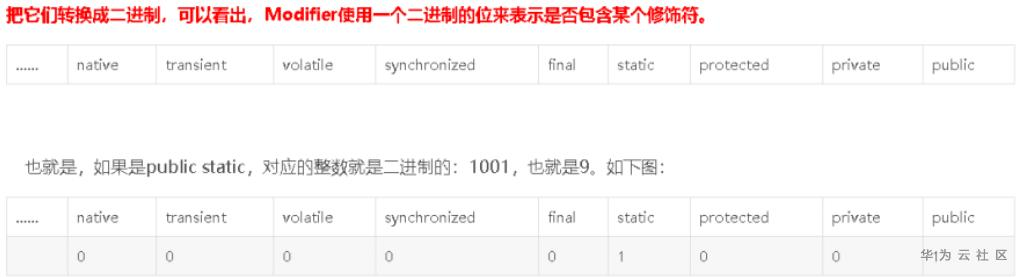
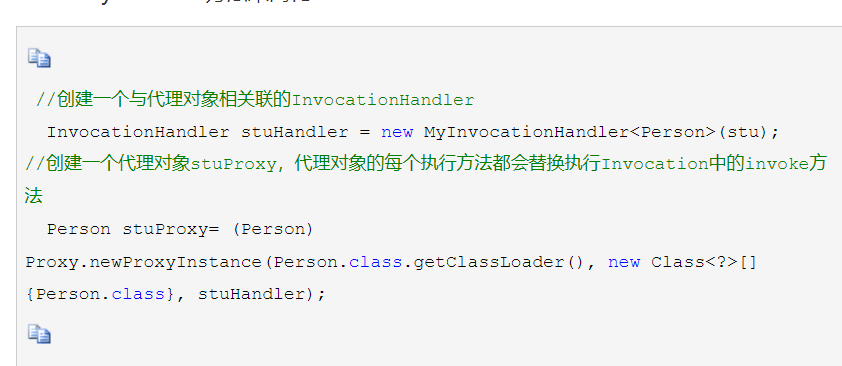
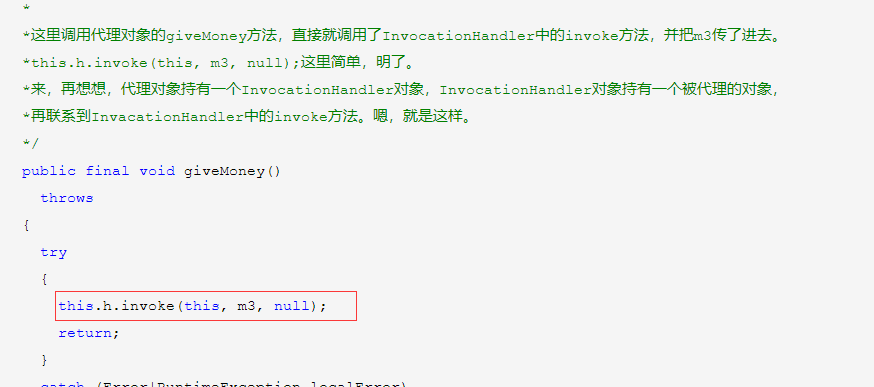
[toc]
Thread类基础 Q: Thread的deprecated过期方法是哪3个?作用是啥 A:
stop(), 终止线程的执行。
suspend(), 暂停线程执行。
resume(), 恢复线程执行。
Q: 废弃stop的原因是啥? A:并且不会做线程内的catch操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class Test { public static void main (String[] args) throws InterruptedException { System.out.println("start" ); Thread thread = new MyThread (); thread.start(); Thread.sleep(1000 ); thread.stop(); } } class MyThread extends Thread { public void run () { try { System.out.println("run" ); Thread.sleep(5000 ); } catch (Exception e) { System.out.println("clear resource!" ); } } }
答案是输出 start和run,但是不会输出clear resource
Q: stop的替代方法是什么? A: interrupt()。
Q: suspend/resume的废弃原因是什么? A: :调用suspend不会释放锁。
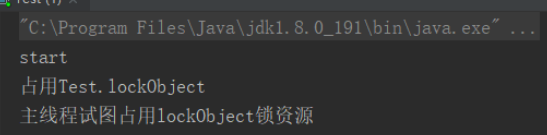
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class Test { public static Object lockObject = new Object (); public static void main (String[] args) throws InterruptedException { System.out.println("start" ); Thread thread = new MyThread (); thread.start(); Thread.sleep(1000 ); System.out.println("主线程试图占用lockObject锁资源" ); synchronized (Test.lockObject) { System.out.println("做一些事" ); } System.out.println("恢复" ); thread.resume(); } } class MyThread extends Thread { public void run () { try { synchronized (Test.lockObject) { System.out.println("占用Test.lockObject" ); suspend(); } System.out.println("MyThread释放TestlockObject锁资源" ); } catch (Exception e){} } }
答案输出
MyThread内部暂停后,外部的main因为没法拿到锁,所以无法执行后面的resume操作。
Q: 上题的suspend和resume可以怎么替换,来解决死锁问题? A: 可以用wait和noitfy来处理(不过尽量不要这样设计,一般都是用run内部带1个while循环的)
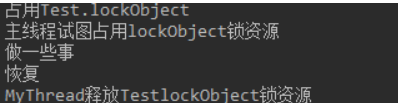
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Test { public static Object lockObject = new Object (); public static void main (String[] args) throws InterruptedException { Thread thread = new MyThread (); thread.start(); Thread.sleep(1000 ); System.out.println("主线程试图占用lockObject锁资源" ); synchronized (Test.lockObject) { System.out.println("做一些事" ); } System.out.println("恢复" ); synchronized (Test.lockObject) { Test.lockObject.notify(); } } } class MyThread extends Thread { public void run () { try { synchronized (Test.lockObject) { System.out.println("占用Test.lockObject" ); Test.lockObject.wait(); } System.out.println("MyThread释放TestlockObject锁资源" ); } catch (Exception e){} } }
如此执行,结果正常:
Q: 下面这例子为什么会运行异常,抛出IllegalMonitorStateException错误? 1 2 3 4 5 public static void main (String[] args) throws InterruptedException { Thread thread = new MyThread (); thread.start(); thread.notify(); }
A: notify和wait的使用前提是必须持有这个对象的锁, 即main代码块 需要先持有thread对象的锁,才能使用notify去唤醒(wait同理)。
1 2 3 4 5 Thread thread = new MyThread ();thread.start(); synchronized (thread) { thread.notify(); }
Q: 为什么wait必须持有锁的时候才能调用? A:
一般是到了一定条件例如缺少资源、缺乏某个前置动作时,才会进入wait。
这时候生产资源的那个线程生产了新资源后,就会调用notify方法,告诉另一个线程,我做好了,你可以动身了。
但如果我们不先加同步块, 就可能导致 wait之前的判断条件有问题,即先判断缺资源, 然后切到另一个线程 做了资源生产并notify, 这时候再wait已经没有意义了, 永远收不到notify。 ”即如果不在同步块中,则wait的判断条件或者wait时机可能是有问题的!“为什么WAIT必须在同步块中
Q: Thread.sleep()和Object.wait()的区别 A:
Q: 如果有3个线程同时抢占了这个锁且都在wait,我希望只notify唤醒某个线程,怎么办? A:
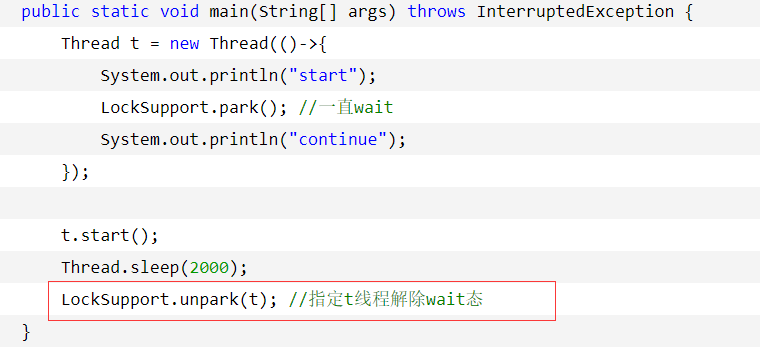
使用LockSupport, 可以unPark指定的线程。
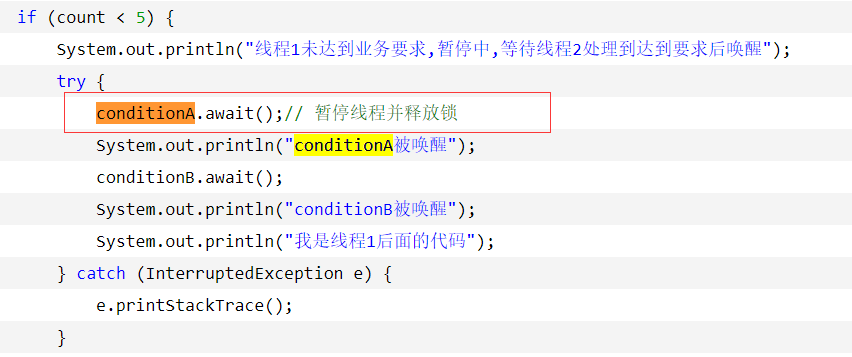
使用Lock + Condition 实现唤醒指定的部分线程。即锁是同一个,但是可以针对锁生成的特定condition做唤醒
Q: LockSupport相比notify/wait有什么优点? A:
LockSupport不需要在同步代码块里 。所以线程间也不需要维护一个共享的同步对象了,实现了线程间的解耦。
unpark函数可以先于park调用,所以不需要担心线程间的执行的先后顺序。
Q:Runnable接口和Callable的区别。 A: Callable可以和Futrue配合,并且启动线程时用的时call,能够拿到线程结束后的返回值,call方法还能抛出异常。
Q:thread.alive()表示线程当前是否处于活跃/可用状态。thread.start()后,是否alive()一定返回true? 活跃状态: 线程已经启动且尚未终止。线程处于正在运行或准备开始运行的状态,就认为线程是“存活的
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { TestThread tt = new TestThread (); System.out.println("Begin == " + tt.isAlive()); tt.start(); System.out.println("end == " + tt.isAlive()); } }
A:
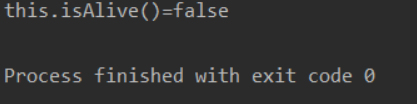
Q: 线程A如下,把线程A作为构造参数,传给线程B,此时对B线程打印this.isAlive会显示什么?: 1 2 3 4 5 6 public class A extends Thread { @Override public void run () { System.out.println("this.isAlive()=" + this .isAlive()); } }
1 2 3 A a = new A ();Thread b = new Thread (a);b.start()
A:
因为把a作为构造参数传入b中, b执行start时, 实际上是在B线程中去调用了 A对象的run方法,而不是启用了A线程。
1 2 A a = new A ();a.start()
那么就会打印true了
Q:把FutureTask放进Thread中,并start后,会正常执行callable里的内容吗? 1 2 3 4 5 6 7 8 9 10 public static void main (String[] args) throws Exception { Callable<Integer> callable = () -> { System.out.println("call 100" ); return 100 ; }; FutureTask<Integer> task = new FutureTask <>(callable); Thread thread = new Thread (task); thread.start(); }
A:
synchronized关键字
即可作为方法的修饰符,也可以作为代码块的修饰符
注意修饰方法时,并不是这个方法上有锁, 而是调用该方法时,需要取该方法所在对象上的锁。
1 2 3 4 class A { synchroized f () { } }
即调用这个f(), 并不是说f同一时刻只能进入一次,而是说进入f时,需要取到A上的锁。
Q: 调用下面的f()时,会出现死锁吗? 1 2 3 4 5 6 7 8 class A { synchroized f () { t() } synchroized t () { } }
A:不会。
sync和JUC-Lock都是可重入锁,原理类似。
Q:2个线程同时调用f1和f2会产生同步吗? 1 2 3 4 class A { private static synchronized void f1 () {}; private synchronized void f2 () {}; }
A:
其他的同步工具 CountDownLatch 1 final CountDownLatch latch = new CountDownLatch (2 );
2是计数器初始值。
和join的区别:
Q: countDownLatch的内部计数值能被重置吗? A:
FutureTask 可以理解为一个支持有返回值的线程
Q:调用futrueTask.get()时,这个是阻塞方法吗?如果是阻塞,什么时候会结束? A:
线程跑完并返回结果
阻塞时间达到futrueTask.get(xxx)里设定的xxx时间
线程出现异常InterruptedException或者ExecutionException
线程被取消,抛出CancellationException
Semaphore 信号量概念 就是操作系统里常见的那个概念,java实现,用于各线程间进行资源协调。https://blog.csdn.net/hanchao5272/article/details/79780045
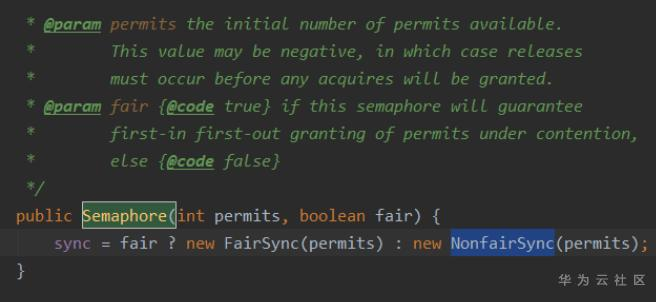
Q: 信号量中,公平模式和非公平模式的区别?下面设成true就是公平模式 1 2 semaphore = new Semaphore (5 , true );
A:
Java并发中的NonfairSync(非公平)和fairSync(公平)主要区别为:
如果当前线程不是锁的占有者,则NonfairSync并不判断是否有等待队列,直接使用compareAndSwap去进行锁的占用,即谁正好抢到,就给谁用!
如果当前线程不是锁的占有者,则FairSync则会判断当前是否有等待队列,如果有则将自己加到等待队列尾,即严格的先到先得!
CyclicBarrier (栅栏) 栅栏,一般是在线程中去调用的
Exchanger (交换栅栏) 我理解为两方栅栏,用于交换数据。
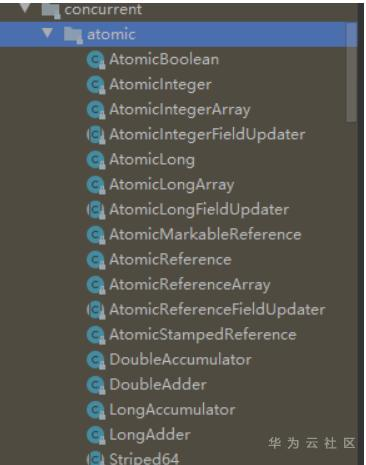
原子类AtomicXXX 就是内部已实现了原子同步机制
Q:下面输出什么?(考察getAndAdd的用法) 1 2 3 AtomicInteger num = new AtomicInteger (1 );System.out.println(num.getAndAdd(1 )); System.out.println(num.get());
A:
Q:AtomicReference和AtomicInteger的区别? A:
经典用法:
AtomicReferenceArray是原子数组, 可以进行一些原子的数组操作例如 set(index, value),
java中已实现的全部原子类:
注意,没有float,没有short和byte。
线程池 Q: ThreadPoolExecutor线程池构造参数中,corePoolSize和maximumPoolSize有什么区别? A:
如果当前线程数 < corePoolSize,则会创建新线程
如果当前线程数=corePoolSize,则新线程被塞进一个队列中等待。
如果队列也被塞满了,那么又会开始新建线程来运行任务,避免任务阻塞或者丢弃
如果队列满了的情况下, 线程总数超过了maxinumPoolSize,那么就抛异常或者阻塞(取决于队列性质)。
调用prestartCoreThread()可提前开启一个空闲的核心线程
调用prestartAllCoreThreads(),可提前创建corePoolSize个核心线程。
Q: 线程池的keepalive参数是干嘛的? A:当线程数量在corePoolSize到maxinumPoolSize之间时, 如果有线程已跑完,且空闲时间超过keepalive时,则会被清除(注意只限于corePoolSize到maxinumPoolsize之间的线程)
Q: 核心线程可以被回收吗?(线程池没有被回收的情况下) A:
Q: 那这个线程数设置多少,你是怎么考虑的呢? A:
有超线程技术的话, 一般可以设置成2倍CPU数量的线程数
超线程技术把多线程处理器内部的两个逻辑内核模拟成两个物理芯片,让单个处理器就能使用线程级的并行计算,进而兼容多线程操作系统和软件。超线程技术充分利用空闲CPU资源,在相同时间内完成更多工作
Q: 线程池有哪三种队列策略? A:
握手队列
无界队列
有界队列
Q: 线程池队列已满且maxinumPoolSize已满时,有哪些拒绝策略? A:
AbortPolicy 默认策略:直接抛出RejectedExecutionException异常
DiscardPolicy 丢弃策略: 直接丢了,什么错误也不报
DiscardOldestPolicy 丢弃队头策略: 即把最先入队的人从队头扔出去,再尝试让该任务进入队尾(队头任务内心:不公平。。。。)
CallerRunsPolicy 调用者处理策略: 交给调用者所在线程自己去跑任务(即谁调用的submit或者execute,他就自己去跑) 注意这个策略会用的比较多
也可以用实现自定义新的RejectedExecutionHandler
Q: 线程池为什么需要阻塞队列? A:
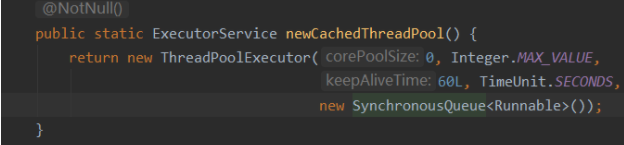
Q:有以下五种Executor提供的线程池,注意记忆一下他们的用途,就能理解内部的原理了。
newCachedThreadPool: 缓存线程池
newFixedThreadPool :定长线程池
newScheduledThreadPool :定时器线程池
newSingleThreadExecutor : 单线程池
newWorkStealingPool(继承自ForkJoinPool ): 并行线程池https://blog.csdn.net/m0_37542889/article/details/92640903
A:
Q: submit和execute的区别是什么? A:
execute只能接收Runnable类型的任务,而submit除了Runnable,还能接收Callable(Callable类型任务支持返回值)
execute方法返回void, submit方法返回FutureTask。
异常方面, submit方法因为返回了futureTask对象,而当进行future.get()时,会把线程中的异常抛出,因此调用者可以方便地处理异常。(如果是execute,只能用内部捕捉或者设置catchHandler)
Q:线程池中, shutdown、 shutdownNow、awaitTermination的区别? A:
shutdown: 停止接收新任务,等待所有池中已存在任务完成( 包括等待队列中的线程
shutdownNow: 停止接收新任务,并 停止所有正执行的task
awaitTermination: 仅仅是一个判断方法
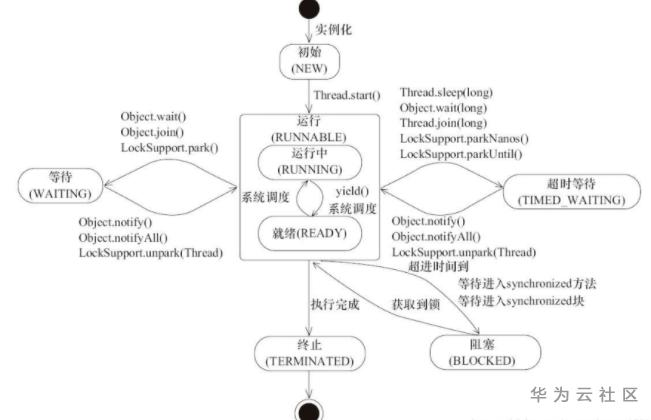
Thread状态转换 Q: 线程的6种状态是: A:
New: 新建了线程,但是还没调用start
RUNNABLE: 运行, 就绪状态包括在运行态中
BLOCKED: 阻塞,一般是因为想拿锁拿不到
WAITING: 等待,一般是wait或者join之后
TIMED_WAITING: 定时等待,即固定时间后可返回,一般是调用sleep或者wait(时间)的。
TERMINATED: 终止状态。
欣赏一幅好图,能了解调用哪些方法会进入哪些状态。
原图链接
Q: java线程什么时候会进入阻塞(可能按多选题考): A:
sleep
wati()挂起, 等待获得别的线程发送的Notify()消息
等待IO
等待锁
Volatile 用volatile修饰成员变量时, 一旦有线程修改了变量,其他线程可立即看到改变。
Q: 不用volatile修饰成员变量时, 为什么其他线程会无法立即看到改变? A:
Q: 用了volatile是不是就可以不用加锁啦? A: 不行。
锁并不是只保证1个变量的互斥, 有时候是要保证几个成员在连续变化时,让其他线程无法干扰、读取。
而volatile保证1个变量可变, 保证不了几个变量同时变化时的原子性。
Q:展示一段《Java并发编程实战》书里的一个经典例子,为什么下面这个例子可能会死循环,或者输出0?
A:https://www.cnblogs.com/coshaho/p/8093944.html
然后分析后面那2个奇怪的情况是怎么发生的。
永远不输出:
ReaderThread在while里读取ready值, 此时是false, 于是存入了ReaderThread的寄存器。
主线程修改ready和number。
ReaderThread没有感知到ready的修改(对于ReaderThread线程,感知不到相关的指令,来让他更新ready寄存器的值),因此进入死循环。
输出0
ReaderThread读取到number值, 此时number还是初始化的值为0,于是输出0
主线程这时候才修改number=42,此时ReaderThread已经结束了!
上面这个问题,可以用volatile或者加锁。当你加了锁时, 如果变量被写了,会有指令去更新另一个寄存器的值,因此就可见了。
Q: volatile变量如果定义的太多会发生什么? A:
线程群组 为了方便管理一批线程,我们使用ThreadGroup来表示线程组,通过它对一批线程进行分类管理
1 2 Thread group = new ThreadGroup ("group" );Thread thread = new Thread (gourp, ()->{..});
即thread除了Thread(Runable)这个构造方法外,还有个Thread(ThreadGroup, Runnable)构造方法
Q:在线程A中创建线程B, 他们属于同一个线程组吗 A:
线程组的一大作用是对同一个组线程进行统一的异常捕捉处理,避免每次新建线程时都要重新去setUncaghtExceptionHandler。即线程组自身可以实现一个uncaughtException方法。
1 2 3 4 5 6 7 ThreadGroup group = new ThreadGroup ("group" ) { @Override public void uncaughtException (Thread thread, Throwable throwable) { System.out.println(thread.getName() + throwable.getMessage()); } }; }
线程如果抛出异常,且没有在线程内部被捕捉,那么此时线程异常的处理顺序是什么?
来源:https://blog.csdn.net/qq_43073128/article/details/90597006 https://blog.csdn.net/qq_43073128/article/details/88280469
好,别急着记,先看一下下面的题目,问输出什么:
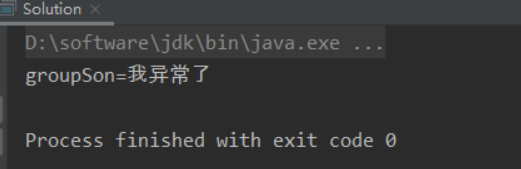
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static class GroupFather extends ThreadGroup { public GroupFather (String name) { super (name); } @Override public void uncaughtException (Thread thread, Throwable throwable) { System.out.println("groupFather=" + throwable.getMessage()); } } public static void main (String[] args) { GroupFather groupSon = new GroupFather ("groupSon" ) { @Override public void uncaughtException (Thread thread, Throwable throwable) { System.out.println("groupSon=" + throwable.getMessage()); } }; Thread thread1 = new Thread (groupSon, ()->{ throw new RuntimeException ("我异常了" ); }); thread1.start(); }
A:
即指的是构造关系的有父子关系。
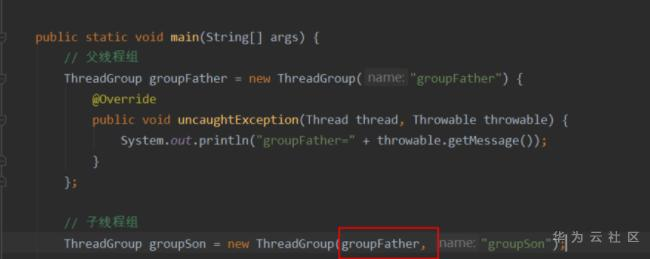
Q: 那我改成构造关系上的父子关系,下面输出什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void main (String[] args) { ThreadGroup groupFather = new ThreadGroup ("groupFather" ) { @Override public void uncaughtException (Thread thread, Throwable throwable) { System.out.println("groupFather=" + throwable.getMessage()); } }; ThreadGroup groupSon = new ThreadGroup (groupFather, "groupSon" ) { @Override public void uncaughtException (Thread thread, Throwable throwable) { System.out.println("groupSon=" + throwable.getMessage()); } }; Thread thread1 = new Thread (groupSon, ()->{ throw new RuntimeException ("我异常了" ); }); thread1.start(); }
A:
即只要子线程组有实现过,则会用子线程组里的方法,而不是直接去找的父线程组!
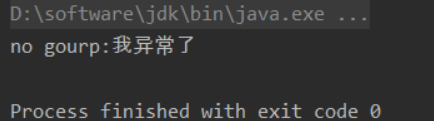
Q:如果我让自己做set捕捉器的操作呢?那下面这个输出什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public static void main (String[] args) { ThreadGroup group = new ThreadGroup ("group" ) { @Override public void uncaughtException (Thread thread, Throwable throwable) { System.out.println("group=" + throwable.getMessage()); } }; Thread thread1 = new Thread (group, () -> { throw new RuntimeException ("我异常了" ); }); thread1.setUncaughtExceptionHandler((t, e) -> { System.out.println("no gourp:" + e.getMessage()); }); thread1.start(); }
A:
也就是说,如果线程对自己特地执行过setUncaughtExceptionHandler,那么有优先对自己设置过的UncaughtExceptionHandler做处理。
那难道第(2)点这个是错的吗?确实错了,实际上第二点应该指的是全局Thread的默认捕捉器,注意是全局的
这里就解释了之前的那三点,但是该代码中没考虑线程自身设置了捕捉器
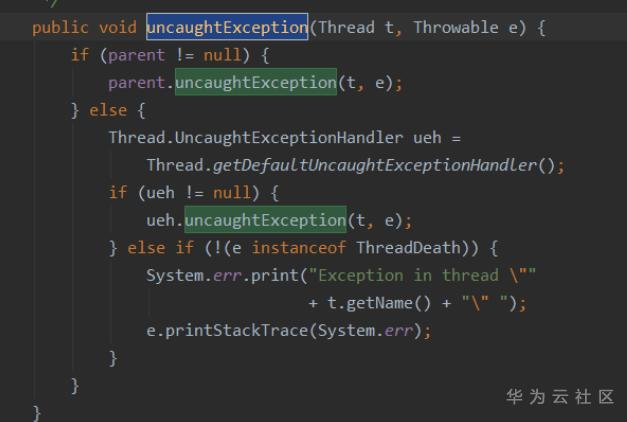
修改一下之前的总结一下线程的实际异常抛出判断逻辑:
如果线程自身有进行过setUncaughtExceptionHandler,则使用自己设置的按个。
如果没设置过,则看一下没有线程组。并按照以下逻辑判断:
如果线程组以及父类都没覆写过uncaughtException, 则判断是否用Thread.setDefaultUncaughtExceptionHandler(xxx)去设置全局的默认捕捉器,有的话则用全局默认
如果不是ThreadDeath线程, 则只打印堆栈。
如果是ThreadDeath线程,那么就什么也不处理。