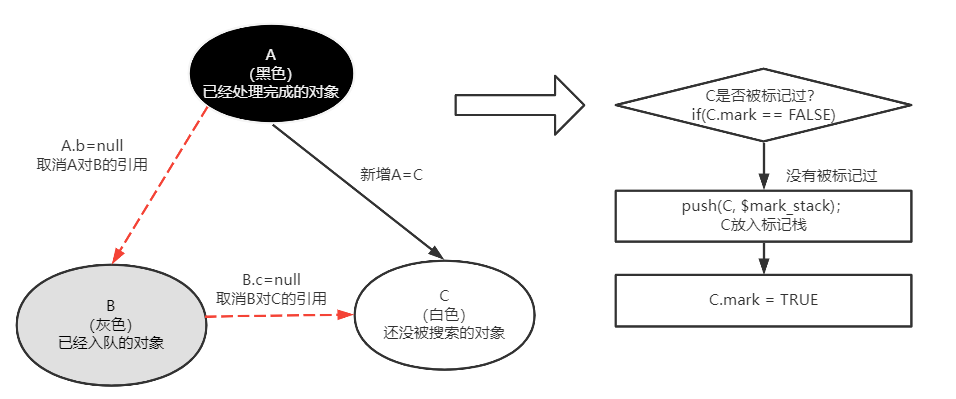
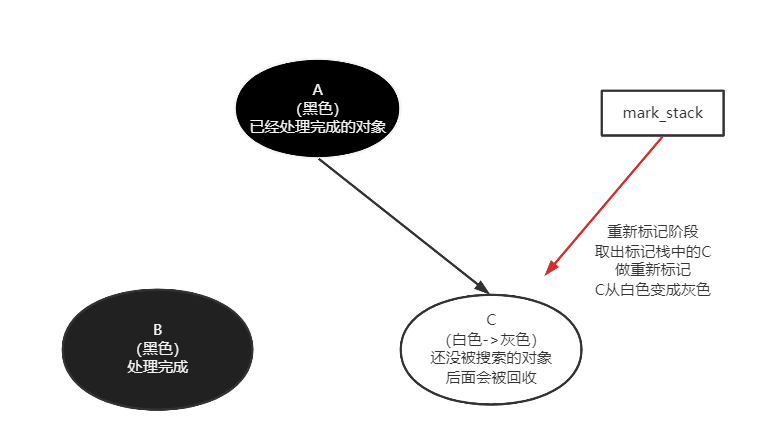
直接去解释符号引用的话,还是很难理解的,因此我们按下不表,在第4部分“类索引”部分会给出详细解释。
常量池的索引计数为什么从1开始(即其他地方要使用常量池的第一个常量时,必须写成1而不是0)?#
因为要留一个0,表示不引用任何常量
- 举例:匿名类就是没有名字的,但是类文件结构中,类名那边总需要填入类名常量索引,因此可以填入0,表示“没有类名”的意思。
- 再来一个例子:object类,是没有父类的,所以他的父类那一栏填的常量索引也是0
- 对于常量池的作用,后面会有更详细的体现和解释。
类定义的第一行(类访问标志、本类、父类、实现接口)#
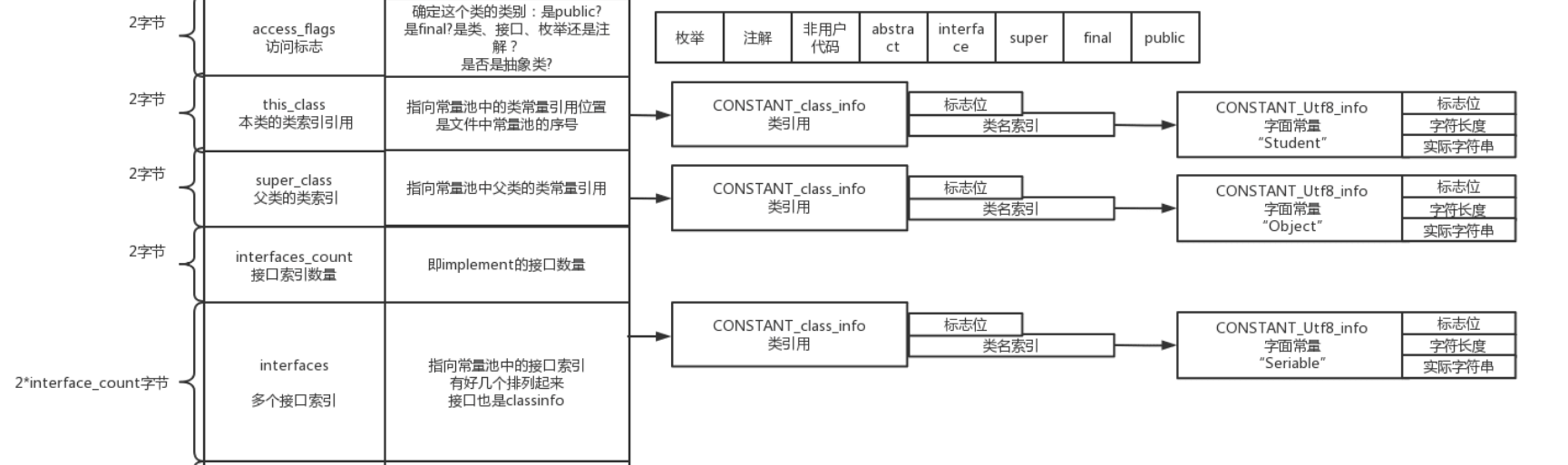
为什么叫类定义的第一行,因为这就来自我们写每个类时的第一行内容。
例如
public abstract class A extend B implement C,D
这句话对应的所有信息就包含在了上图中,因此我叫他“类定义的第一行”
CONSTANT_class_info这个类常量到底是干嘛的?
从图上可以看到,他其实就是指向了一个表示类名的字符串常量。
这里也可以看到,java文件中的所有名称例如类名、方法名、字段名,都会以Utf_info的形式,存储在常量池中。

为什么要这样多走一层?为什么不能直接指向一个字符串常量?#
这个问题我没找到解释,但可以理解为这是最基础的一层封装。

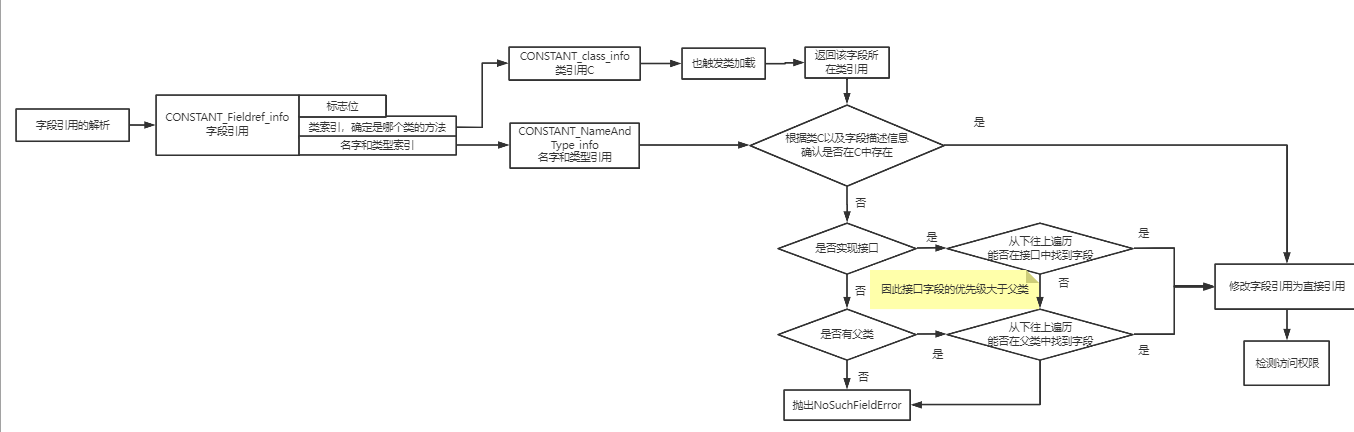
字段表(字段数量,各字段(修饰符、名、类型、属性))#
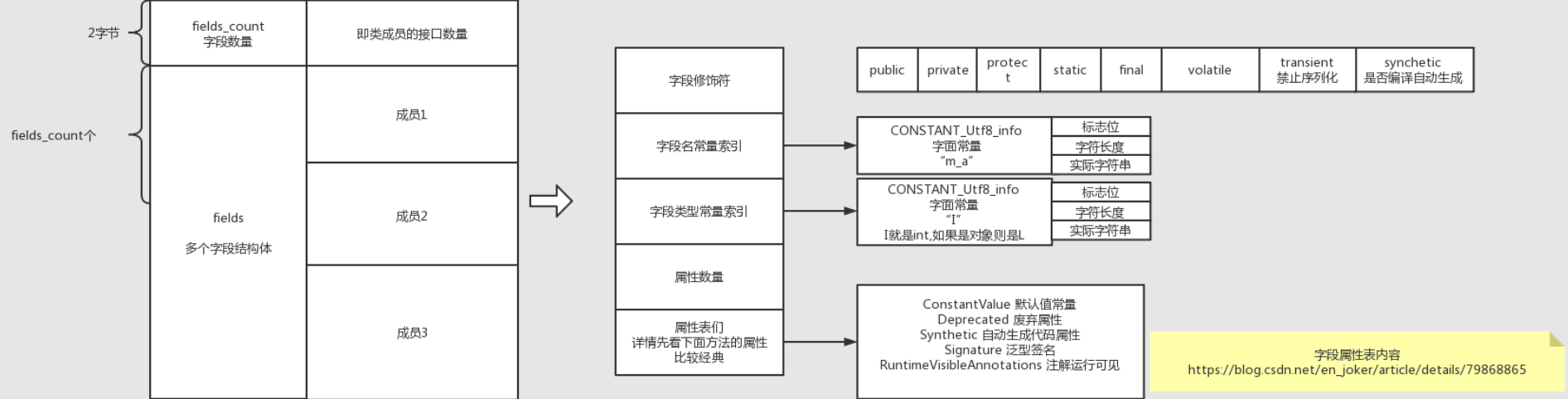
可以看到,字段名、字段类型分别对应了2个字符串常量。
特别注意字段类型使用一个字符串来表示的,而不是一个constant_field_info。
那么constant_field_info是干嘛的呢?
字段修饰符中的synchetics指的是编译器自动生成的字段,怎么理解呢?什么情况下会用到?#
找到一个简单的例子(代码出处:知乎-不凋花),用枚举做switch:
1 | enum Foobar { |
switch的原理,我们应该很容易想到,就是做一次顺序检查,那么检查时,肯定程序里需要有一个列表吧,因此上面switch的背后逻辑代码是长这样的:
1 | class Test$1 { |
可以看到有一个“static final int[] $SwitchMap$Foobar;”, 这个静态数组字段,就是编译器帮忙生成的字段,他会被标记成synchetics
上面可以看到每个字段项的最后包含属性数量和属性长度,那么class中的属性和上面的“字段名”、“字段类型”有什么区别呢?#
属性是可有可无的,而且提供了高度的“jvm可扩展性”。
换言之,在jvm虚拟机规范中,“字段修饰符”、“字段名”、“字段类型”都是必备的,而属性则没有限制。
因此我们甚至可以自己实现一个虚拟机,定义新的属性,在class中加上属性项然后自己使用
对于属性作用的更详细理解,可以看后面的方法章节,方法中的属性是比较重要且用得最多的。
从字段属性可以看到, 类似于static final int a =10这种常量,就是通过属性里的constant属性来设置的。
有个泛型签名的属性,可能不太好马上理解,后面在方法章节中会一并提到这个属性的作用!
方法表(方法数量、方法项(修饰符、名、描述、属性))#

class文件中,最值得学习的就是常量池和方法表了!
方法修饰符中的桥接#
对于方法修饰符,大部分都很好理解,有2个修饰符需要关注:“bridge”和“synthetic”。
其实很多bridge桥接方法本身也是synthetics系统生成的,所以我不太想去区分二者,只要关注他们2个用来做什么。
思考下面这个问题:
1. 假设有个非公开的类A,A中有个public方法f(),有个继承自A的公开类B,没有重写f(),那么外部是否可以调用b.f()?
1 | private static class A { |
我们很容易可以得出b.f()可以调用的结论。
但由于B没有重写f(), 所以对于编译后的B.class而言,这意味着不会在class文件中包含f方法。
那么当执行f时,通过多态,会定位到A.f(),此时A是非公开的类,权限就会出错,因为不允许直接引用非公开的类的方法,只能间接使用。
如何解决?要修改多态的动态分派校验机制吗?
不需要,编译器为了方便,直接为我们在B中重写了f()来间接调用父类方法,类似于
1 | public void f() { |
这样的话就不用担心外部调用者没有权限使用A.f()了。
2. 有个泛型基类Base<T>,包含一个方法f(T t), 有个子类Sub<String>, 实现了方法f(String s), 两个f方法的入参并不一致,为什么还多态的机制还能生效?
1 | class Base<T> { |
这2个方法的入参确实不同, 前者的方法签名是f(Ljava/lang/Object;)V, 后者是f(Ljava/lang/String;)V。 多态(动态分派)的规则也没有变,确实是要求入参一致。
因此编译器为Sub类自动生成了一个f(Ljava/lang/Object;)V,代码如下:
1 | public void f(Object o) { |
这样多态的机制也能实现了。
可以看到这一切都是为了适配多态,同时避免过多的特殊逻辑,因此使用桥接方法,来生成了我们看不到的重写方法
从下面可以看到, 方法描述符是一个**包含“入参和返回值”**的描述符

因此,java是允许 同入参、同方法名、不同返回值的方法存在于同一个class文件中的。
这是不是有点反常识?这种情况我们好像编写不出来的,编译器不会通过!
其实这也是桥接+自动生成才会有这种情况。
前文的泛型例子,用泛型T做入参,会生成一个桥接方法,和父类的匹配。
那么如果泛型T是一个返回值呢:
1 | class Base<T> { |
那么也是一样的道理,桥接了一个父类的f方法,但仅仅是返回值不同而已。所以会出现只有返回值不同的方法。
方法表的属性和字段的属性类似, 也是属性数量 + N个属性项。
但是方法表属性里的干货就更多了!
属性的结构#
之前字段属性中没提到属性到底长啥样,以方法中的throws异常属性为例,:
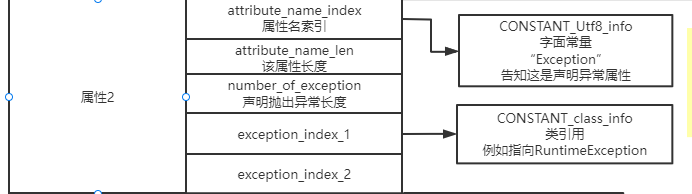
从这里可以看到,每个属性都有个属性名,和常量不同,区分不同常量用的是1个2字节的数字,而属性则是用一个字符串来表示。
这样的区别就是因为常量个数有限,而属性为了扩展性,不能存在数量限制。
另外从这也可以知道, 我们在方法名上写的f() throws IOException 都是存在于异常属性中的。
最关键的Code属性#
Code属性是方法属性中最最最重要的属性。
他告诉我们编译器是怎样将我们的文本代码封装成一个class文件的。
首先,code属性的属性名就是一个“Code”

操作数栈、局部变量表大小、指令码数量#
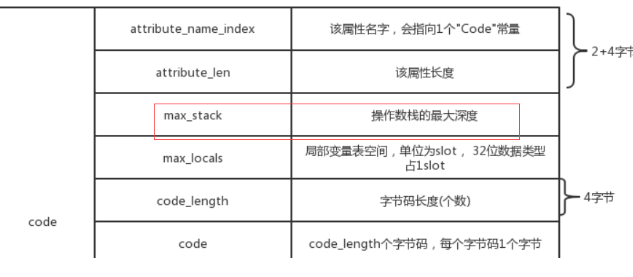
接着会包含3个重要的内容:max_stack、max_local和code_length

从max_stack和max_local我们可以看到,操作数栈和局部变量表的大小,已经在class文件中计算出来了,因此当开辟一个新的栈帧时,jvm便能够知道给这个方法开辟多大的空间,不用担心栈上分配不够的问题。
注意,是操作数栈的大小,而不是程序执行的栈的深度,程序可没法感知我们能够递归多少次。
指令码解读#
code_length代表了我们这个方法在编译后,有多少条字节码指令,而后面紧跟着的,就是对应数量的java字节码指令了。
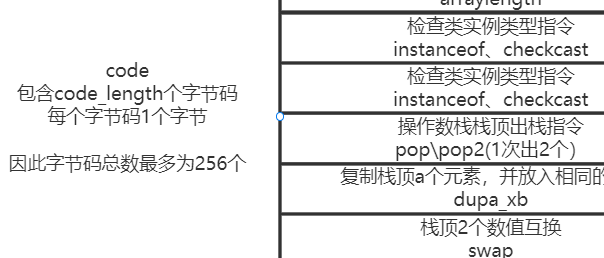
指令码种类非常多,这里只列举关键的一些信息。
数据计算用的指令码#
首先,每种涉及基本数据类型的计算指令,都会在指令最前方,携带一个T,如图:

里面有句话:“不是每种数据类型和每个操作都有指令对应(否则数量太多)”
这句话怎么理解呢,可以结果图上右侧的表格,从而得知,有些指令是不包含所有类型的,所以可能会借用一些的技巧,比如把byte、short都视为int在操作上去操作。
对象操作的指令码#
另一个类指令码是和对象操作有关,例如:
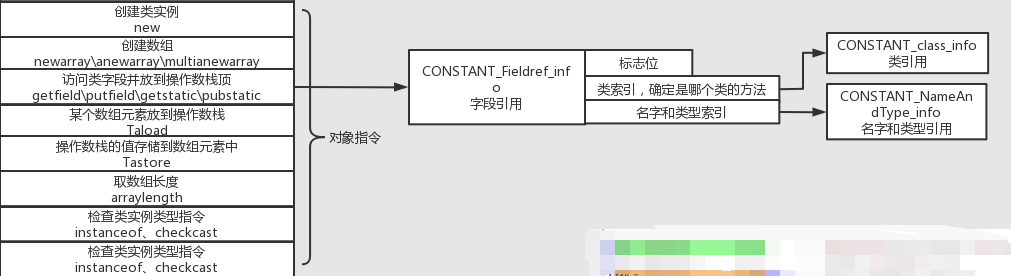
可以看到,当试图获取一个类字段时,他指向的是一个class_field_info常量索引,这个常量会提前被放进class文件的常量池中。
为什么对象操作指令码中只包含了类引用和名称呢,我怎么知道我调用的是哪个对象的字段?#
A: 你要调用的对象,已经通过前面提到的操作数栈相关指令,把引用放到了操作数栈的第一个,因此,jvm只要取栈顶对象,然后根据名字进行字段操作即可,后面的方法调用也是一样的道理。
new对象和new数组,用的是2个不同的指令,为什么要有区分?不能把数组当成一个java对象吗#
这要从对象的内存结构,以及类加载机制上去思考。
因为数组的对象头,和普通对象的对象头是不一样的。
- 数组的对象头中包含了数组长度,而普通对象没有
- new一个数组时,数组中包含的类并不会做类加载。
有这么多区别,肯定是新增一个单独针对数组的指令来处理,要简单很多
操作数栈指令(pop等)#

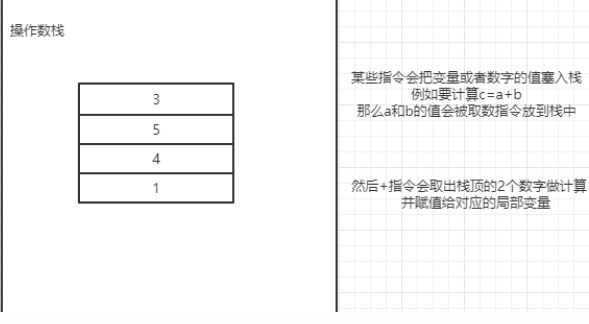
其他指令好理解, 但操作数栈指令有个dup_x指令,例如dup1_1 就是复制栈顶并再放入1个。为什么需要这么一个指令?
其实当我们调用 A a = new A()时,这一句话生成的指令中就包含了dup指令
因为当我们new出1个A引用时,它有两件事要做:
- 调用A的构造函数。
- 把引用地址赋值给a这个局部变量
而每件事都会消耗一个A的引用!所以才需要赋值。
因此可以看到,指令码很多时候都是基于操作数栈进行操作的,每操作一个数据或引用,就消耗一个
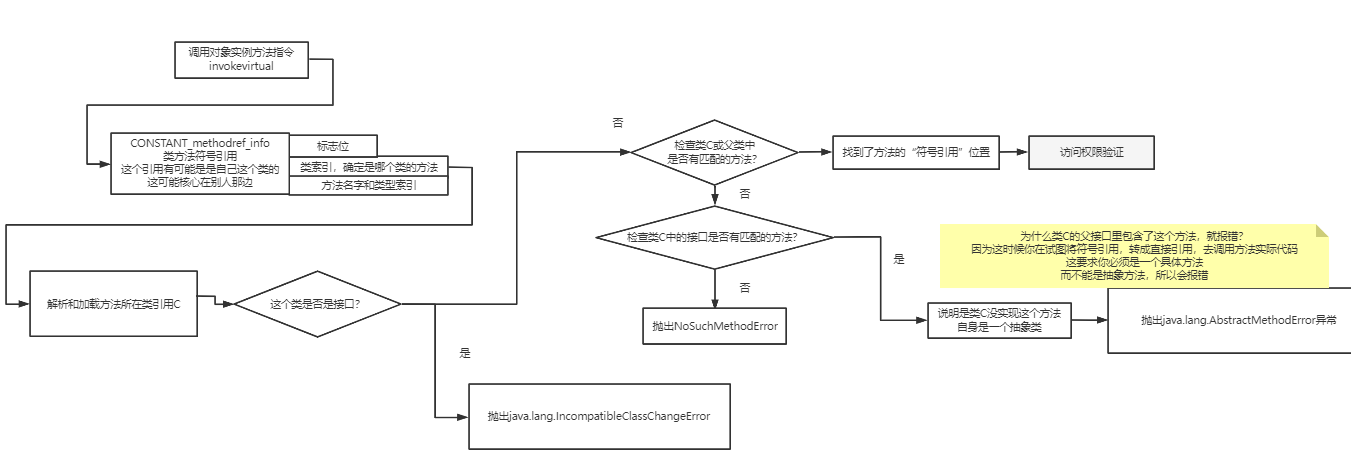
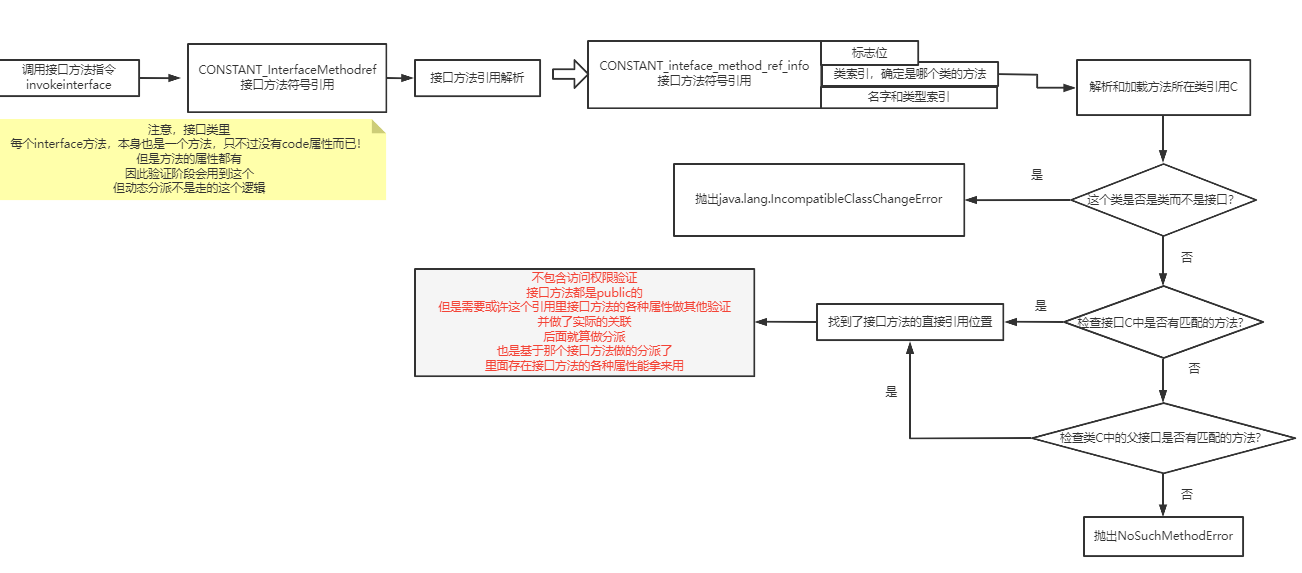
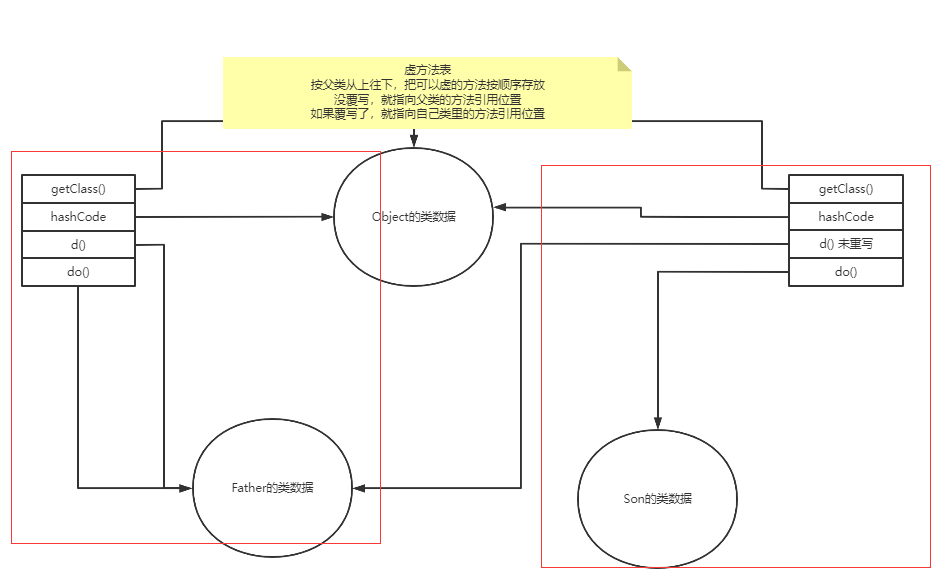
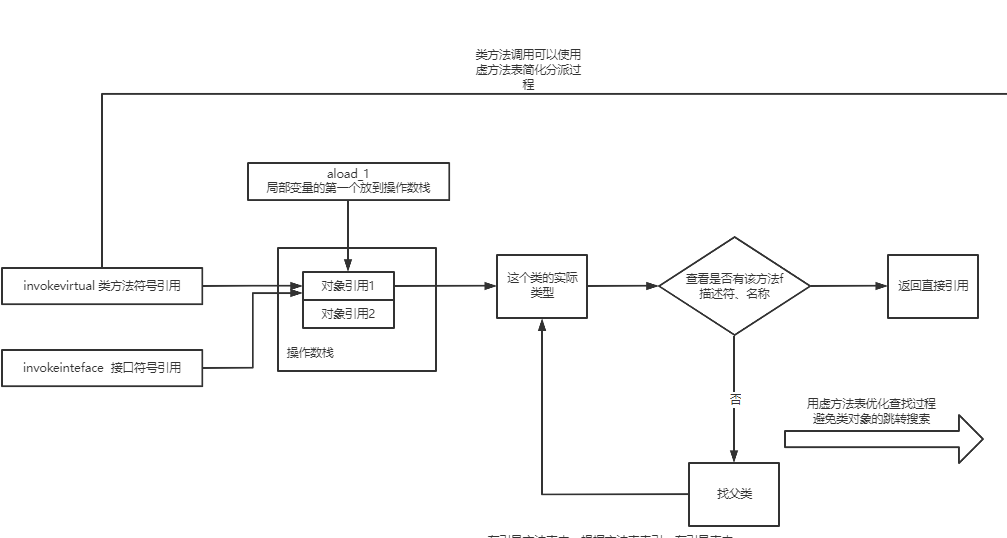
方法调用指令(invokevirtual等)#
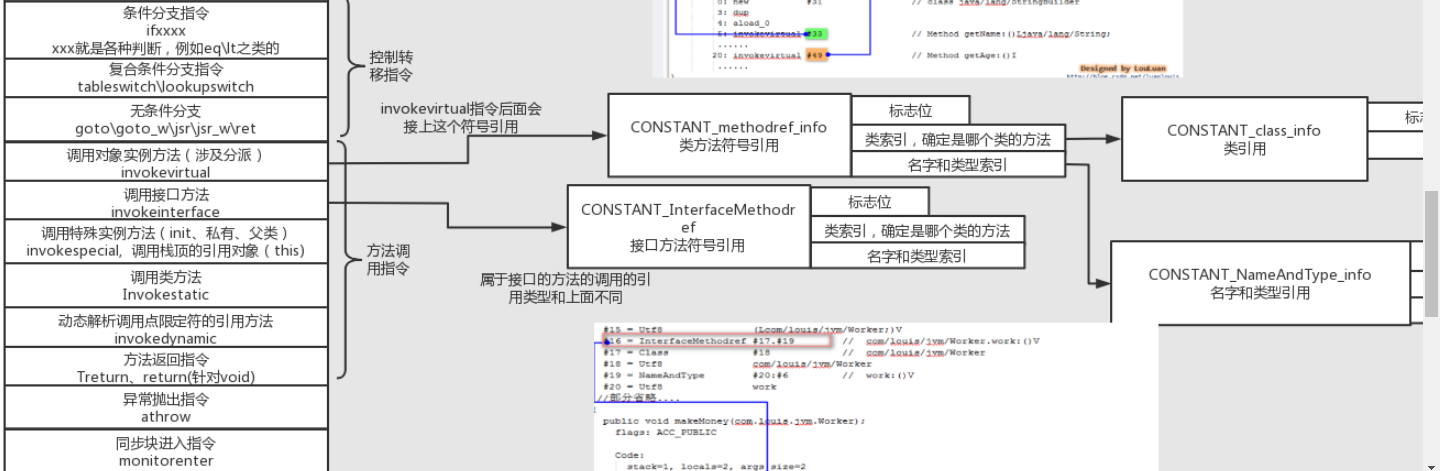
对于方法调用指令,和前面的类字段调用有点像,也是一个方法常量,方法常量包含类索引和方法描述索引。
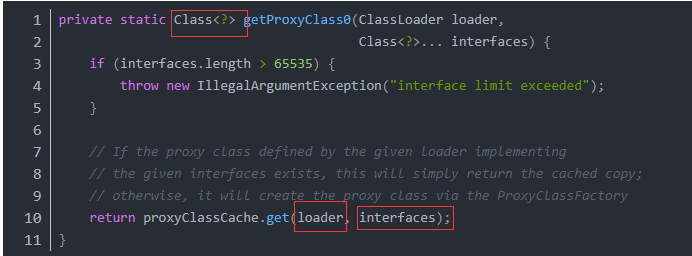
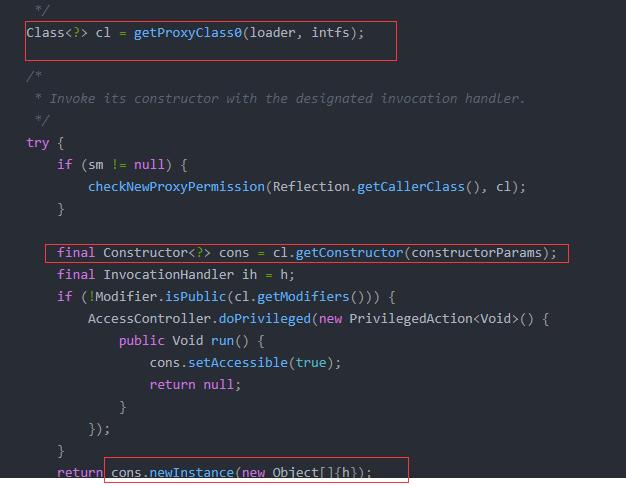
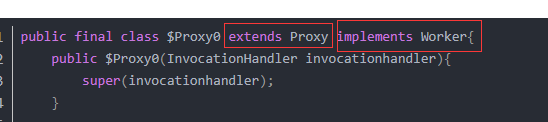
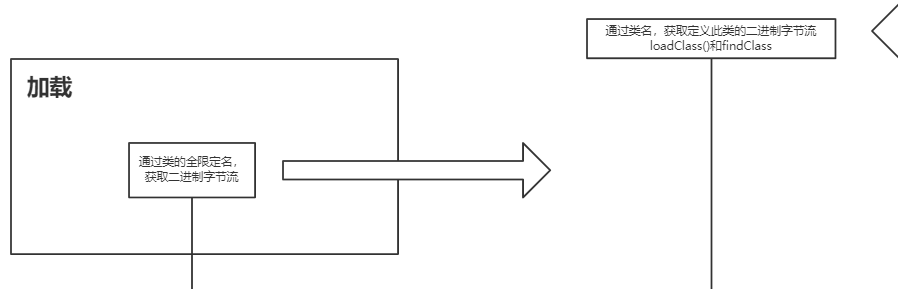
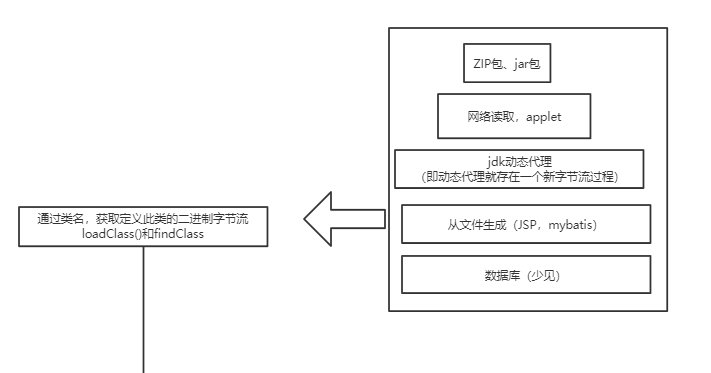
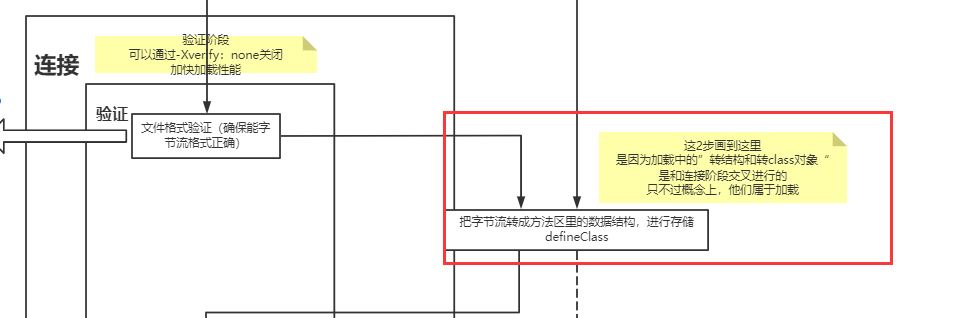
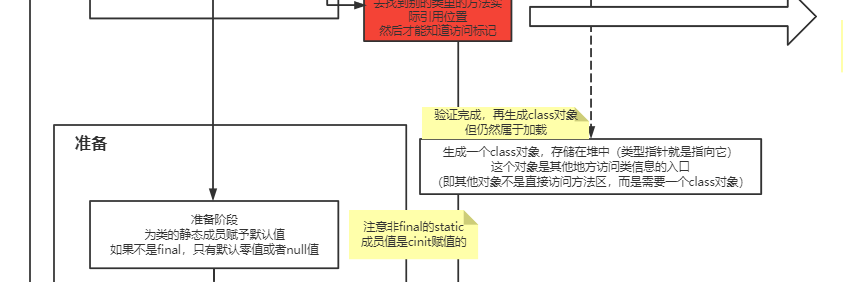
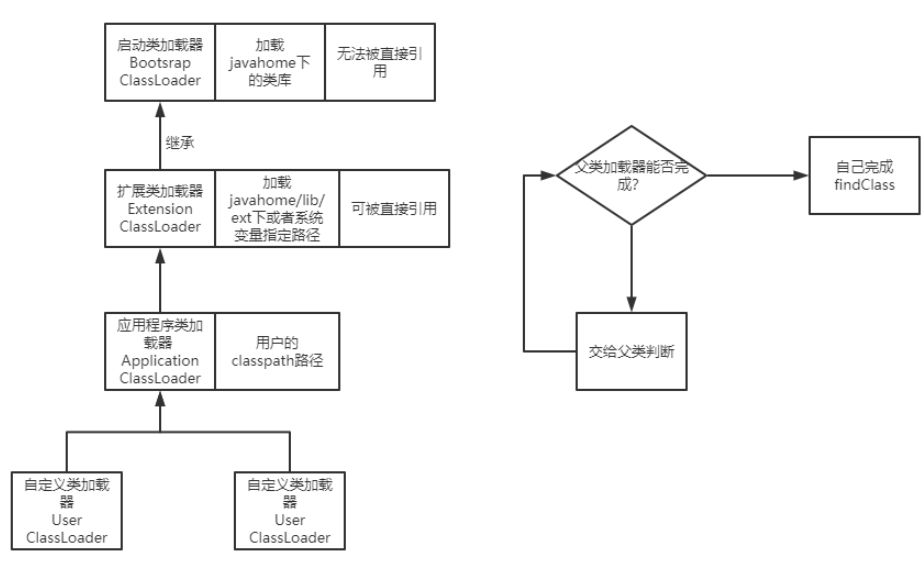
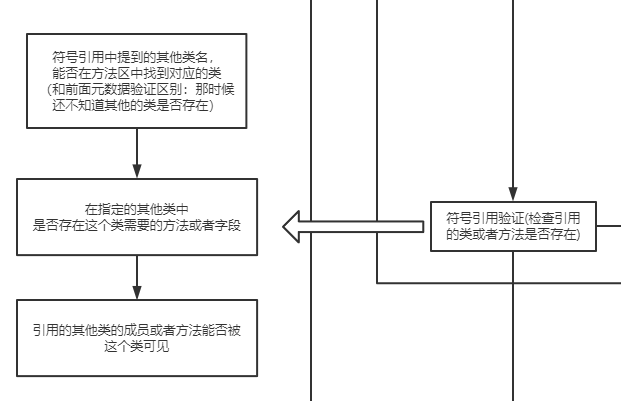
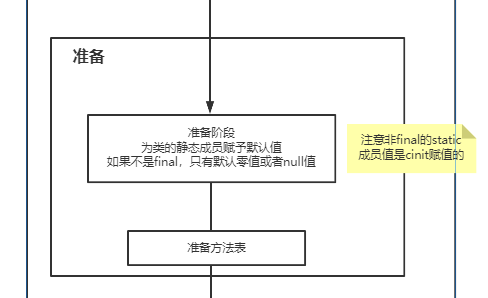
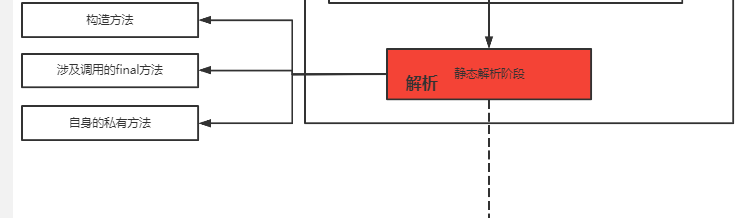
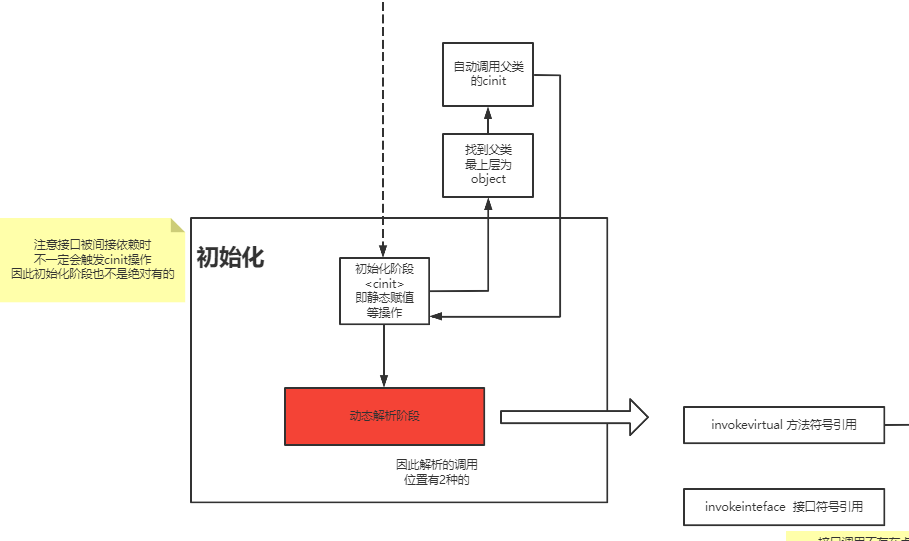
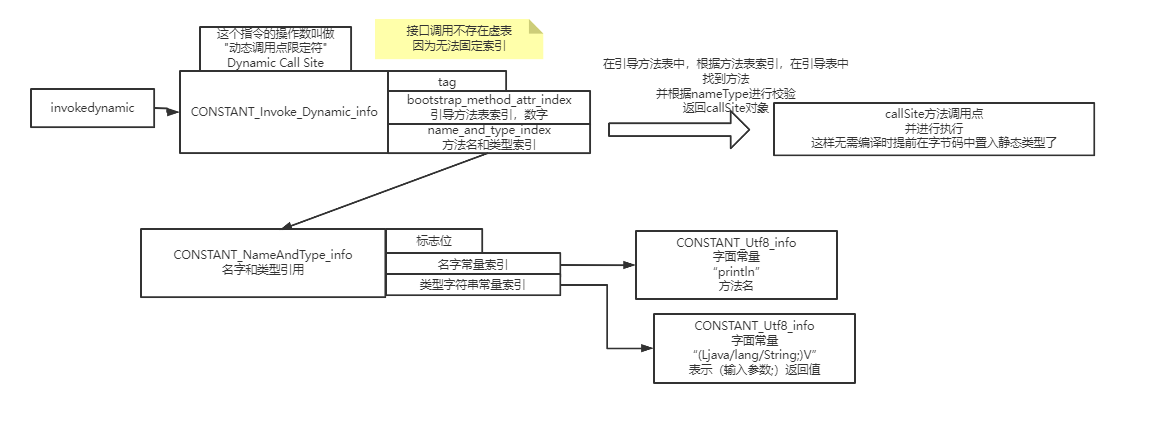
对于方法究竟是如何触发调用实现多态的、invokevirtual指令和invokedynamic指令有什么区别,这个内容就更多了,后面我会放到类加载的图解笔记中讲解。
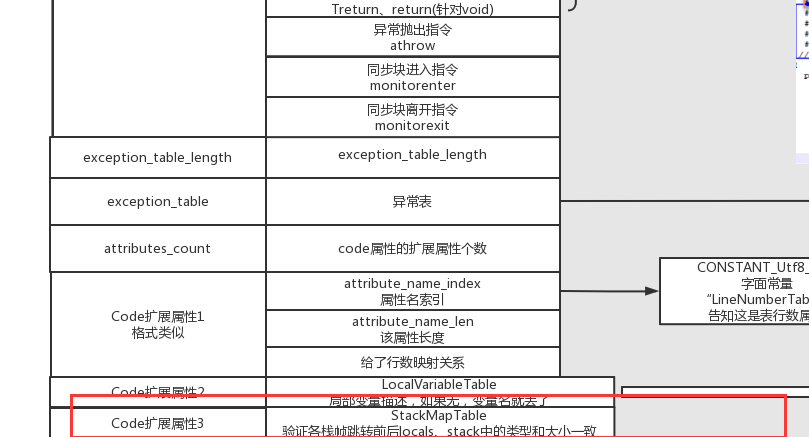
异常表属性#
指令码结束后,后面会紧跟着一个异常表。表中的每一行长这样:
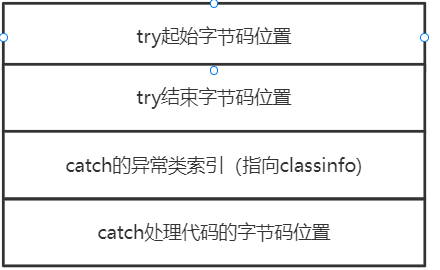
是不是恍然大悟,原来try-catch代码的逻辑在这边, 它本质上就是抛异常时,根据try的位置和异常类型,这个异常表中进行查找到对应的catch代码位置,从而实现异常处理。
那finally的操作被放到哪了?catch操作完了之后,它怎么知道要跳转到哪里?#
finally模块在java语言中是必须执行的,在编译的时候,通过将finally中代码块分别在try模块的最后和catch模块的最后都复制了一份,通过这样来保证finally的必定执行
对于synchronized关键字,它本质是生成了monitorenter和monitorexit两个指令(上面方法调用指令里的最后2个)。但如果发生了异常,那会不会无法monitorexit了?#
生成code字节码时,jvm会自动为synchronized生成1个默认的异常表和throw指令,保证中间同步块发生异常时,monitorexit能够正确被指令(类似于放了一个自动生成的try-catch代码,或者在已有的catch操作后添加)。
前面提到方法属性中,已经有一个名叫“Exception”的属性,和这个code属性中的异常表有什么区别?#
上面code异常表指的是代码执行时try-catch的逻辑部分
而方法中的exception属性则是方法名上所声明的throws异常。
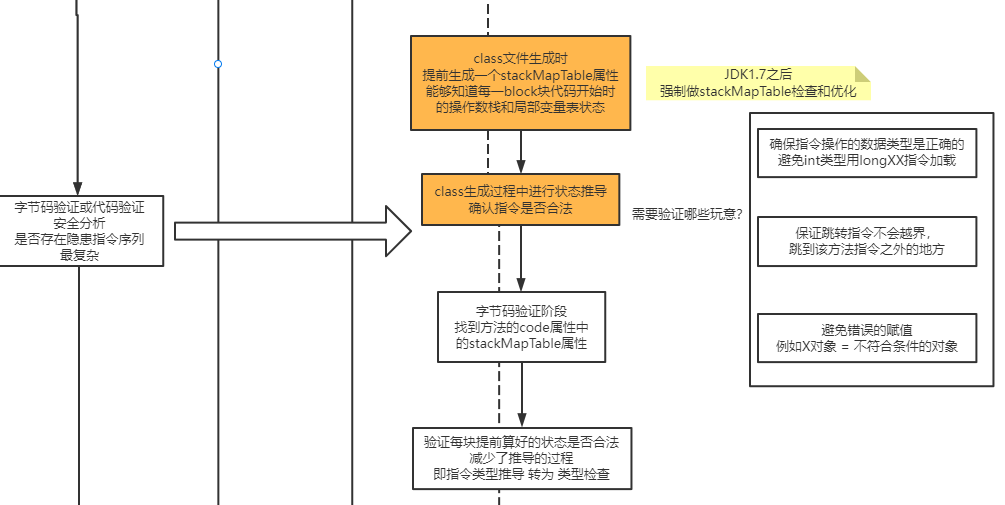
Code的扩展属性#
在code属性中,竟然还携带了属性,也就是说,是允许“属性中的属性”。毕竟属性的实现是可以完全自定义的,那么自己给自己新增额外特性完全是允许的。
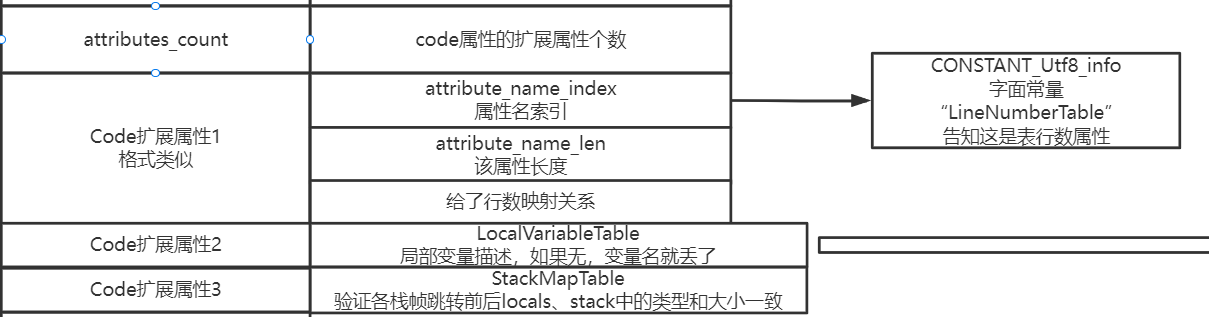
里面有个属性叫“局部变量描述属性”,长这样:
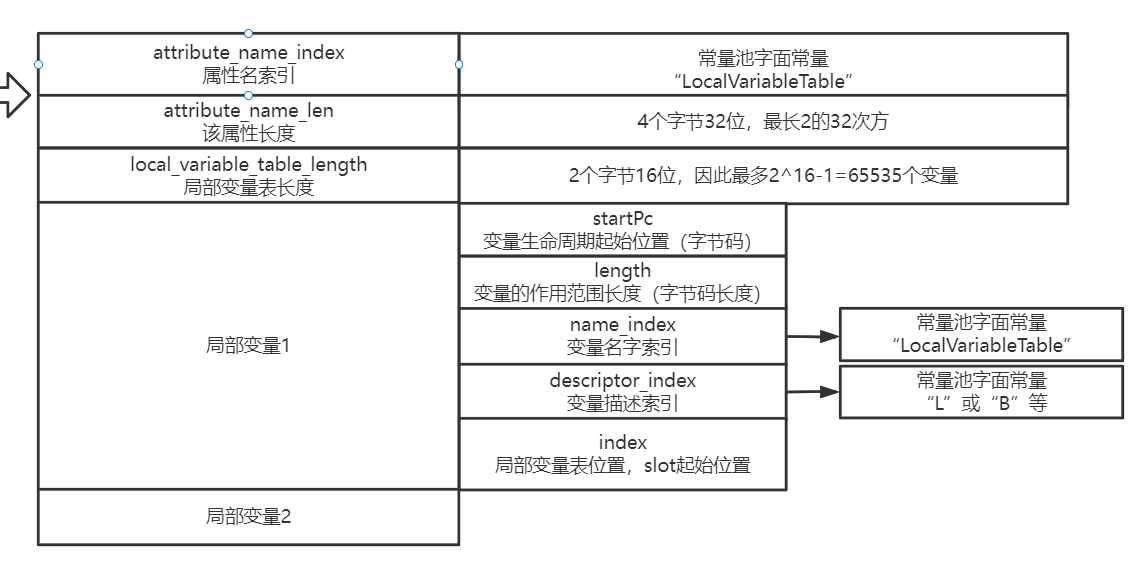
从这里,你就能明白,为什么你从IDEA里看到反解后的class文件,有时候是var1、var2之类莫名其妙的局部变量,有时候却又能看到完整的变量名了吧?就是通过这个属性决定的。毕竟存储局部变量名的代价还是很高的。
其他的方法属性#
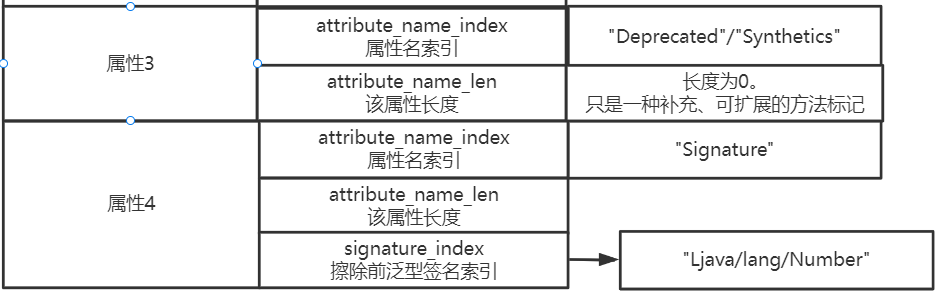
泛型签名这个属性很迷惑,不是有泛型擦除吗,为什么还需要这个属性?
其实泛型签名属性是为了方便反射的。
我们通过前面关于桥接的原理,可以知道编译时会发生泛型擦除,方法入参都变成了object。
但是反射API可能希望获取泛型信息因此可通过这个扩展属性进行获取。所以会增加这个属性,从而能感知一些泛型属性相关的信息。
类属性#
既然方法和字段都有属性,那么类肯定也有属性:
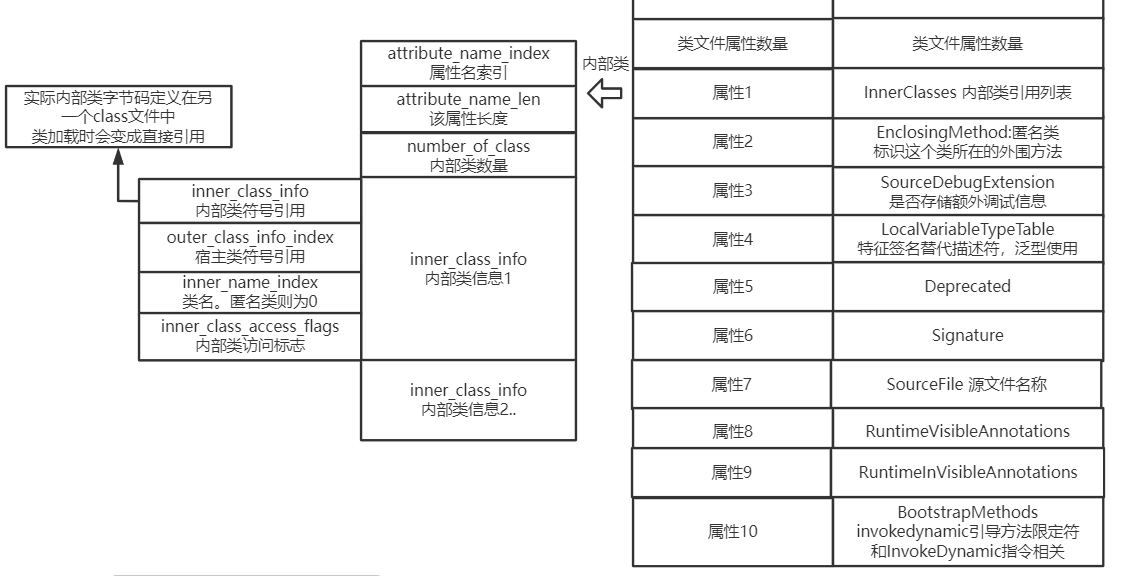
其他属性都比较好理解或者不重要,重点讲一下内部类属性。
通过内部类属性,我们可以看到内部类并不是直接包含在这个class文件中,它其实是生成了另一个class文件,所以才需要一个内部类属性,来确认对应的名字,方便类加载时能找到内部类。
为什么内部类属性中,要包含宿主类的类名?难道宿主类,不就是它本身吗?#
因为,内部类中,还可以继续定义内部类
另外,从上面的一些属性中可以看到, 很多debug用的调试、展示信息,都会包含在class中
因此,当我们希望调试一些环境上执行的程序时,如果想提供最为贴近原代码,那就需要class文件中能有充足的信息,如果想要class文件小,那就去掉,具体怎么去掉或者添加,肯定就是一些编译选项的区别了。
最后的完整图#
好累,终于写完了,感觉能看到最后的人不会太多,但一通详细地分析和解决中间发现的问题,还是收获了不少。
最后贴上完整的大图,欢迎保存和收藏。
图片在线查看
https://www.processon.com/view/link/5d1a2d97e4b07c7231731b02