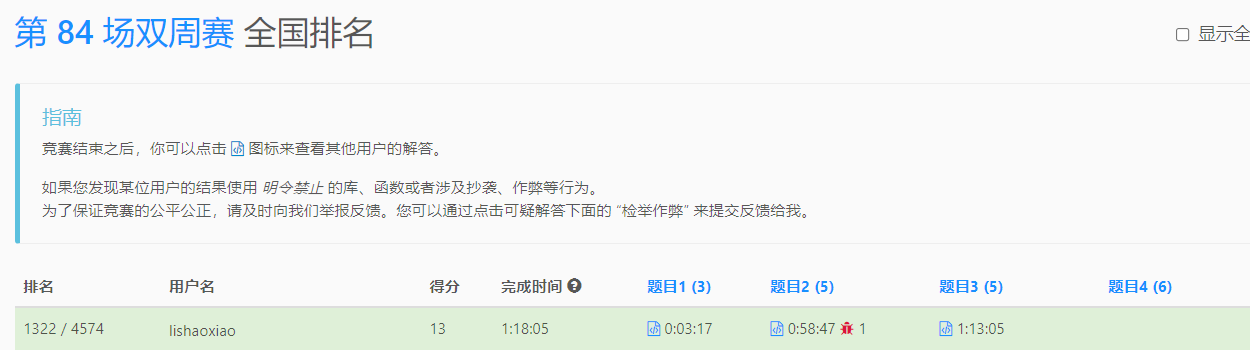
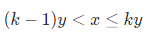22年8月刷题日记(0730-0817) [toc]
2022-07-30 1175. 质数排列 - 力扣(LeetCode)
简单,题意理解了就好, 排列组合的数学应用
1221. 分割平衡字符串 - 力扣(LeetCode)
简单,推导出贪心规律,从左到右只要符合平衡,就一定可以从更大的平衡串中拆掉
1290. 二进制链表转整数 - 力扣(LeetCode)
“111011011”这种二进制字符串如何快速转int整数?
可以用
1 Integer.parseInt("111011011", 2)
2指代二进制
2022-07-29 593. 有效的正方形 - 力扣(LeetCode)
如何用4个点判断是否是一个正方形?
方法1: 设置顺时针点为1->2->3->4,然后根据边长相同、22边平行、勾股定理3者判断是否为正方形。
1->2->3->4点的判定先根据横坐标最小,再根据纵坐标最小。
方法二:正方形的任意3个点都是等边直角三角形,判断4次即可,注意额外加一个三角形中边的判断
1 2 3 4 long len = -1 ; public boolean validSquare (int [] a, int [] b, int [] c, int [] d) { return calc(a, b, c) && calc(a, b, d) && calc(a, c, d) && calc(b, c, d); }
1642. 可以到达的最远建筑 - 力扣(LeetCode)
简单贪心题。
注意PriorityQueue默认小顶堆
1285. 找到连续区间的开始和结束数字 - 力扣(LeetCode)
row_number() over() 指每一行在整个表分区中的序号
over()是窗口函数,不会做汇聚动作,因此行数不会发生变化。只会给出每一行所处分区的某个特定值(例如各分区的和 sum over(PARTITION by xxx))
id - row_number() over() diff 外层套一个group by diff可以用来求解连续区间的问题
2022-08-01 剑指 Offer II 082. 含有重复元素集合的组合 - 力扣(LeetCode)
dfs全排列搜索问题且要求不能重复,关键语句就是”预处理排序。选的时候前一位相同,则必须是连续选的情况,不可以前面的相同数字还没选,却选了自己“
1 2 3 if (i-1 >= 0 && nums[i-1 ] == nums[i] && lastIndex != i-1 ) { continue ; }
list.remove(int) 就是按索引移除。 list.remove(object)是针对非int对象的
764. 最大加号标志 - 力扣(LeetCode)
2022-08-03 2265. 统计值等于子树平均值的节点数 - 力扣(LeetCode)
直接后序遍历即可
541. 反转字符串 II - 力扣(LeetCode)
翻转问题还是写一个reverse的简单方法会比较快,用stringBuilder不一定快
1 void reverse (char [] cs, int left, int right) ;
575. 分糖果 - 力扣(LeetCode)
集合应用,没啥好说的
2022-08-04 1403. 非递增顺序的最小子序列 - 力扣(LeetCode)
排序即可
1109. 航班预订统计 - 力扣(LeetCode)
将出点和入点放入数组中,出点位置+seats, 入点位置-seats即可
1115. 交替打印 FooBar - 力扣(LeetCode)
第一次做多线程的题目,还蛮有意思的
要求交替打印n次foo和bat
其实可以用资源的角度来理解
即需要打印foo时,说明生产了一个foo令牌,才可以打印
如果要打印bar,则要求有bar令牌才可以。
那么就很容易想到用2个阻塞队列或者2个信号量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class FooBar { private int n; private LinkedBlockingDeque<Integer> fooSync = new LinkedBlockingDeque <>(); private LinkedBlockingDeque<Integer> barSync = new LinkedBlockingDeque <>(); public FooBar (int n) { this .n = n; try { fooSync.put(1 ); } catch (InterruptedException e) { e.printStackTrace(); } } public void foo (Runnable printFoo) throws InterruptedException { for (int i = 0 ; i < n; i++) { fooSync.take(); printFoo.run(); barSync.put(1 ); } } public void bar (Runnable printBar) throws InterruptedException { for (int i = 0 ; i < n; i++) { barSync.take(); printBar.run(); fooSync.put(1 ); } } }
当然也可以用一个boolean布尔值来表示此时打印foo还是打印bar,然后利用等待-唤醒机制。
如果用java自带语法,可以是wait和notify。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class FooBar { private int n; private int count; public FooBar (int n) { this .n = n; this .count = 2 *n; } public void foo (Runnable printFoo) throws InterruptedException { for (int i = 0 ; i < n; i++) { synchronized (this ) { if (count%2 ==1 ) { this .wait(); } printFoo.run(); count--; this .notify(); } } } public void bar (Runnable printBar) throws InterruptedException { for (int i = 0 ; i < n; i++) { synchronized (this ) { if (count%2 ==0 ) { this .wait(); } printBar.run(); count--; this .notify(); } } } }
如果使用JUC,则用Condition即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class FooBar { private int n; private ReentrantLock lock = new ReentrantLock (); private Condition condition = lock.newCondition(); boolean flag; public FooBar (int n) { this .n = n; } public void foo (Runnable printFoo) throws InterruptedException { for (int i = 0 ; i < n; i++) { lock.lock(); if (flag == true ) { condition.await(); } printFoo.run(); flag = true ; condition.signal(); lock.unlock(); } } public void bar (Runnable printBar) throws InterruptedException { for (int i = 0 ; i < n; i++) { lock.lock(); if (flag == false ) { condition.await(); } printBar.run(); flag = false ; condition.signal(); lock.unlock(); } } }
2022-08-05 1055. 形成字符串的最短路径 - 力扣(LeetCode)
2个字符串长度最多1000,双指针即可,没啥难的
剑指 Offer II 092. 翻转字符 - 力扣(LeetCode)
提前预处理往左看的1的个数和往右看的0的个数
然后再遍历一次,每次把左边翻0,右边翻1,因为预处理过了所以可以马上得到答案
但是这个做法比较消耗2个O(n)的空间
用动态规划可以节省很多空间
1 2 3 4 5 6 7 8 9 10 11 12 public int minFlipsMonoIncr (String s) { int dp0 = 0 , dp1 = 0 ; for (int c : s.toCharArray()) { int last0 = dp0; int last1 = dp1; dp0 = last0 + (c=='0' ? 0 : 1 ); dp1 = (c=='1' ? 0 : 1 ) + Math.min(last0, last1); } return Math.min(dp0, dp1); }
409. 最长回文串 - 力扣(LeetCode)
就是数量统计题而已
2022-08-07 636. 函数的独占时间 - 力扣(LeetCode)
栈的应用题,start和end等同于左括号和右括号
注意用int[]数组来简化新类的定义操作,注意每次end出栈后,要把这段程序占用的总时间加到栈顶
2022-08-08 1219. 黄金矿工 - 力扣(LeetCode)
提示dfs最大深度为25,则认为可以直接做带vis访问标记的dfs且不需要做记忆化结果。
另外dfs时也不要忘记对初始点的vis处理
1365. 有多少小于当前数字的数字 - 力扣(LeetCode)
虽然是简单题,数量级别只有500,但还是考虑写了一下最快性能,直接按值做键处理,就能知道比每个值小的数量了,然后再分别设置。
761. 特殊的二进制序列 - 力扣(LeetCode)
这题没做出来,直接看答案了
0和1的数量相等 + 任意前缀1数量大于0, 类似于括号匹配
要我们调整括号对使得字典序尽可能大
这样就很容易想到递归了,即最外层括号可以不管, 然后只对内层做处理, 内层找到每一个括号对,然后按字典序排序。
2022-08-09 1413. 逐步求和得到正数的最小值 - 力扣(LeetCode)
遍历求和,求中间sum距离1的最大差值即可
1367. 二叉树中的列表 - 力扣(LeetCode)
O(二叉树节点*链表节点)的复杂度符合要求
遍历每个点为起点,然后往下搜索判断能否找到即可,还是挺有意思的递归应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public boolean isSubPath (ListNode head, TreeNode root) { ListNode node = head; List<Integer> nodes = new ArrayList <>(); while (node != null ) { nodes.add(node.val); node = node.next; } return dfs(root, nodes); } boolean dfs (TreeNode node, List<Integer> nodes) { if (node == null ) { return false ; } if (checkToDown(node, nodes, 0 )) { return true ; } return dfs(node.left, nodes) || dfs(node.right, nodes); } boolean checkToDown (TreeNode node, List<Integer> nodes, int index) { if (index == nodes.size()) { return true ; } if (node == null || node.val != nodes.get(index)) { return false ; } return checkToDown(node.left, nodes, index+1 ) || checkToDown(node.right, nodes, index+1 ); }
剑指 Offer II 077. 链表排序 - 力扣(LeetCode)
要求在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序
那所有排序方法里,只有递归排序可以实现了
而且得是从下往上递归
先11合并,再22合并,再44合并。
链表归并排序处理的几个坑:
头节点可能变更的话,最好提前创建一个dummy头节点,这样dummy头节点.next就是新节点了
注意记录下一个排序序列的起始节点,用于确认是否第二个序列到末尾结束了。
还要记录上次排序序列的末尾节点, 用于排序后更新 上次末尾节点.next
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 class Solution { public ListNode sortList (ListNode head) { int len = 1 ; int listLen = 0 ; ListNode node = head; while (node != null ) { listLen++; node = node.next; } ListNode emptyHead = new ListNode (); emptyHead.next = head; while (len < listLen) { ListNode preNode = emptyHead; ListNode head1 = emptyHead.next; while (head1 != null ) { ListNode head2 = head1; for (int i = 0 ; i < len && head2 != null ;i++) { head2 = head2.next; } if (head2 == null ) { break ; } ListNode nextSortStartNode = head2; for (int i = 0 ; i < len && nextSortStartNode != null ;i++) { nextSortStartNode = nextSortStartNode.next; } ListNode newSortHead = sortBatch(head1, head2, nextSortStartNode); preNode.next = newSortHead; while (preNode.next != nextSortStartNode) { preNode = preNode.next; } head1 = nextSortStartNode; } len*=2 ; } return emptyHead.next; } ListNode sortBatch (ListNode head1, ListNode head2, ListNode nextNode) { ListNode head3 = new ListNode (); ListNode node1 = head1; ListNode node2 = head2; ListNode node3 = head3; while (node1 != head2 || node2 != nextNode) { int val1 = node1 != head2 ? node1.val : Integer.MAX_VALUE; int val2 = node2 != nextNode ? node2.val : Integer.MAX_VALUE; if (val1 < val2) { node3.next = node1; node1 = node1.next; } else { node3.next = node2; node2 = node2.next; } node3 = node3.next; } node3.next = nextNode; return head3.next; } }
2022-08-10 1253. 重构 2 行二进制矩阵 - 力扣(LeetCode)
还是蛮容易推导的一个数组题,先处理掉所有0和2的情况
再处理1的情况,先把1都分配给上边,上边不够之后再分配给下边,最后检查是否清零即可。
1102. 得分最高的路径 - 力扣(LeetCode)
很有意思的搜索题,我想到了bfs,且这个bfs是支持刷新点的bfs。先优先按最大的走
如果发现当前点被人走过,但是自己是比他优(不能相等),则可以刷新对方自己继续走。
1 2 3 4 5 6 if (gMin[ny][nx] != Integer.MIN_VALUE && gMin[ny][nx] >= Math.min(grid[ny][nx], lastMin)) { continue ; } gMin[ny][nx] = Math.min(grid[ny][nx], lastMin); queue.offer(new int []{ny, nx, gMin[ny][nx]});
当然看答案还有dfs+二分, 即确定目标最小值之后, dfs搜索最多10000次。
复杂度O(10000 * (log2(10^9)))
剑指 Offer II 024. 反转链表 - 力扣(LeetCode)
用递归做比较有趣
2022-08-11 1469. 寻找所有的独生节点
直接递归判断,简单
面试题 10.05. 稀疏数组搜索 - 力扣(LeetCode)
二分搜索,但我还是遍历了一遍先过滤空字符串了。导致性能是1ms
但差距不大是因为那些人也要定位后在0上去走,消耗不会差别太大。
1100. 长度为 K 的无重复字符子串 - 力扣(LeetCode)
很简单的滑动窗口
第一波做出来性能20ms,不是最佳。因为用了Stream去判断是否有重复
1 2 3 public boolean valid (int [] counts) { return Arrays.stream(counts).noneMatch(c -> c >= 2 ); }
去掉Stream改用简单for循环,性能就到 5 ms 了
去掉k>26的判断,提升到4ms
避免每次26次判断,用repeatCount值来记录,这样每次最多判断2次,结果还是4ms
1417. 重新格式化字符串
一般那种要你交叉放数字的,都可能有一种改进点是看你能否空间复杂度为O(1)(不包含结果输出空间)
这就需要原地算法,双指针进行交换
2022-08-12 1282. 用户分组 - 力扣(LeetCode)
按数量建哈希表,每个数量对应一个列表,列表满了就放入结果中并重置,很简单
1423. 可获得的最大点数 - 力扣(LeetCode)
只能取左右两边,那么等同于滑动窗口,只不过是反着求中间的滑动窗口最小值
剑指 Offer II 067. 最大的异或 - 力扣(LeetCode)
很有意思,要求 nums[i] XOR nums[j] 的最大运算 结果
想了半天终于想起来有一个字典树这玩意,一开始觉得麻烦,后来还是写了 ,答案也有这个思路,很棒
只不过自己得记住,要先在字典树中试图求解最大运算结果, 求解完成后,才能把自己再插入字典树中
2022-08-13 1678. 设计 Goal 解析器 - 力扣(LeetCode)
直接取临时字符串然后判断即可
1874. 两个数组的最小乘积和 - 力扣(LeetCode)
直接排序后第一个数组的最大乘第二个数组的最小,依次处理即可,很简单,虽然我不知道怎么证明 768. 最多能完成排序的块 II - 力扣(LeetCode)
一次就AC了, 想到了动态规划
每次求出左边的最大值
然后看一下自己当前位置往左边遍历时,选取那个左边位置作为一块,能否满足要求,能满足要求则就看判断当前最大分割块即可
1 2 3 if (左边最大值 小于 我当前位置从右往左遍历时的最小值, 说明可以分割){ dp[当前位置] = Math.max(dp[左边界-1 ] + 1 , dp[当前位置]); }
2022-08-15 641. 设计循环双端队列 - 力扣(LeetCode)
循环双端队列,其实关键在于循环队列的定义,双端的话很容易处理的。
这题肯定是要用数组来做比较有意义
循环队列数组概念硬记忆:
front指向已存储的队头元素, rear指向已存储的队尾元素的下一个位置(即空位置)
队满: (Q.rear+1)%M = Q.front, 即队尾的下一个位置已经有了
队空: Q.front = Q.rear 即队头存储的是一个空的
队长: (rear-front+M)%M
剑指 Offer 66. 构建乘积数组 - 力扣(LeetCode)
很简单, 直接计算左边前缀乘积, 计算右边前缀乘积即可
1015. 可被 K 整除的最小整数 - 力扣(LeetCode)
数字末尾是1的情况下,肯定不能被2和5整除
通过公式推导:
1 2 3 4 5 6 7 8 9 设n=p*K+q 则n*10 +1 = 10 *p*K + q*10 +1 ; 对两边都取k取余 有(n*10 +1 )%K=(10 *p*K+q*10 +1 )%K 又因为n%k=q 则右边(10 *p*K+q*10 +1 )%K = (q*10 +1 )%K = (n%k*10 + 1 ) %K 推断出:(n*10 +1 )%K = ((n%K)*10 +1 )%K 因此(n*10 +1 )如果能被k整除,等同于 (n%k)*10 +1 被k整除 所以只要n做增加时先取余即可
不含2和5的质因子的数必定在K之内有解,直接用其mod循环即可,避免了大数之间的除法
2022-08-16 1656. 设计有序流 - 力扣(LeetCode)
用String[]做数组,当前点之前是空,现在要插入,则可以尝试往后遍历直到遇到空
2278. 字母在字符串中的百分比 - 力扣(LeetCode)
没看懂有啥用
326. 3 的幂 - 力扣(LeetCode)
直接按3取余,不断除3,直到为1说明就是3的幂
题解有个超简单方法:
根据数值范围,找到最大的3幂的值 1162261467 ,然后直接看 1162261467 能否被询问的这个值整除即可
这提示我们如果以后遇到这种需求,可以直接定义一个最大范围值取判断,而不用自己重复去循环计算
1 2 3 4 5 class Solution { public boolean isPowerOfThree (int n) { return n > 0 && 1162261467 % n == 0 ; } }
2022-08-17 914. 卡牌分组 - 力扣(LeetCode)
记住gcd公式:
1 2 3 public int gcd (int x, int y) { return x = = 0 ? y : gcd(y % x, x); }
或者这题里因为题目必须要求分成每组X个,所以总数必须要能被X整除,这就过滤掉很多了
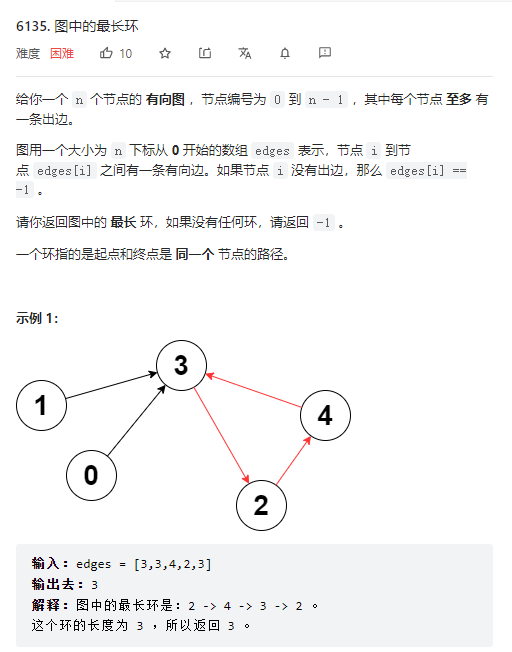
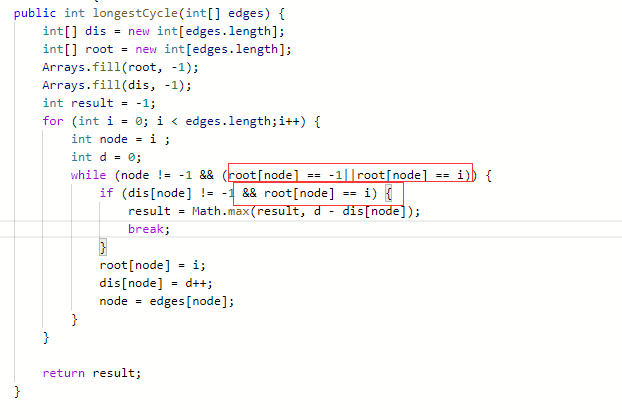
684. 冗余连接 - 力扣(LeetCode)
一个树,加上一个边构成带环的图,问怎么找到应该去掉的那条边,重新变回树
我最初的思路:每次去掉一个边,然后做bfs看是否重新碰到自己的点,但是要考虑很多判断,很麻烦
这题最佳是用并查集, 当拼接的时候,如果发现左右两个点属于同一个集合,则一定会出现环
即是否图中成环的判断可以用这个方式:
通过边连接2个点的时候,如果2个点属于同一个并查集,则一定存在环
1733. 需要教语言的最少人数 - 力扣(LeetCode)
最开始以为我的思路需要500乘500乘500
后来发现其实好友关系的总数只有500,即边只有500个
则遍历次数少了500倍
那可以直接遍历每种语言,判断能否加
注意需要提前处理掉那些不需要新学语言的人(即他和他的所有好友都有共同语言)