[toc]
总线
1概念
总线是连接多个部件的信息传输线
各部件共享的传输介质(多个组件共用1条总线)
1.1设备概念:
主设备——当前获得总线控制权的设备
从设备——被主设备访问的设备,只能响应
1.2特点:
分时: 同一时刻只允许一个组件发送消息
共享: 可多个线同时接收信息
2 总线分类
2.1 按结构分类
2.1.1 单总线
内存、CPU、I/O都连接同一根线
发生抢占时,需要让总线判断优先级
且不适用单周期指令,1个时钟周期内没法传输地址+数据
2.1.2 面向CPU双总线
总共两根线,分别是
- M内存总线(CPU与内存之间的总线)
- I/O总线(I/O和CPU的总线)
缺点:
当希望从IO直接传给内存时,需要先经过CPU
2.1.3 三总线
以内存为中心
CPU<–> Memory <–> I/O
CPU和Memory之间可能存在DMA进行高速交互。
2.2 按连接部件分类
2.2.1 片内总线
指在芯片内部的总线
比如CPU内部、寄存器之间、ALU与寄存器
2.2.2 系统总线
连接CPU\主存、IO的总线
数据线: 传送指令、数据、中断信号
地址线: 访问主存或者IO,由CPU单向通往内存。 位数决定地址空间
控制线: 监控和维护各部件状态, 传送应答信号
2.2.3 通信总线(外总线)
计算机和其他系统之间的总线(计算机外部的)。
猝发传输: 一次性传输存储地址下的多个字
3. 性能指标
- 传输周期/总线周期 —— 一次总线操作所需的时间
- 总线宽度——数据总线的根数(并非地址总线)
- 时钟同/异步——和CPU时钟是否同步工作
- 总线复用—— 能否在1根总线中复用地址和数据的功能
- 信号线数——地址、数据、控制 三线总和
- 控制方式—— 突发控制/计数控制/配置控制
- 其他指标—— 负载能力/电源电压/宽度扩展性
4. 总线标准
总线标准, 指 系统和模块间的互连标准, 只要求自身与接口一致即可, 不一定要求所有线都一样。
- ISA—— 独立于CPU的总线时间
- EISA—— 和ISA兼容, 主线控制权不由CPU决定
- VESA—— 局部总线, 使用高速信息传输通道
- PCI——局部总线, 猝发传输
- AGP——显卡专用总线, 双激励,时钟上下沿都可以传输
- RS-232C——用于DTE终端设备和DCE数据通信设备。 解/调码器之间的那根线
- USB——设备总线, 连接设备与设备控制器
- PCI\AGP\PCI-E 负责连接 主存、网卡、视频卡之类内部局部总线
5. 总线仲裁
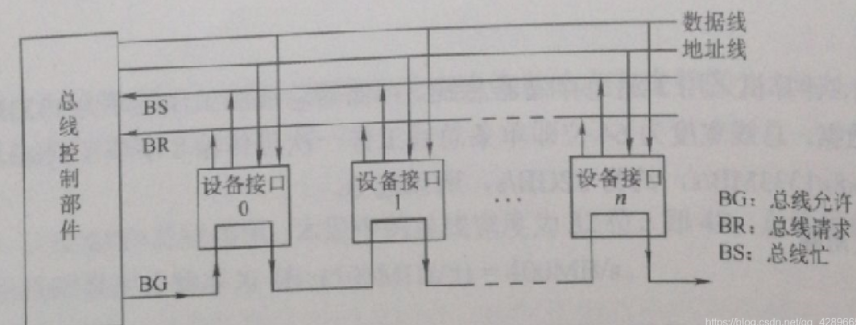
5.1 判优控制
主设备才有优先级之分
主线才能传输数据。
- 集中式总线: 控制逻辑集中于CPU,利用一个特定的裁决算法进行裁决
- 分布式总线: 优先逻辑分散到各部件
集中式仲裁方式如下:
5.2 链式查询
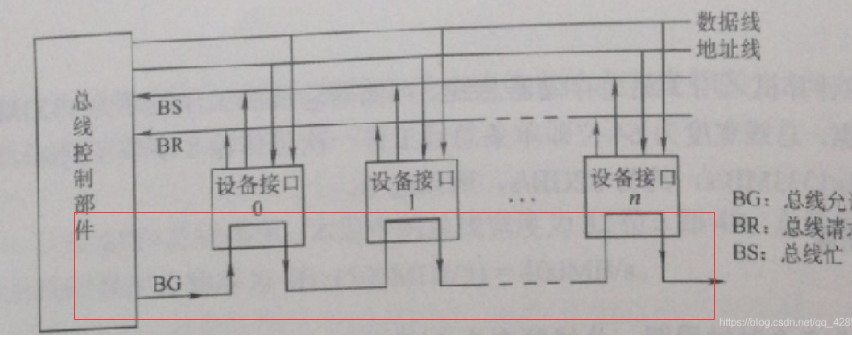
- 总线上所有的部件共用一根总线请求线,当有部件请求使用总线时,需经此线发总线请求信号到总线控制器,总线控制器便查询总线是否忙碌,如不忙碌便立即发总线响应信号到 BG 线串行地从一个部件传送到下一个部件,依次查询,直到某个部件有总线请求便不再传下去。
- 此方式下,部件离总线控制器越近优先级越高,离总线控制器越远则优先级越低。
- 优点:优先级固定,只需较少的控制线就能按一定优先次序实现总线控制,结构简单,扩充容易。
- 缺点:对硬件电路的故障敏感,且优先级不能改变,这要极易导致当优先级高的部件频繁请求总线时,优先级低的部件长期不能使用总线。
5.3 计数器定时查询(n根)
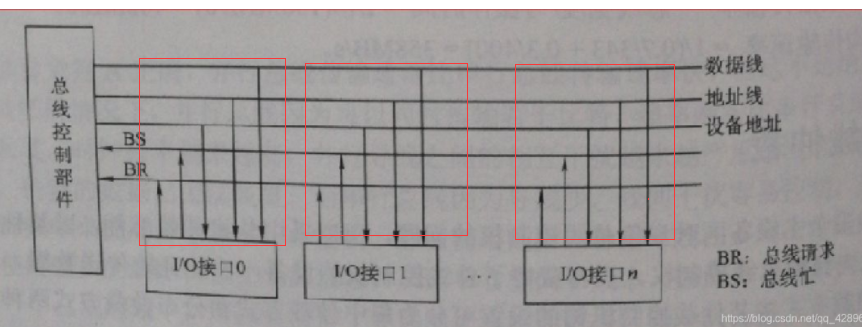
仍是共有一根总线请求线。
- 工作原理如下,当总线控制器收到总线请求信号并判断总线空闲时,计数器开始计数,计数值通过设备地址线发向各个部件,当地址线上的计数值与请求使用总线设备的地址一致时,该设备获得总线控制权,同时中止计数器的计数及查询。
- 优点:计数器计数可从“0”开始,当设备优先次序固定,则设备优先级就按0,1……的顺序排列,固定不变;计数可以从上一次的终点开始,即采用一种循环方法,此时设备使用总线的优先级相等;计数器的初值还可由程序设置,因此优先次序可以改变,且这种方式对电路的故障不那么敏感。
- 缺点:增加了控制线,若设备有 n 个,则大致需要 ?log_2?n ?+2条控制线,控制也比链式查询复杂。
5.4 独立请求
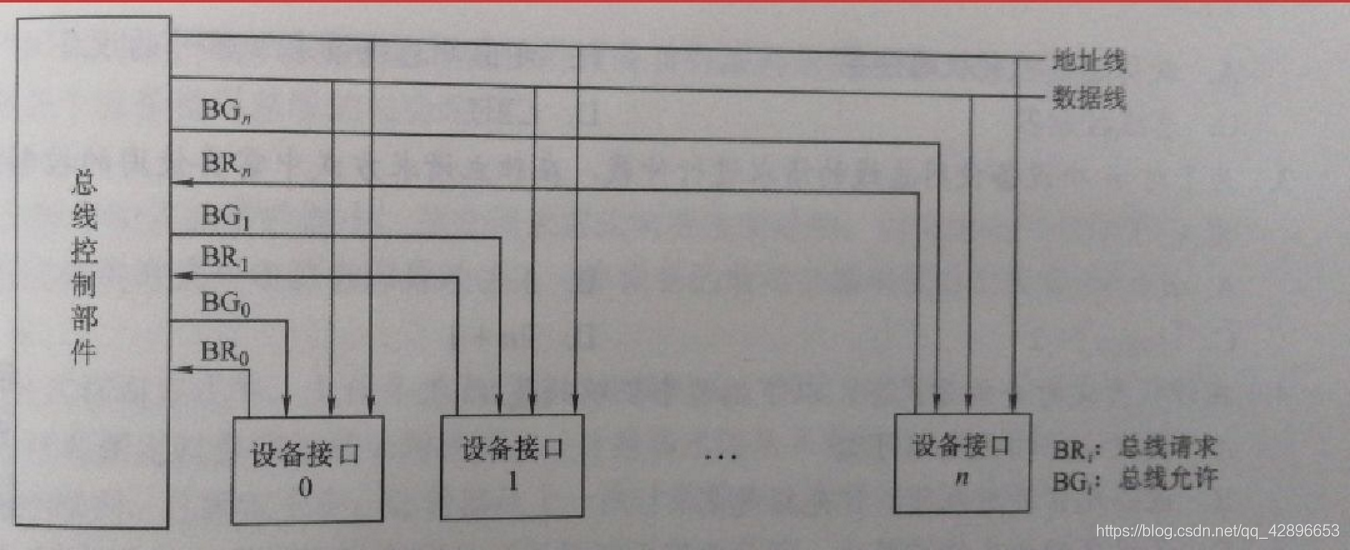
- 每个设备都有一对总线请求线和总线允许线,当部件需要使用总线时,经各自的总线请求线向总线控制器发送总线请求信号,在控制器中排队,总线控制器按一定的优先次序决定批准某个部件的请求,并经该部件的总线允许线向该部件发送总线响应信号,将总线控制器交给该部件。
- 优点:响应速度快,对优先次序的控制相当灵活。
- 缺点:控制线数量多,若有设备 n 个,则需要 2n+1 条控制线,其中的 1 是指反馈线,用于让设备向总线控制器反馈已经使用完总线;总线控制逻辑复杂。
5.5 分布式仲裁
分布仲裁方式不需要中央仲裁器,每个潜在的主模块都有自己的仲裁号和仲裁器。
当它们有总线请求时,就会把它们各自唯一的仲裁号发送到共享的仲裁总线上,每个仲裁器从仲裁总线上得到的仲裁号与自己的仲裁号比较。
若仲裁总线上的仲裁号优先级高,则它的总线请求不予响应,并撤销它的仲裁号。最后,获胜者的仲裁号保留在仲裁总线上。
通信方式
总线周期的4个阶段
申请分配——寻址——传数据——结束
同步通信
按照4个周期上升沿才执行,主从设备完全按照周期执行
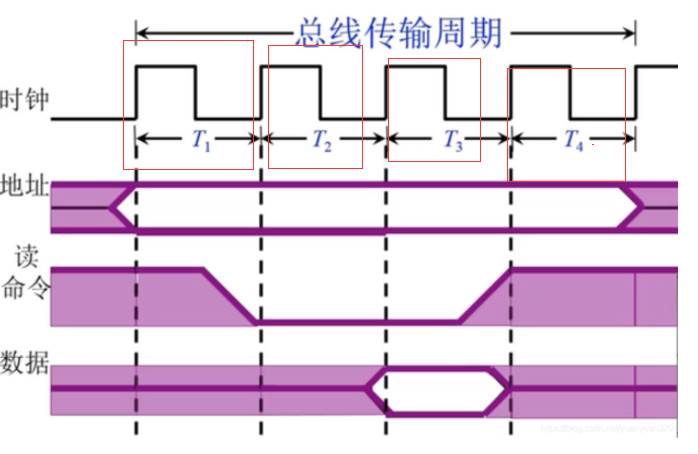
读: 发地址->发送读命令->读取数据->撤销占用
写:发地址->提取数据->发送写命令->撤销
用于存取时间比较一致且短的场合
异步通信
不会一定要主从设备按照一样的周期执行
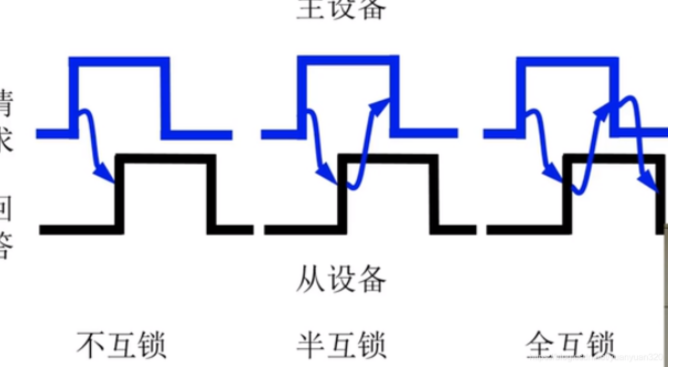
- 不互锁: 不用接收应答,按时间撤销
- 半互锁: 主模块接收应答才撤销——共享存储器
- 全互锁: 主从都要应答,类似TCP的应答方式
半同步通信
和同步类似, 但是在命令和数据周期内增加了Tw等待周期。
发送方用系统时钟前沿法信号
接收方用后沿判断和等待
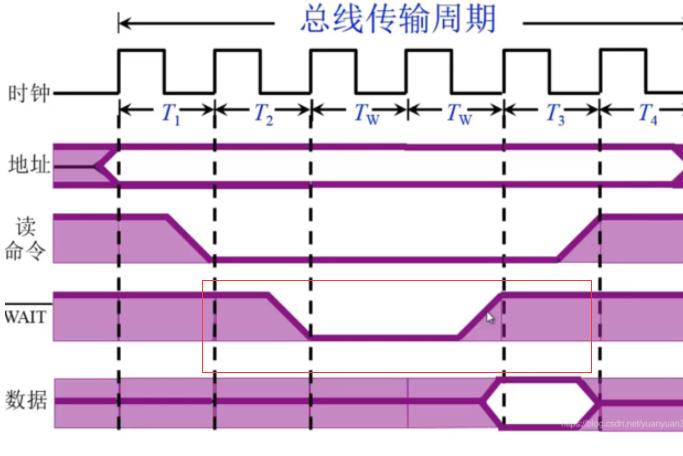
以上三种通信的共同点:
(1)主模块发地址、命令 占用总线
(2)从模块准备数据 不占用总线 总线空闲(3)从模块向主模块发数据 占用总线
分离式通信
充分挖掘系统总线每个瞬间的潜力
一个总线传输周期
子周期1 :主模块申请占用总线,使用完后即放弃总线的使用权。
子周期2:从模块申请占用总线,将各种信息送至总线上。
分离式通信特点:
1、各模块有权申请占用总线
2、采用同步方式通信,不等对方回答
3、各模块准备数据时,不占用总线
4、总线被占用时,无空闲
Q: 什么是总线锁?有什么缺点?替代方案是什么?
A:
- 在早期处理器提供一个 LOCK# 信号,CPU1在操作共享变量的时候会预先对总线加锁,此时CPU2就不能通过总线来读取内存中的数据了
- 缺点:但这无疑会大大降低CPU的执行效率。其他CPU都无法正常操作了。
- 替代方案:缓存一致性协议
由于总线锁的效率太低所以就出现了缓存一致性协议,Intel 的MESI协议就是其中一个佼佼者。MESI协议保证了每个缓存变量中使用的共享变量的副本都是一致的
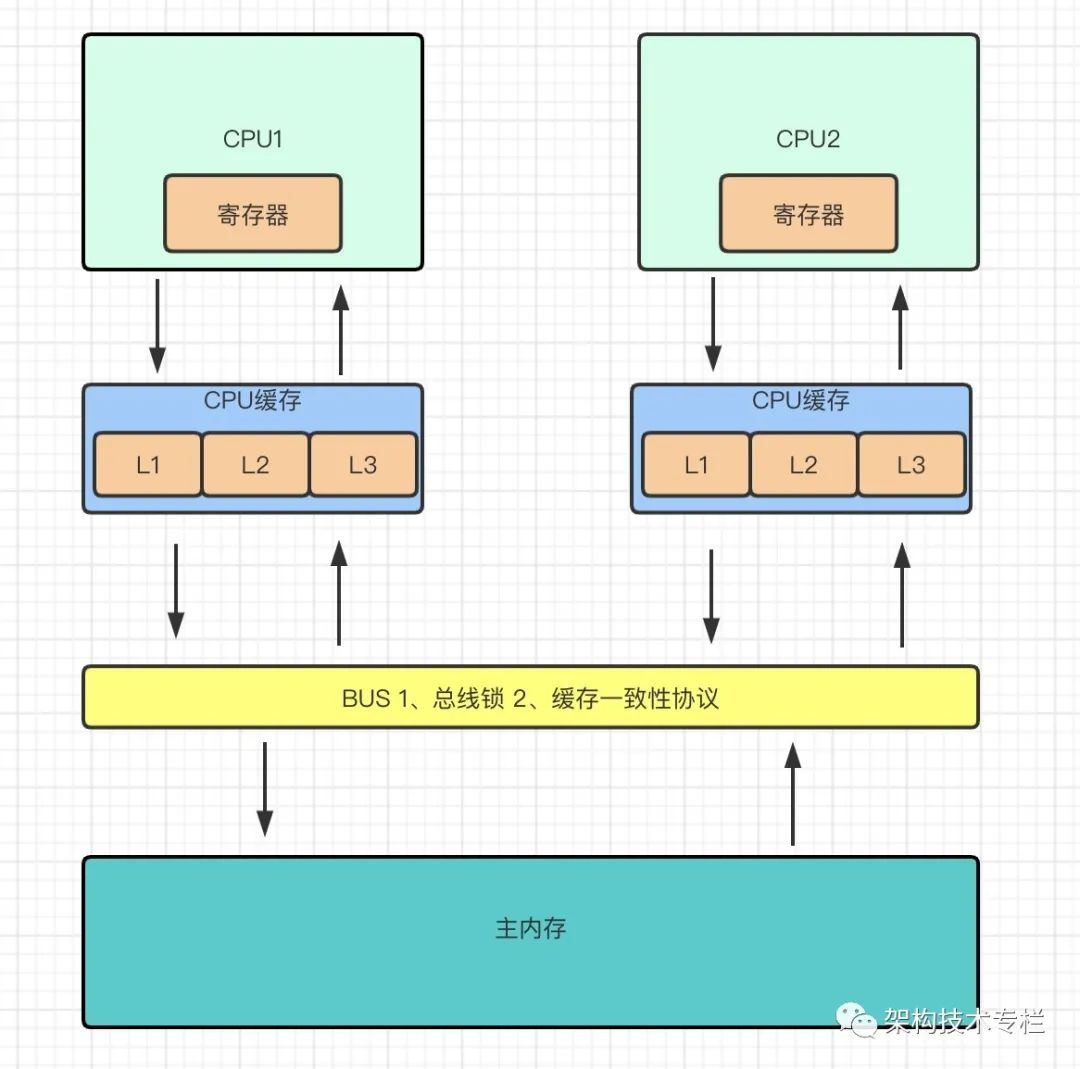
- CPU1使用共享数据时会先数据拷贝到CPU1缓存中,然后置为独占状态(E),这时CPU2也使用了共享数据,也会拷贝也到CPU2缓存中。
- 通过总线嗅探机制,当该CPU1监听总线中其他CPU对内存进行操作,此时共享变量在CPU1和CPU2两个缓存中的状态会被标记为共享状态(S);
- 若CPU1将变量通过缓存回写到主存中,需要先锁住缓存行,此时状态切换为(M),向总线发消息告诉其他在嗅探的CPU该变量已经被CPU1改变并回写到主存中。
- 接收到消息的其他CPU会将共享变量状态从(S)改成无效状态(I),缓存行失效。若其他CPU需要再次操作共享变量则需要重新从内存读取。
Q: 什么情况下缓存一致性会失效?
A:
- 共享变量大于缓存行大小,MESI无法进行缓存行加锁;
- CPU并不支持缓存一致性协议
Q: 缓存一致性可能会引发什么问题?
A: 可能会引发总线风暴。原因如下:
- 嗅探机制:每个处理器会通过嗅探器来监控总线上的数据来检查自己缓存内的数据是否过期,如果发现自己缓存行对应的地址被修改了,就会将此缓存行置为无效。当处理器对此数据进行操作时,就会重新从主内存中读取数据到缓存行。
- MESI会触发嗅探器进行数据传播。当有大量的volatile 和cas 进行数据修改的时候就会产大量嗅探消息。
- 结合上面2点, 总线是固定的,所有相应可以接受的通信能力也就是固定的了
- 如果缓存一致性流量突然激增,必然会使总线的处理能力受到影响。而恰好CAS和volatile 会导致缓存一致性流量增大。如果很多线程都共享一个变量,当共享变量进行CAS等数据变更时,就有可能产生总线风暴。
因此volatile和CAS不能用太多。