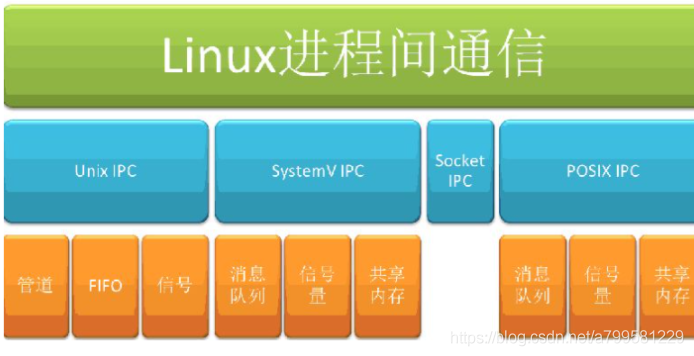
[toc]
Q: 为什么遍历二维数组时,最好是先行后列?#
A:
先行后列是最常见的二维数组的遍历方式,而且效率非常高
因为二维数组的每一行都是一段连续的空间
根据局部性原理,操作系统再访问每个元素时,会将该元素附近多个元素一次性加载到缓存中来提高程序效率。
[toc]
A:
先行后列是最常见的二维数组的遍历方式,而且效率非常高
因为二维数组的每一行都是一段连续的空间
根据局部性原理,操作系统再访问每个元素时,会将该元素附近多个元素一次性加载到缓存中来提高程序效率。
[toc]
原文链接:I/O中断原理
中断指当出现需要时,CPU暂时停止当前程序的执行转而执行处理新情况的程序和执行过程。
即在程序运行过程中,系统出现了一个必须由CPU立即处理的情况,此时,CPU暂时中止程序的执行转而处理这个新的情况的过程就叫做中断。
我们知道CPU是按指令顺序进行执行的,操作系统每过大约15ms会发生一次线程调度(Windows下),根据线程优先级先调度优先级高的线程。但是实际情况并没有那么简单,若我们接收到一个网络请求,如果要等当前线程执行完或15ms线程调度之后才去处理网络请求,网卡缓冲区很有可能会被占满,此时就发生了丢包。
中断分为硬件中断和软件中断。
硬件中断即为硬件发出的中断信号,如I/O中断和硬件失效中断。
软件中断即为非硬件发出的中断信号,如程序中断和时钟中断。
我们提到了操作系统每过大约15ms会进行一次线程调度,就是利用时钟中断来实现的。
I/O中断通过中断处理器执行中断操作。
当外部设备的I/O模块准备好时,它会发送给CPU一个中断信号,CPU则会“立即”做出响应,暂停当前程序的处理去服务该I/O设备的程序。
为了更好的说明中断带来的性能提升,我们先描述一下没有中断时程序如何处理I/O操作。
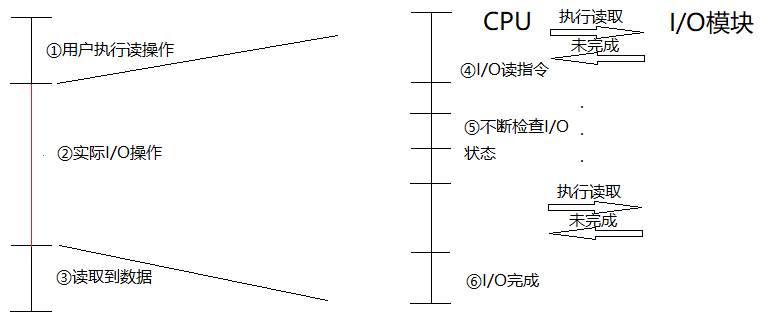
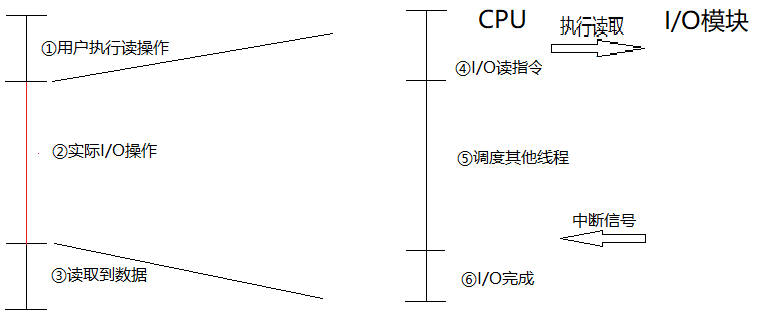
当I/O设备完成一次I/O操作时,发生以下事件:
[toc]
全景流程图:
[toc]
文件是以计算机硬盘为载体的信息集合
需要提供文件系统进行管理
按逻辑结构可以分为2类:
? 无结构文件: 一般都是二进制文件流文件,直接按顺序封装。这里面不包含记录的概念
? 有结构文件: 包含记录的概念
顺序文件:按记录中的某个关键字排序过,可二分查找记录行
索引文件: 需要1个索引表,记录每个记录的位置
索引顺序文件:先按关键字索引,在部分擦护照
直接、散列文件:用哈希键值确定记录位置
名称
标识符——确认文件唯一性
类型
位置——设备文件指针
大小——文件大小或者文件最大值
保护——访问控制权限
时间、日期
用户标志——哪个用户可用
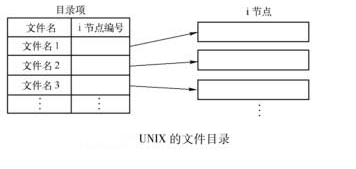
目录就是文件的外部组织结构
存放文件描述信息, 但是不包含文件名
文件目录中只存放文件名和i节点指针
可减少外村磁盘的查找速度
节点内容包括:
标识符、类型、权限、存取时间
地址长度、链接计数
节点编号、状态(是否上锁)
访问计数、设备号
文件打开时,会把索引节点从磁盘复制进内存,称为内存索引节点
只需要文件位置信息等时,只需要拿文件控制块来唯一确认一个文件即可。
但是需要真正使用文件时,则需要索引节点里的信息
但如果把索引节点提前加载进内存的话,容易导致开销浪费。所以只有需要的时候,才回去用到索引节点,减少要拷贝的信息。
单级目录
两级目录
多级目录:树形结构,有相对路径和绝对路径
从用户层从上往下排列
线性列表——宠用目录项, 顺序检索。
哈希表——根据文件名得到key值
linux的目录实现原理:
符号链接
建立一个文件, 文件中存放共享文件的路径
只有文件拥有者才能有指向文件的i节点指针
不会出现指针悬空, 不存在时,软链接会被删除。
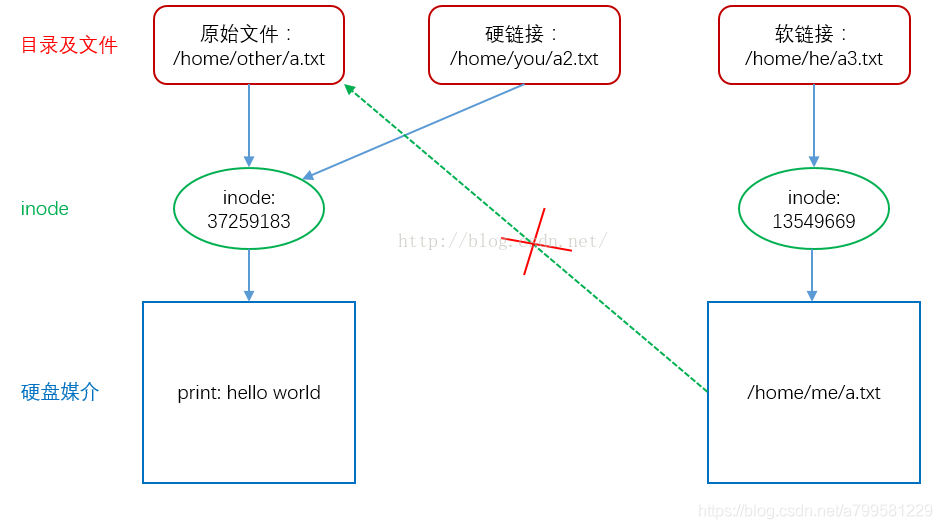
即一个文件名的指针
各用户文件目录表用i节点指针指向同一个索引节点
当文件被删除,另一个用户就不能访问了。
容易出错。
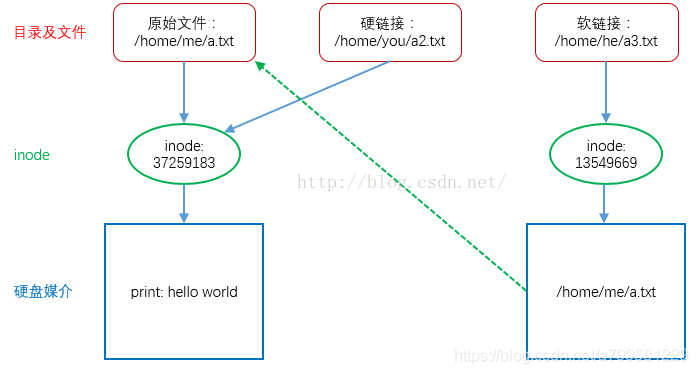
指怎么给文件分配磁盘块
每个文件在磁盘上占一组连续的块
目录项记录文件的起始位置和长度
这样能让作业的磁盘寻道数最少
适用于长度固定的文件
隐式链接:
每个文件有一个链表, 每个节点是一个磁盘块,next指针指向下一个磁盘块
显式链接:
用一个二维数组表替代next指针, [0]是盘块,[1]是下一个盘块
这个表就是文件分配表FAT
文件的第一个盘号也就是链表头 会放入FCB的物理地址中
为了防止这个表占据太大空间或者不够用
给每个文件有一个索引表,按顺序给出盘块
同时可以多级索引, 即可以给出磁盘中下一级索引表的盘块号。然后再去把盘中的二级索引表导入到内存中使用
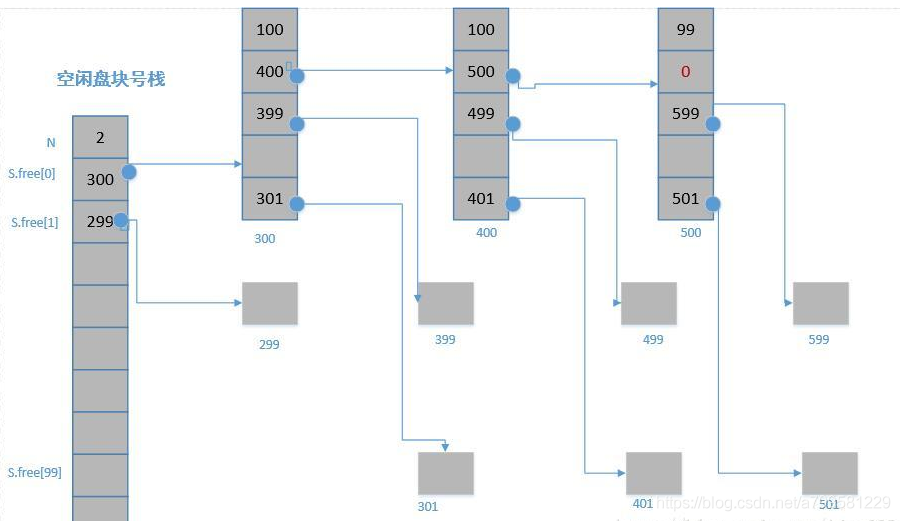
即把哪些磁盘块分给文件呢?
以下是空闲块分配方法:
[toc]
根据磁头动作,可以分为 固定头磁盘 / 活动头磁盘
根据磁盘是否固定,可分为 固定盘磁盘 / 可换盘磁盘
这个时间是衡量磁盘设计好坏的重要因素
寻找时间Ts (先找磁道,即找在圈里的第几层)
指找到磁道的时间
Ts = 0.2ms * 跨越磁道数 + st(磁臂启动时间,即扫描的那个东西开始动的时间)
延迟时间(磁道找完,定位扇区,即在圈上的哪个方位)
定位置某一扇区的时间
转一圈的时间/2作为延迟时间, 即对转一圈的时间求个平均(毕竟实际速度和扫描算法有关)
Tr = 1/2r
传输时间(找到位置了,接着开始读数据)
就是读写数据时间
扇区占一圈的几分之几 * 转一圈的描述
其实就是磁臂按正常速度扫完这个内容要花的时间。
其实就是收到多个盘块的请求,选择扫描磁道的方法
磁盘的启动程序会放在磁盘的引导块上
对于损坏的磁盘块, 他会检测并避免再使用这些坏块。
DMA会设置4个寄存器:
命令/状态寄存器CR——用于接收CPU发来的控制命令,存储当前状态
内存地址MAR——存放内存地址
数据寄存器DR——暂存数据
数据计数器DC——用于传输计数
工作过程:
DMA和中断的区别
- DMA:是一种无须CPU的参与就可以让外设与系统内存之间进行双向数据传输的硬件机制,使用DMA可以使系统CPU从实际的I/O数据传输过程中摆脱出来,从而大大提高系统的吞吐率.
- 中断:是指CPU在执行程序的过程中,出现了某些突发事件时CPU必须暂停执行当前的程序,转去处理突发事件,处理完毕后CPU又返回源程序被中断的位置并继续执行。
所以中断和DMA的区别就是DMA不需CPU参与,而中断是需要CPU参与的。
从上往下介绍
磁盘高速缓存: 在内存中开辟单独空间,利用未利用的页做缓冲池
缓冲区的目的:
减少CPU\IO速度的不匹配
减少CPU中断
提高IO和CPU的并行性
缓冲分类
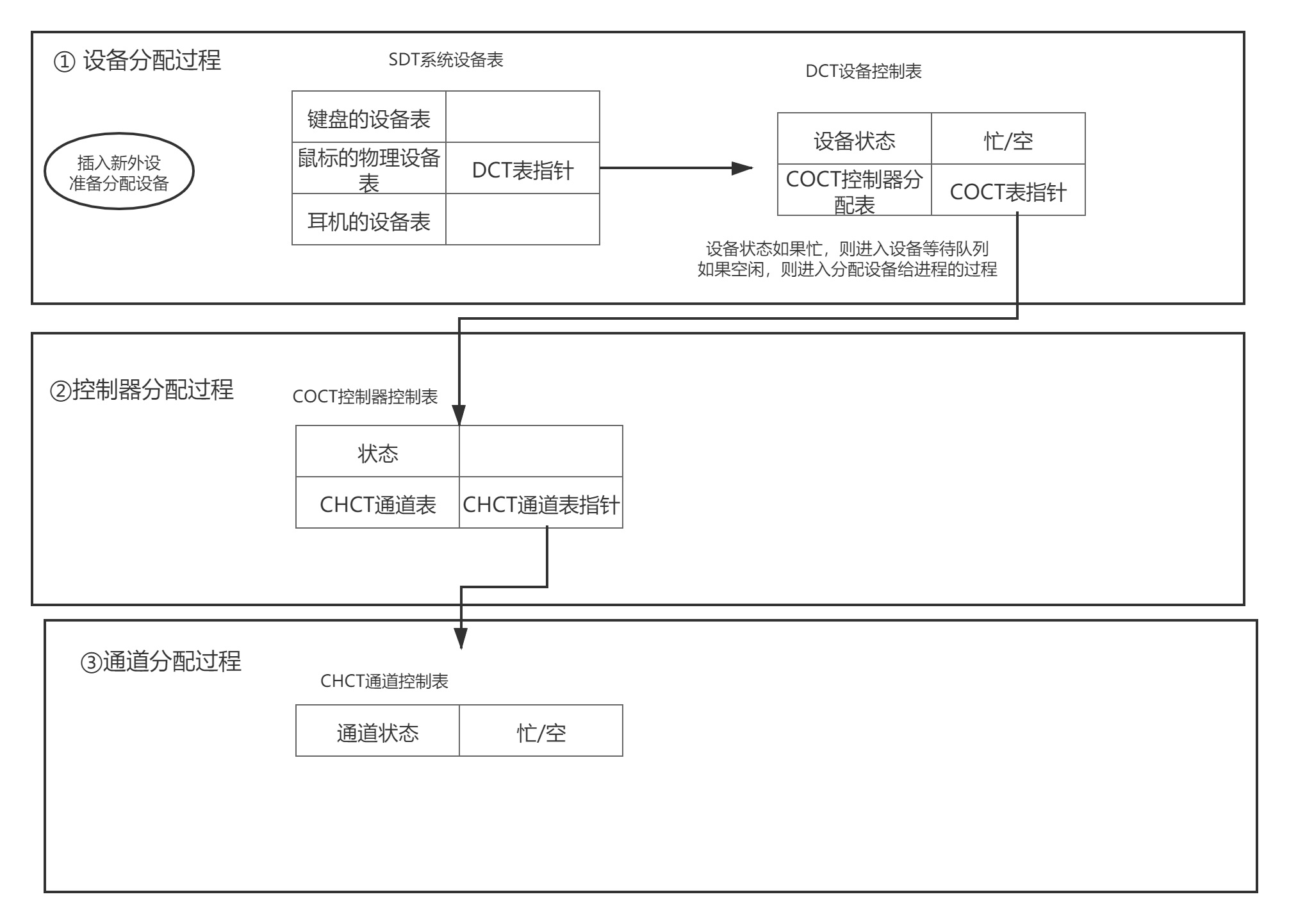
设备分配分类
设备分配表
DCT设备控制表—— 1个控制表代表一个设备。
COCT控制器控制表——与内存交换数据。请求通道服务——指向CHCT
CHCT通道控制表
SDT系统设备表——记录系统中已连接的设备情况
以向 I/O 设备写数据为例子,做出概念图,如下所示:
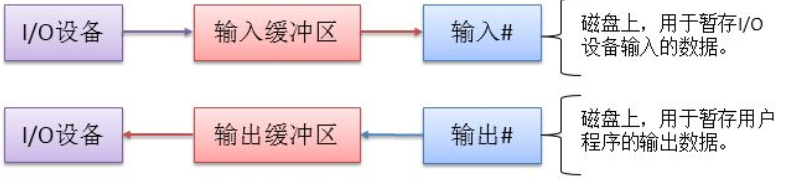
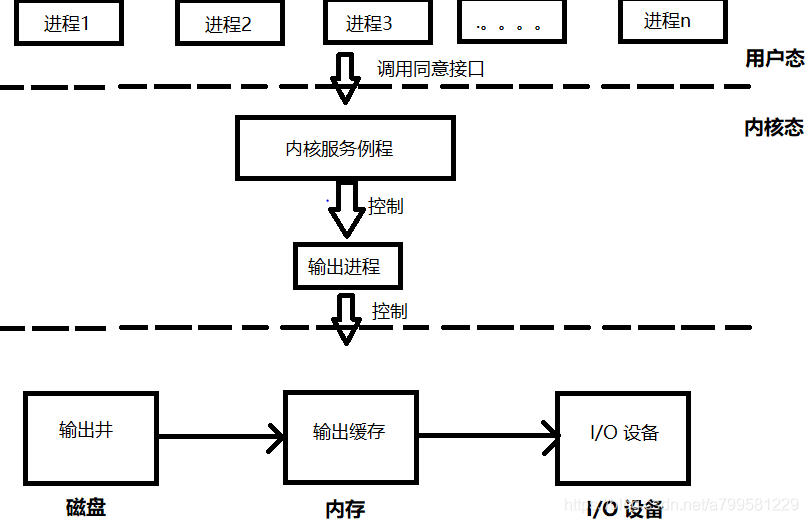
首先某一个进程(例如 word)调用了统一的接口,然后进入内核。内核例程负责将 word 想要打印的内容做成一个打印申请表,将这个申请表放入打印输出队列中(这个队列在输出井中)。然后由输出进程从打印队列中取打印申请表,根据表格内容将用户数据从磁盘中取出放入内存输出缓冲区,然后再输出到 I/O 设备中。输出进程会不断的查看打印输出队列,直到队列为空,则输出进程被阻塞。
即对于进程来说,看起来都已经输出或者输入了,实际上看还没有响应,有延迟,物理上共用1个设备。逻辑上是2个设备
A:
阻塞,对应的是执行线程会被挂起,线程时间片暂停执行,有结果了才返回。
非阻塞,线程不会挂起,而是直接返回结果或者异常,让线程调用者自己确认是否完成了读取,因此线程不会挂起。
阻塞和非阻塞的区别就在于:是否需要线程自己轮询检查
A:
同步, 调用Io方法时, 必须等结果返回,这个方法才会结束。
异步, 调用io方法时, 不需要等结果。 由接收方进行异步的通知或者发请求,因此线程可以作别的事情了。(与非阻塞IO不同)
同步和异步的区别就在于:是否通过回调函数进行通知确认结果。
综上可知,同步和异步,阻塞和非阻塞,有些混用,其实它们完全不是一回事,而且它们修饰的对象也不相同。
A:

[toc]
内存管理指操作系统对内存的划分和动态分配
地址空间:
逻辑地址空间: 相对地址, 从0开始编址
物理地址空间: 地址转换的最终地址
程序运行时和
编译: 吧源代码编译成目标模块
链接: 吧目标模块、库函数链接成1个装入模块
链接属于形成进程逻辑地址的过程
装入:
绝对装入: 编译时就确定了装入地址
可重定位装入: 根据内存情况, 把程序装到适当位置
运行时动态装入:运行前才真正把程序装起来(前面2个都是先分配,再装,再运行)
即怎么防止内存越界
重定位+界地址:
重定位寄存器——存放物理地址的最小地址
界地址寄存器——存放逻辑地址的最大值
先把访问地址(相对地址) 与界地址比较是否越界
再加到重定位寄存器上,作为物理地址
min + x, 且x <max, 这样保证地址在min到min+max之内
连续分配指 为用户程序分配的内存空间一定是连续的
内存分为系统区和用户区2个区
每次用户区只能放1个程序, 这样可确保不会越界
用户区分成若干个大小的分区, 每个分区只能装一个作业。
程序如果大了会装不下
程序小了则有内存碎片
程序装入内存时,按照所需大小动态生成1个分区。 有多少碎片空间就给多少
可能会存在碎片, 比如中间的进程结束了, 于是中间就空出来一个内存碎片,而可能因为太小,其他进程帆布进来。
动态分配策略:
非连续指进程内存可以 分成不同地址存放,不一定全部集中在一起。
把内存划分成固定大小的块, 进程以块为单位申请多个不同位置的块作为空间。
进程每次想通过虚拟地址去定位物理地址时,都需要先去页表中找到虚拟地址对应的页,然后再得到物理地址。
快表TBL(Translation Lookaside Buffer )):
为了避免每次斗取页表换算地址, 快表会缓存 虚拟地址->物理地址的直接映射,加快速度
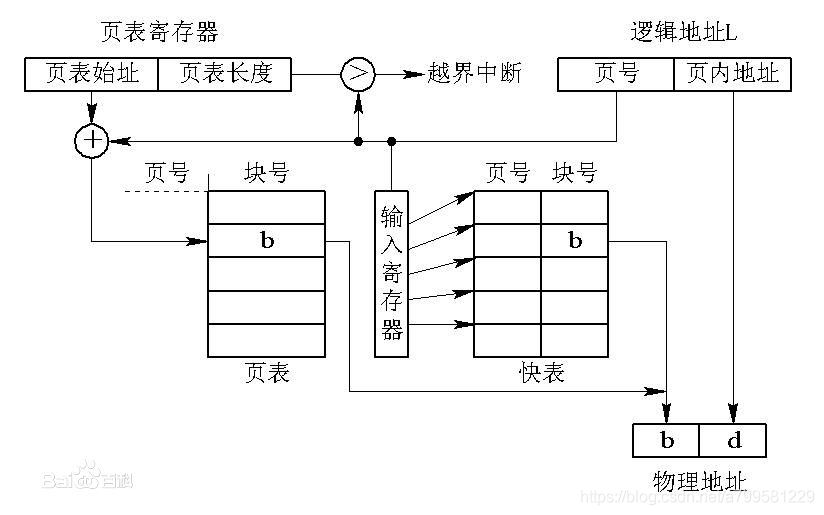
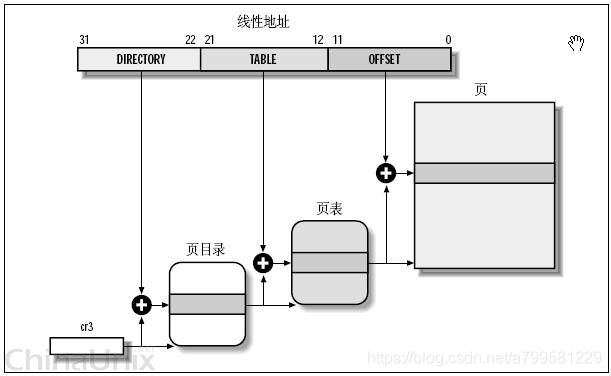
多级页表
地址空间超级大, 1页装不下怎么办?
用多级
一级页表指明二级页表的地址
二级页表再去实际地址
这样就可以有多页了。
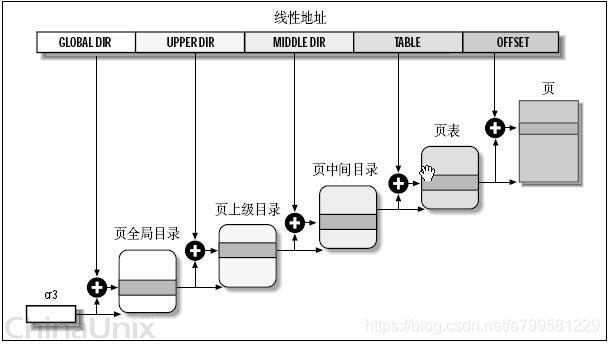
分页的话, 页的长度时固定的, 所以偏移量的最大值是固定的
分段的话不限制偏移量最大值,即可以很长一段。
分段属于二维地址空间, 因为他除了给出逻辑地址,还得给出段长
有利于做动态链接: 程序动态修改
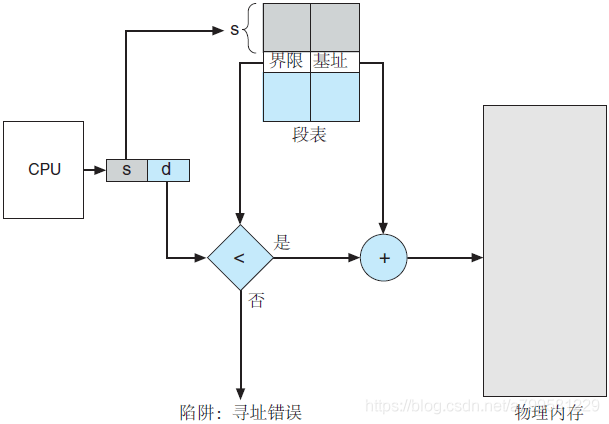
作业先分成若干段, 再把段分页, 每个段可以找到一个也变
段号S 页号P 页内偏移
Q: 遍历二维数组的时候, 行遍历优先和列遍历优先的效率差别, 为什么会这样
A: 按行遍历比按列遍历的效率高体现在这些方面:
虚拟地址可以让进程获得比实际内存要大的内存
特征:
要求:
必须使用非连续分配方式——分页、分段、段页
硬件需要支持 页表、中断、地址变换机构
理论依据:
时间局部性—— 指令和数据总是会在一段时间内被连续访问
空间局部性——某单元被访问,那么他附件的单元也很大概率会被访问
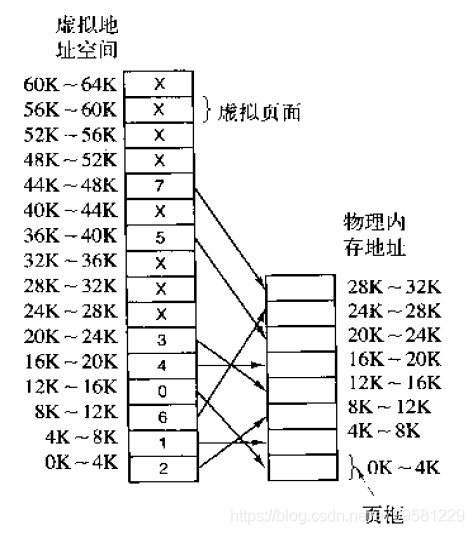
再分页的基础上, 增加了2个功能:
请求调页——当页面不在内存中时,从外村申请调入
页面置换——把暂时不用的内存换出去,给其他需要进来的页腾出空间
页表项:
页号、物理块号
状态位P:是否已经调入内存
访问字段A: 记录访问次数或者访问标记,用于置换策略判断
修改维 M: 记录是否被修改过
外村地址——当页被换出去时,指明这个页在外存的何处
缺页中断机构: 当页面不存在时, 负责产生缺页中断,进行页面置换操作。
缺页只能高端和系统中断不同, 属于指令中的操作,在执行期产生多次
地址变换机构:
1.先检索快表,如果能找到,则直接修改页表项的访问位。
2.快表中没有,则去 再检索内存中的页表,通过状态为P确认是否在内存中
如果不在,则产生缺页中断。
驻留集:指系统给每个进程分配的内存中实际页面集合
但是可能分配了10个, 却只有5个经常在用
工作集: 某时间段内,这个进程访问和使用的页面集合
通过工作集, 系统可以评估这个驻留集是否需要做删减,以及哪些页应该持续保留。
这样可以减少抖动,即减少内外村之间频繁的交换页
较早调入的页往往是经常被访问的页,这些页在FIFO算法下被反复调入和调出,并且有Belady现象。所谓Belady现象是指:采用FIFO算法时,如果对一个进程未分配它所要求的全部页面,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。
如果需要换页时,步骤如下:
分配来源:
对换区:频繁切换的区
文件区:补怎么会变动和修改的
[toc]
从就绪队列中选一个进程分配给处理机
处理机调度是操作系统进行多道程序运行的核心
操作系统中有三种调度:
分别是从高级到低级, 频率从低到高
剥夺式调度: 按优先级、短时间、时间片进行抢占式调度,会强制暂停某些进程
非剥夺调度: 当某个进程完成,或者出现阻塞,才会重新分配CPU。 不可用于分时和实时系统。
linux属于剥夺还是费伯多?
CPU利用率: CPU运行时间/ 空闲时间加运行时间
系统吞吐量: 单位时间内完成的作业数量
周转时间: 从提交到作业完成的时间, 包括了等待\IO等
等待时间: 在就绪队列中等待的时间之和
响应时间: 从提交请求到系统首次擦还是你哼响应的时间。
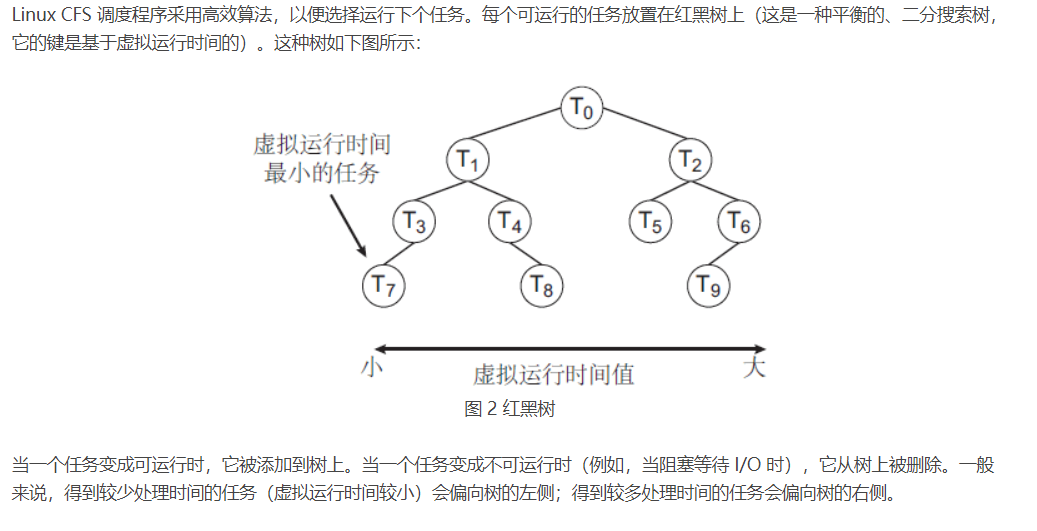
Linux 标准内核实现两个调度类:采用 CFS 调度算法的默认调度类和实时调度类.
CFS 调度程序并不采用严格规则来为一个优先级分配某个长度的时间片,而是为每个任务分配一定比例的 CPU 处理时间。每个任务分配的具体比例是根据友好值来计算的。友好值的范围从 -20 到 +19,数值较低的友好值表示较高的相对优先级。具有较低友好值的任务,与具有较高友好值的任务相比,会得到更高比例的处理器处理时间。默认友好值为 0。
[toc]
不同进程之间需要相互制约,或者存在先后顺序,就会用到同步。
同步: 也称作直接制约关系
为完成某个任务,多个进程需要协调工作次序并等待,即这个制约关系应该是意料之中出现的。
互斥: 间接制约关系
因临界资源冲突而引发访问和等待,即不是他想要的制约关系。
同步机制准则:
空闲让进: 资源空闲的时候允许进入
忙则等待: 临界区被占用,其他等待
有限等待: 不能一直等待,出现出现饥饿
让权等待: 无法进入临界区时,要放弃CPU挂起一段时间,避免一直占用CPU
共享资源数目有限时一般使用信号量。
P操作——wait 申请和获取资源
先减去信号量,再判断, 如果信号量<0,则进程加入阻塞队列
V操作——signal 释放资源
每次操作时,直接增加信号量
此时说明已经有人空闲了一个资源了。
当发现信号量此时<=0, 则从阻塞队列里选一个出队
在内存中而非外村中
是一个共享数据结构
1次只允许1个进管道
可以理解为信号量变成了 只有1的管道
为满时,不可写
为空时,不可读
管程和信号量的区别:
1、信号量可以并发,并发量是取决于s的初始值,而管程则是在任意时刻都是只能有一个。
2、信号量的P操作在操作之前不知道是否会被阻塞,而管程的wait操作则是一定会被阻塞。
3、管程的进程如果执行csignal后,但是没有在这个条件变量上等待的任务的话,则丢弃这个信号。进程在发出信号后会将自己置于紧急队列之中,因为他已经执行了部分代码,所以应该优先于入口队列中的新进入的进程执行。
4、当前进程对一个信号量加1后,会唤醒另一个进程,被唤醒进程程与当前进程并发执行
简单的信号量模型
读可以并发读
写的话,必须等读的人都结束了才能写。
每个人都先拿自己最左边的筷子,就会吃不上饭
1次拿2双即可,而不是先拿左手,再拿右手。
3种原材料的供应问题
每个人只有1种材料。
但是吸烟要3种材料。
供应者用完了再上新的
于是吸烟者每次要直接拿2个,而不能1次只拿1个。
根据上面4个条件,可以给出4个预防措施
该方法不会影响资源分配。 只会定时地去检测,然后看是否解除某些死锁
以进程和资源构建一张DAG图
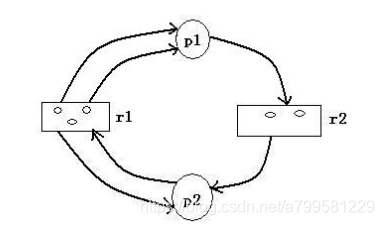
这个算法会影响分配过程,即在资源分配前判断以下。
假设进程数量有n个
假设资源有r种
定义以下数组
各资源当前可用数量 Avaialbe[r]
各进程最大需求 max[n][r]
各进程当前已占资源 allocation[n][r]
各进程还需要的资源量 need[n][r]
此时的某进程i对各资源的请求量 request[r]
银行家算法描述:
安全性算法描述:
按顺序,每次把进程剩余need的资源都占去,并剪掉avalid, 看下遍历完是否会出现不够用的情况
这个 同步 的概念都是一致的. 不论是进程还是线程.
不同在于所采用的同步方式, 进程的同步方式是线程的同步方式的子集. 换句话说, 进程之间的同步方式会比线程之间同步方式选择小. 就这样而已.
线程通信一般是指同一进程内的线程进行通讯,由于在同一进程内,共享地址空间,因此交互比较容易,全局变量之类的都能起到作用。
进程通信一般是指不同进程间的线程进行通讯,由于地址空间不同,因此需要使用操作系统相关机制进行“中转”,比如共享文件、管道、SOCKET。
linux的死锁检测、避免机制Lockdep
http://kernel.meizu.com/linux-dead-lock-detect-lockdep.html
[toc]
一般会有2种线程:
ULT和KLT的映射关系分类(即用户线程能给哪些系统线程管理):
linux用的是哪种呢?
A:
[toc]
是资源分配、调度的独立单位
进程包含以下内容:
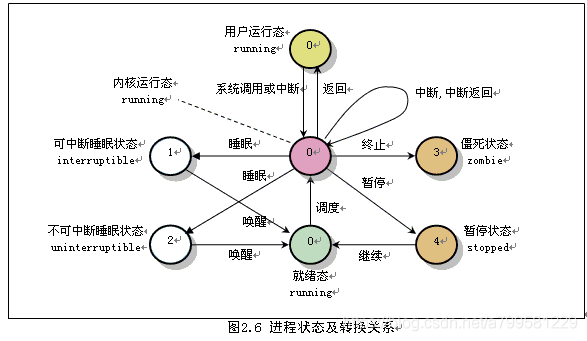
进程具有动态性,是一个动态的概念。
每个进程具有独立的PCB结构, 资源也独立。
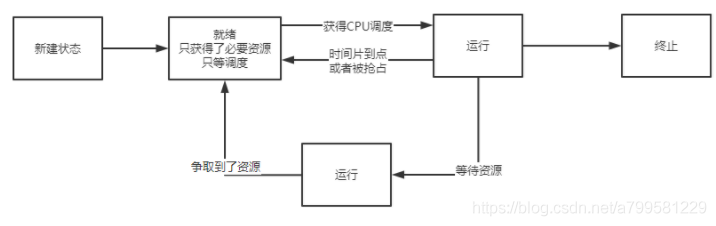
终止有3种触发情况
终止的触发过程:
阻塞的过程:
唤醒的过程:
上面可以看到基本是围绕 PCB、等待队列、就绪队列、进程状态更新这4个概念展开的。
注意调度是一个决策行为, 而切换是一个执行行为, 因此都是先调度,再切换。
pcb控制块在进程创建后, 就常驻内存中
是进程的唯一标志
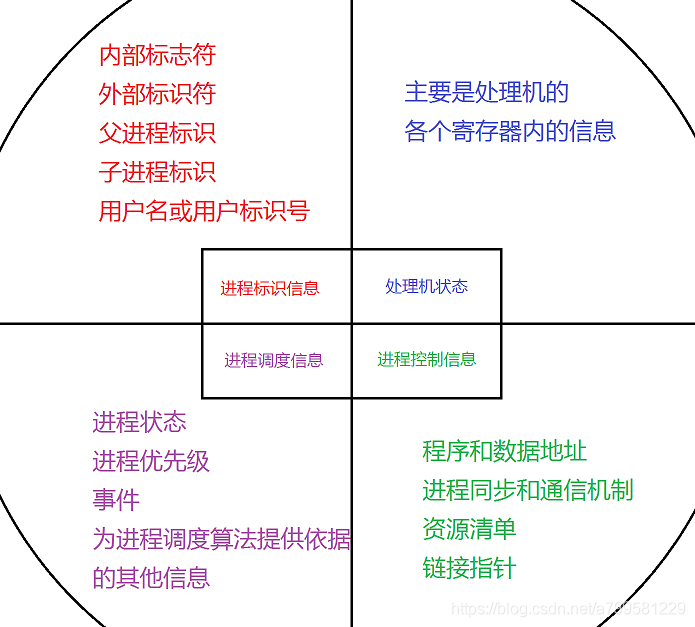
PCB控制块包含以下内容:
PCB控制块的组织方式:
进程的通信有3种方式
共享存储方式
由操作系统系统存储空间调用方式。
注意用户进程的空间是互相独立的,不会互相访问。
消息传递
直接通信: 发送到对方的消息队列,从消息队列去
间接通信: 发信到中间邮箱(非双方进程), 接收方自己去取。
管道通信:
管道: 链接读写进程之间的共享文件
功能为互斥、同步
属于一次性操作, 一旦被读取,数据就被从管道中抛弃
半双工, 只有1方能操作,要么存入要么写。
如果要实现双方互动,则需要2个管道。