[toc]
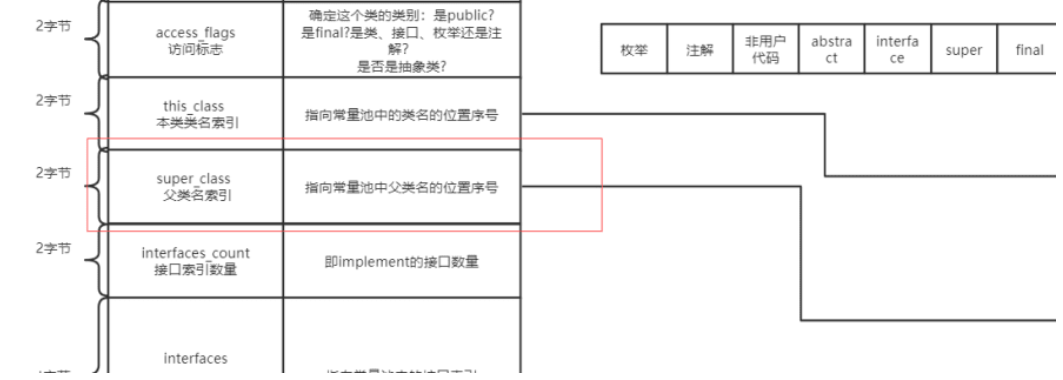
修饰符 Q: 各修饰符所代表的可见性? public: 可被所有使用
Q: 外部类可以用private或者protect修饰吗? A: 不能,只能用public或者包访问权限。 内部类可以。
解释以下final的作用 Q: final 成员? A: 如果是基本类型,则指值不能被改变。 如果是对象,指对象的引用不可改变,但是引用处的内容可改变。
编译器会要求final成员必须初始化或者构造器里赋值,且后续不能再主动赋值。
Q: final 参数? A: 参数不可变,只能读不能修改,同上
Q: final方法 A: 方法不能被子类重写。
Q: final类 A: 该类不能被继承。
Q:final局部变量可以作为非final的参数传入吗?会编译报错吗? 1 2 3 4 5 6 7 public static void main (String[] args) { final A a = new A (); changeA(a); } public void changeA (A a) { }
A:
类 Q: 重载和重写的区别? A:
Q: 如果子类重写了父类中的方法, 那么子类中还能调用父类中的同名方法吗? A: 可以,super.xxx即可(C++中不可以调用父类中的同名重载方法)。
Q: 怎样能避免子类在重写父类的方法,不小心弄成了重载? (即你想重写父类的f(int), 却不小心写成了f(int,int),导致调用f(int)时还是调用了父类的f ,怎么能避免这种失误?)
Q:父类的成员变量能被重写/覆盖嘛? 1 2 3 4 5 6 7 8 9 10 class A { public String name = "A" ; } class B extends A { public String name = "B" ; } public static void main{ A a = new B (); System.out.println(a.name); }
A:
Q:内部类是啥,内部类能访问外部类的成员吗? A:
1 2 3 4 5 6 class A { class B { ... } }
B就是A的内部类,B能访问A的所有成员
Q: A中有1个内部类C, A的子类B中也有1个内部类C, B中的C会覆盖A中的C吗? A: 不会, 因为使用时是通过B.C或者A.C去调用的,存在命名空间的关系。
Q:可以在内部类中定义静态成员吗? 1 2 3 4 5 6 class A { class B { static int b; ... } }
A:
Q: 匿名类是啥, 匿名类能访问外面的变量或者对象吗? A: 匿名类概念:
1 2 3 4 return new A (构造参数){ {构造器内容} 类定义 }
匿名类如果要用外面的对象, 外面的对象必须要定义为final。
Q: 嵌套类是啥,能访问外部类的成员吗? A:
1 2 3 4 5 class A { static int sa; int a; static class B {} }
B只能访问A中的静态成员sa, 而不能访问a。
接口 类是单继承,接口可以多继承
Q: 接口中如果要定义成员变量,那成员的默认修饰符是什么? A: public static final
Q: 接口中各方法的默认修饰符是什么? A: public abstract
Q: 接口中可以定义实现具体方法嘛? A:
枚举 Q: enum可以被继承吗? 像下面这样:
A: 不可以。enum标识符本身被编译器处理过,自身就继承自Enum类,而java不支持多重继承。但支持实现接口
Q: switch(enum)时需要加default吗? A: 可以不需要。
Q: Enum基类里实现了values()方法吗? A: 没有实现, values方法是编译器加的。因此从List里取出的对象,是不能调用values()的。
Q:enum里的枚举的默认修饰符默认是?
静态分派和动态分派 Q: 下面输出什么,属于什么分派? 1 2 3 4 5 6 7 8 9 10 11 12 void test () { Father father = new Son (); print(father); } void print (Father father) { System.out.println("this is father" ); } void print (Son son) { System.out.println("this is son" ); }
A:
静态类型概念: 编译期写在java文件里能马上看到的类型
Q: 涉及如下各种不同数据类型的静态分派如何应对? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Overload { private static void sayHello (char arg) { System.out.println("hello char" ); } private static void sayHello (Object arg) { System.out.println("hello Object" ); } private static void sayHello (int arg) { System.out.println("hello int" ); } private static void sayHello (long arg) { System.out.println("hello long" ); } public static void main (String[] args) { sayHello('a' ); } }
输出什么?
总结:当没有最合适的方法进行重载时,会选优先级第二高的的方法进行重载,如此类推。
上面可以看到,重载时选择方法的优先级顺序是基本类型->高精度类型->包装类->接口(从下往上)->父类(从下往上)->可变参数
Q: 下面输出什么,属于什么分派: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void test () { Father father = new Son (); father.name(); } class Son extends Father { void name () { System.out.println("son" ); } } class Father { void name () { System.out.println("father" ); } }
A:
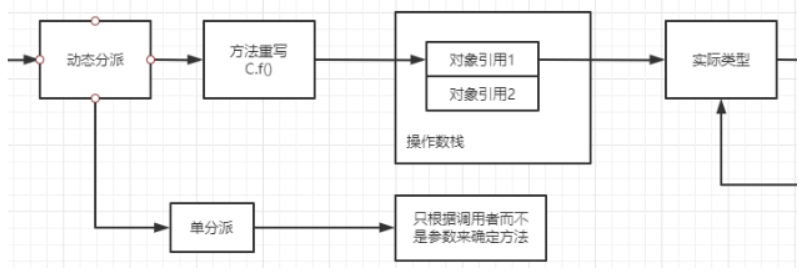
Q:静态分派属于单分派还是多分派?动态分派属于单分派还是多分派? A:
动态分派原理:
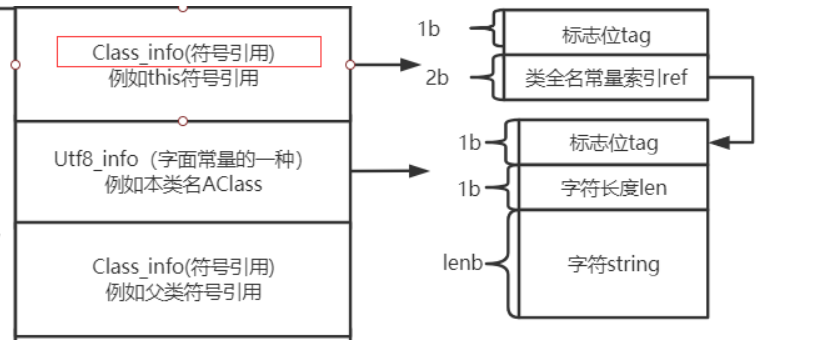
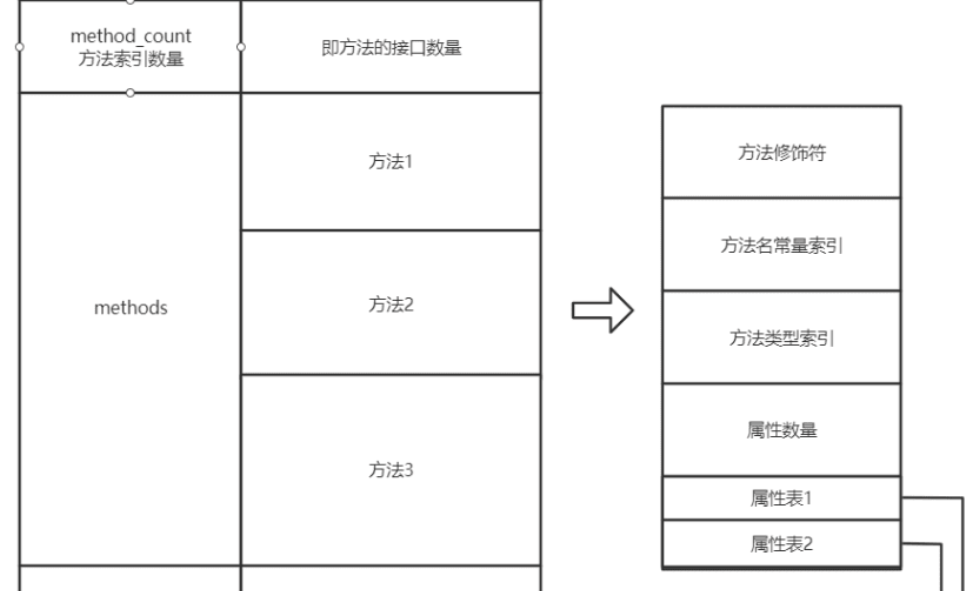
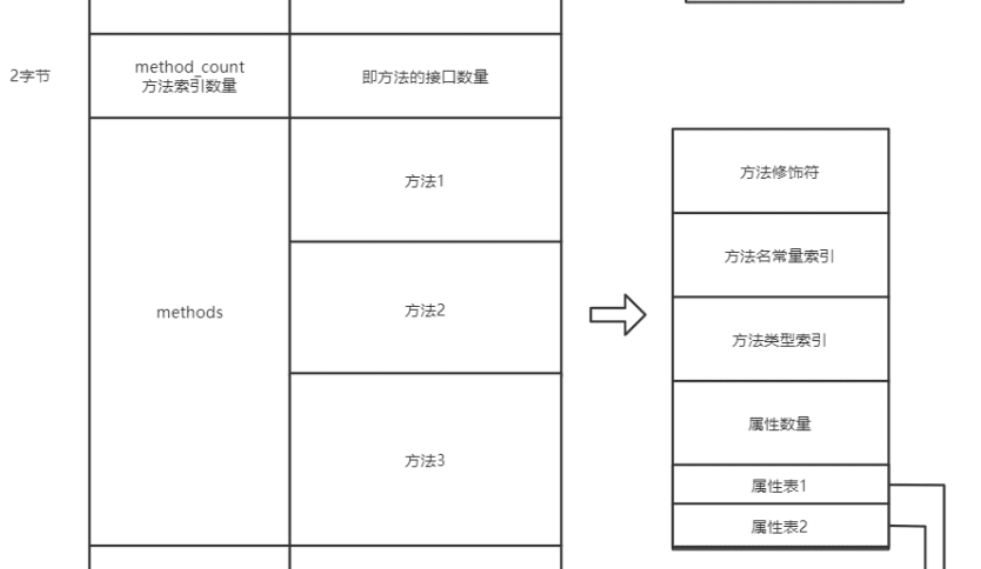
Q:类方法在class文件中是什么样的? 是符号引用还是直接引用? A:
然后方法在class文件中时这样存放的, 先是一个method_count数量,接着再存储方法。
此时是不知道方法的指令地址的。 除非从符号引用转为直接引用。
Q:什么时候方法的符号引用会转为实际方法区中的直接引用? A:
构造
私有
静态
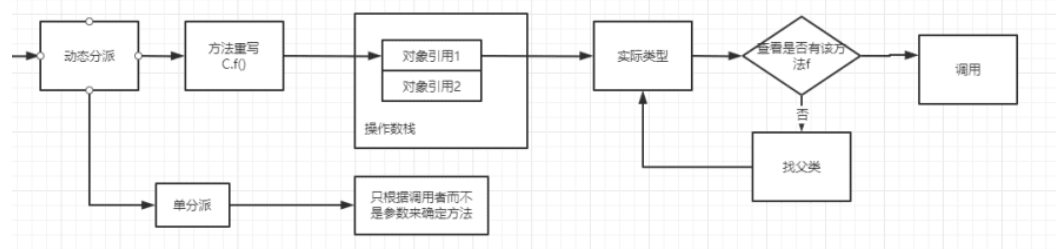
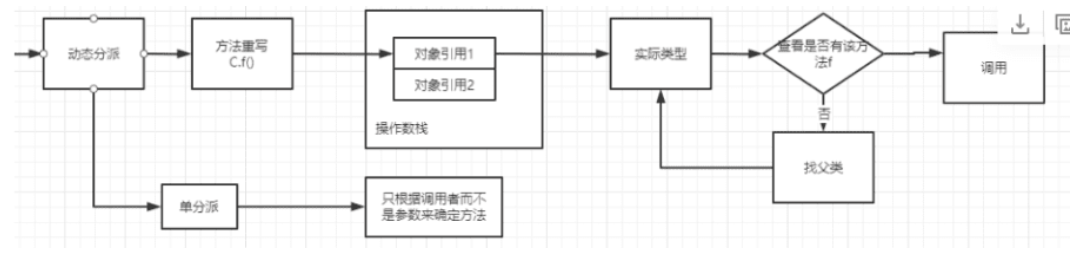
Q:动态分派(即多态), 虚拟机里是怎么确定调用哪个方法的? 如下, 他怎么确定调用的是Son实现的do, 还是father实现的do?
1 2 3 4 int a = 1 ;Father f = new Son ()f.do (a);
A:而你执行f.do (a)时, 操作数栈上会存放一个对象引用
那么执行f方法的虚拟机指令就会通过这个对象引用,找到他的实际类型的class
他会在这个实际类中查找是否有实现这个方法,具体看class文件中有没有这个方法的定义
如果没有找到,他就去父类找,父类的关系class文件中就可以知道
如果父类没有,就接着往上找,直到找到实现了的。






.png)
.png)