[toc]
beanFactory基础概念#
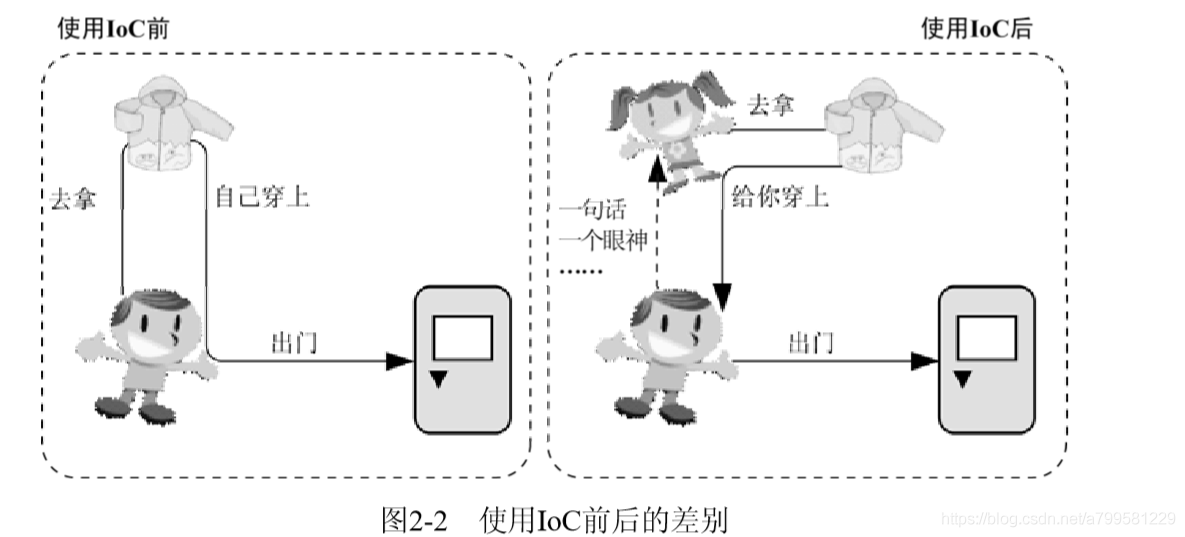
Spring Ioc容器体系除了IOC serviceProvider,还包括其他的东西。
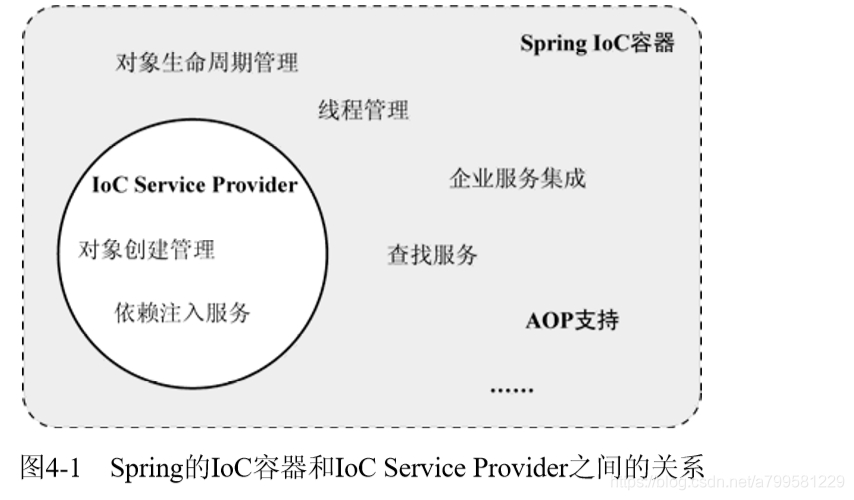
图上可以看到除了IocProvider, 还包括了AOP、线程管理、周期管理之类的。
Spring提供2种容器 BeanFactory和ApplicationContext
区别:
- BeanFactory: 延迟化加载。适合轻量级场景
- ApplicationContext: 给予BeanFacotry构建, 除了支持BeamFacotry所有功能,还提供了其他特性)
ApplicationContext所管理 的对象,在该类型容器启动之后,默认全部初始化并绑定完成
区别就是 1个是要用的时候才加载, 另一个是直接全部扫描并加载好(有点像jvm的client模式和server模式区别)
BeanFacotry是1个接口, 最重要的方法是getBean(name)
BeanFacotry的调用方式:

BeanFactory里的几个重要概念:
用图书馆的比喻在图里标注了一下
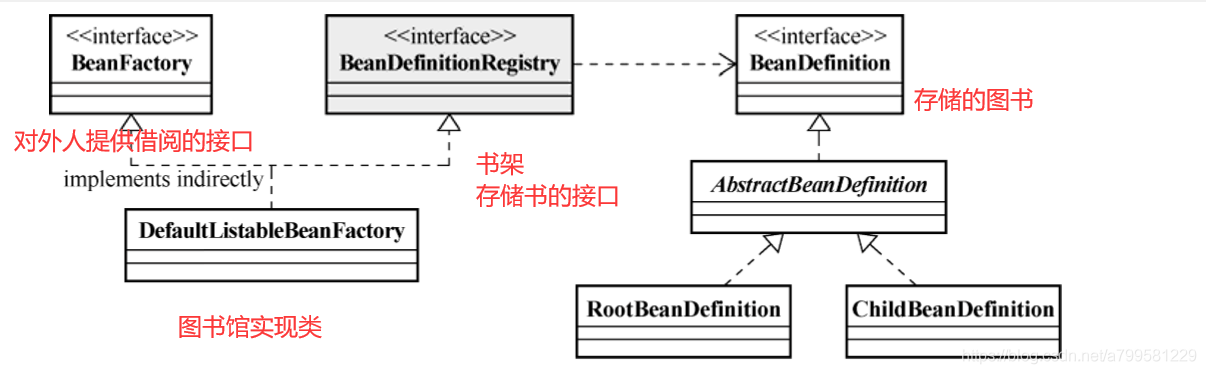
BeanFactory如何明确依赖关系,绑定依赖?
代码编写方式#
通过BeanDefinitionRegistry(BeamFacotry的实现,)去手动注册, 但是手动注册必须实现BeanDefintionRegistry:

基于SpringBoot ,怎么拿到BeanFactory进行直接编码?
1 | 写一下项目里怎么拿到BeanFactory |
2.外部配置文件#
支持Properties文件格式和XML文件格式
Spring会实现1个BeanDefinitionReader类,用于进行 "图书的入库读取操作”, 并注册到BeanDefinetionRegistry里
propetris:
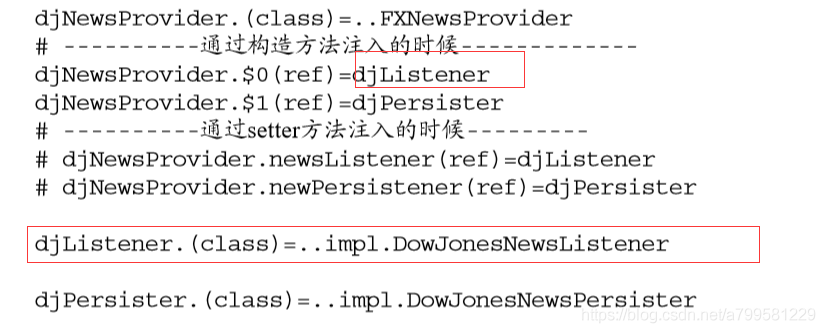
需要注意的一点,就是$0和$1后面的 (ref),(ref)用来表示所依赖的是引用对象,而不是普通的类型。如果不加(ref), PropertiesBeanDefinitionReader会将djListener和djPersister作为简单的String类型 进行注入
调用方式:

把reader绑定到registry,然后变成BeanFactory
xml:
,Spring同样为XML 格式的配置文件提供了现成的BeanDefinitionReader实现,即XmlBeanDefinitionReader
- SpringBoot(serviceComb里),这种配置文件到哪去了呢??
3.注解方式#
@Autowired@Autowired是这里的主角,它的存在将告知Spring容器需要为当前对象注入哪些依赖对象。同时如果要使用这个注解,必须在spring配置中增加context:component-scan
这个太常见了。
SpringBoot里配置了context:component-scan吗?
BeanFactory实现原理#
官方关于IOC的参考图: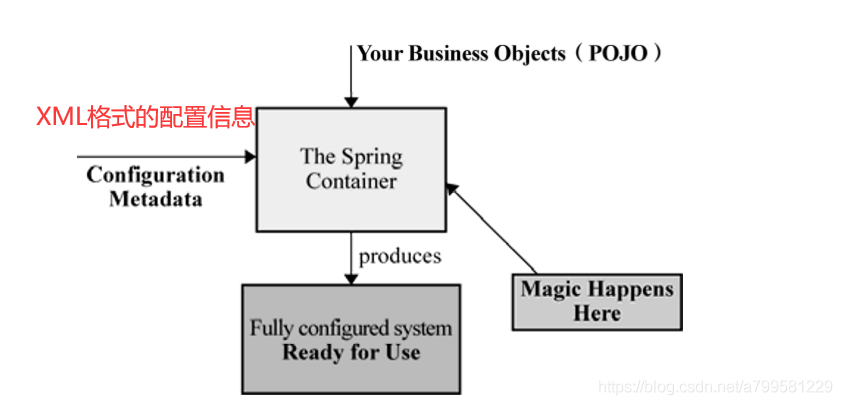
它会以某种方式加载Configuration Metadata(通常也就是XML格式的配置信息)
然后根据这些信息绑定整个系统的对象,终组装成 一个可用的基于轻量级容器的应用系统。
Ioc启动过程#
总共分为2个阶段:
容器启动和实例化阶段。
并且在这里2个阶段中,加入了足够多的可扩展点。
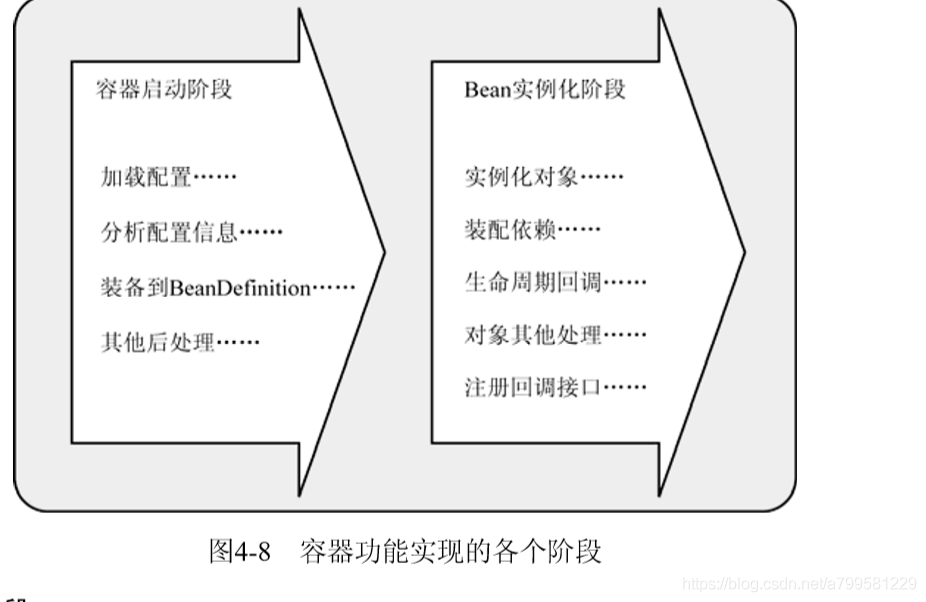
容器启动阶段:#
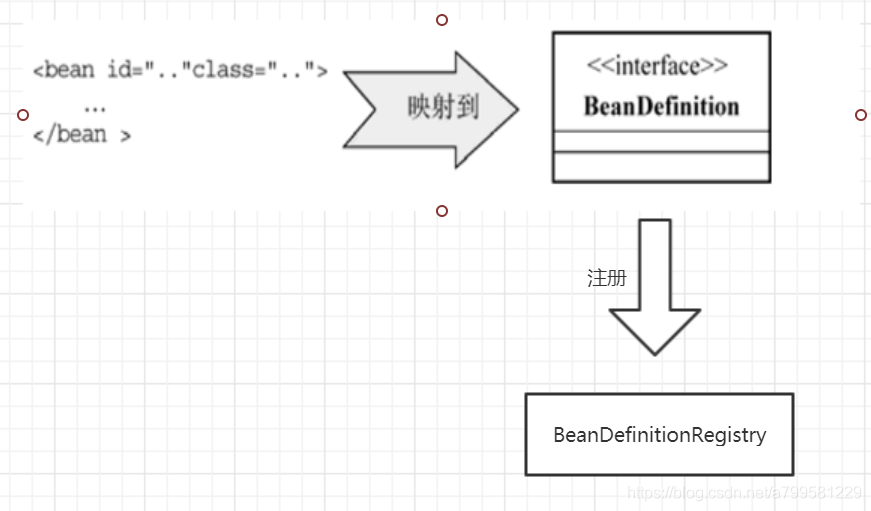
从图里可以看到, Ioc从配置中将需要加载的元素映射成BeanDefintion, 并一一注册到BeanDefinitionRegistry中。
实例化阶段(简单版)#
当某个请求方通过容器的getBean方法明确地请求某个对象,或者因依赖关系容器 需要隐式地调用getBean方法时,就会触发第二阶段的活动。
- 上面这句话可以看到, 不仅仅是getBean会触发,因为依赖所引发的也会进行初始化(有点像Java的Class初始化机制,既可以class.forName(),也可以间接触发?)
实例化的简单过程如下:
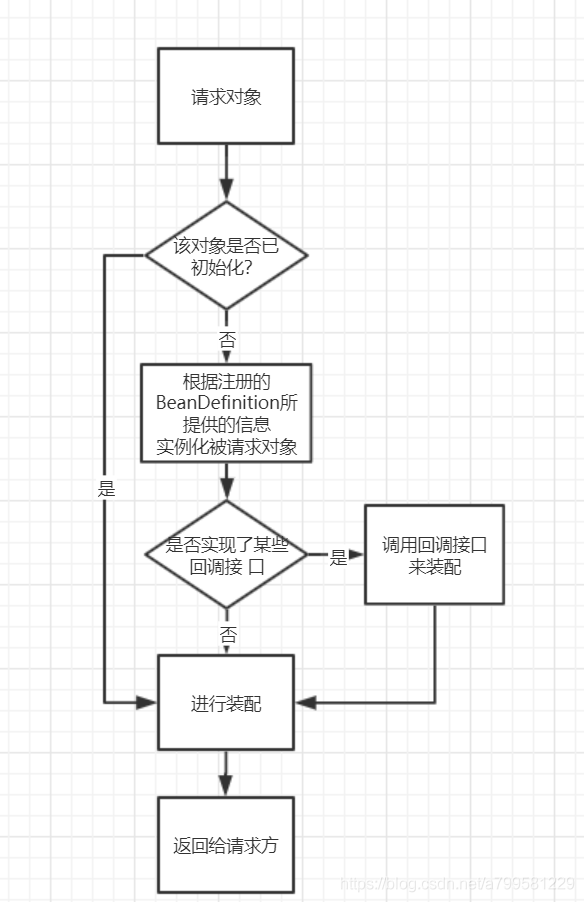
这张图的要点就是:
- 已经初始化过的,就不会再初始化了。
- 如果有一些回调的接口,会去调用再初始化装备
Bean实例化的详细过程:#
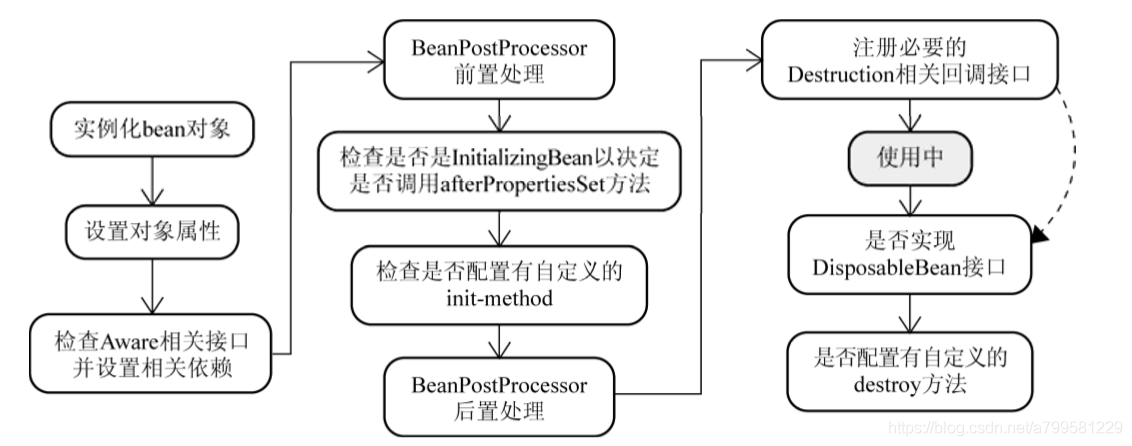
第一步: 实例化,且返回包装类:#
容器在内部实现的时候,采用“策略模式(Strategy Pattern)”来决定采用何种方式初始化bean实例。
通常,可以通过反射或者CGLIB动态字节码生成来初始化相应的bean实例或者动态生成其子类
下面是一些用于初始化Bean时里的接口或者实现类
InstantiationStrategy是实例化的策略抽象接口
SimpleInstantiationStrategy是实现类,只能反射来实例化对象实例,但不支持方法注入方式的对象实例化
CglibSubclassingInstantiation通过CGLIB 的动态字节码生成功能,该策略实现类可以动态生成某个类的子类,进而满足了方法注入所需的对象 实例化需求。(默认都用这个)
PS:确认一下工作项目里用的是什么接口的
- 实例化不是直接返回构造完成的对象实例,而是以BeanWrapper对构造完成的对象实例 进行包裹,返回相应的BeanWrapper实例
第二步:基于BeanWrapper设置成员属性#
实例化BeanWrapper后,会做类似如下操作

- 从这张图可以看到之前为什么说 set注入很好用
这里只要调用setPropertyValue(成员名, 成员) 即可进行注入, 不用去反射特定的方法。
第三步:检查Aware接口#
如果检测到有这个接口,则将这些Aware接口定义中规定的依赖注入给当前对象实例,都是一些特殊元素的注入。
啥意思呢……就是指有一些和Ioc(Bean或BeanFactory)相关的属性,可以通过Aware放进你要实例化的实例中。 这个我记得后面有例子,先略过,只放下几个Spring里的经典Aware:
- BeanNameAware 检测到当前对象实 例实现了该接口,会将该对象实例的bean定义对应的beanName设置到当前对象实例
- BeanClassLoaderAware 会将对应加载当前bean的Classloader注入当前对象实例
- BeanFactoryAware,BeanFactory容器会将自身(即BeanFactory)设置到当前对象实例。这样,当前对象 实例就拥有了一个BeanFactory容器的引用,并且可以对这个容器内允许访问的对象按照需要 进行访问
第四步:BeanPostProcessor处理#
BeanPostProcessor, yyds!
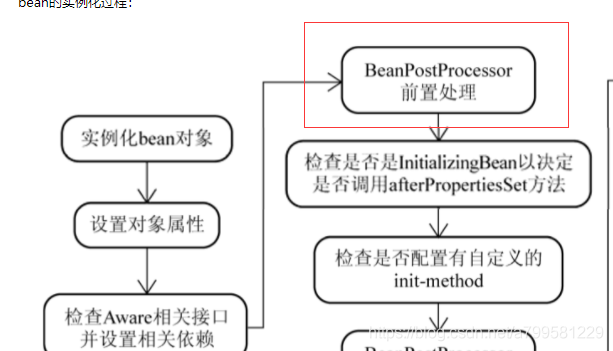
BeanPostProcessor 是容器提供的对象实例化阶段的强有力的扩展点。
BeanPostProcessor和BeanFactoryPostProcessor的区别:
BeanPostProcessor是存在于对象实例化阶段
而BeanFactoryPostProcessor则是存在于容器启动阶段
- BeanPostProcessor可进行实例前处理和后处理,方法为postProcessBeforeInitialization()和postProcessAfterInitialization()
- 通常比较常见的使用BeanPostProcessor的场景,是处理标记接口实现类,或者为当前对象提供 代理实现(注意这个代理,为后面的Aop做铺垫)
例如有个叫ApplicationContextAwareProcessor的, 会做一些和ApplicationContext相关的Bean前置处理(但是注意这时候已经实例化好了,只是还没调用自定义init方法!)
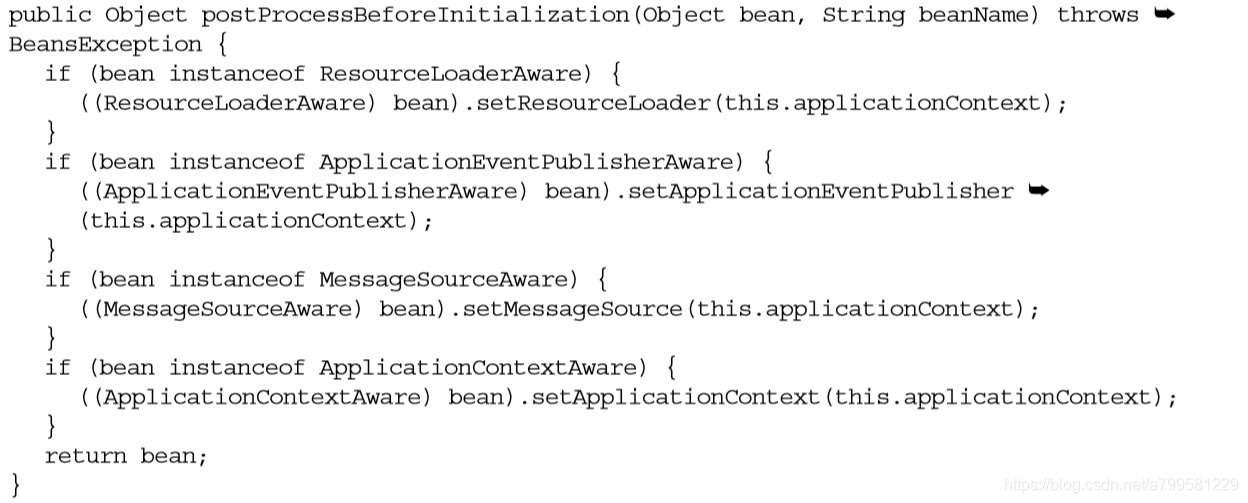
之前用过ApplicationContextAware,来在容器启动时,获取AplicationContext,进行你需要的处理。
书里介绍了一下自定义的BeanPostProcessor步骤,我就贴下里面BeanProcessor的实现:
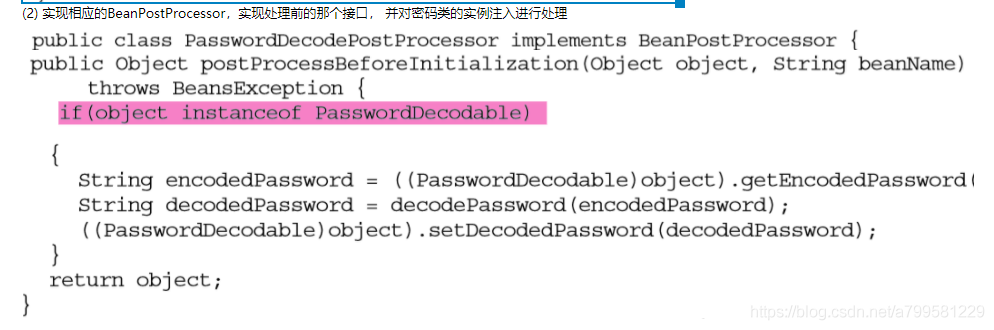
看他就是自己实现了个BeanPostProcessor,然后用instance去判断是不是自己要处理的对象(每个都扫描了一遍~~)
问题: SpringBoot里要自己用代码注册BeanPostProcessor或者写到applicationContext配置里吗?
第五步: 初始化#
“BeanPostProcessor之后, 会检查实例对象是否实现了InitializingBean接口,如果是,调用其afterProper- tiesSet()方法进一步调整对象实例的状态。
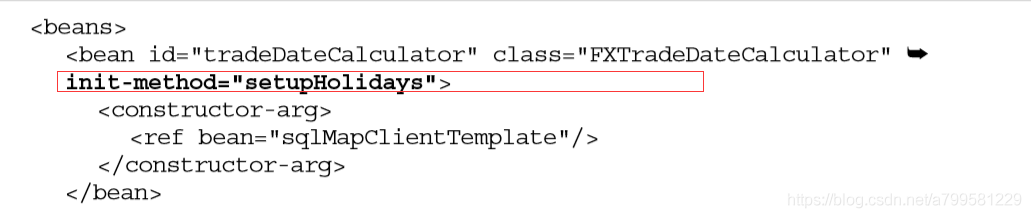
缺点:如果真的让我们的业务对象实现这个接口,则显得 Spring容器比较具有侵入性。
改进:用init-method属性在xml中配置, 选择调用某个已实现方法来做初始化操作,并且不需要初始化时可以剔除。
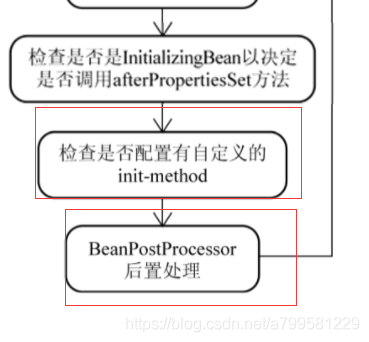
- 注意init的顺序和BeanPostProcessor
六步:注册析构方法#
例如数据池对象,需要在结束时,执行close操作

但Spring容器在关闭之前, 不会自动调用这些回调方法。
所以,需要我们告知容器,在哪个时间点来执行对象的自定义销 毁方法
对于BeanFactory容器来说,调用ConfigurableBeanFactory提供的 destroySingletons()方法销毁容器中管理的所有singleton类型的对象实例。

对于ApplicationContext容器来说 可用registerShutdownHook(涉及底层runtime方法)
保证在Java虚拟机退出之前,这些singtleton类型的bean对象 实例的自定义销毁逻辑会被执行