[toc]
来源:
Redis IO多路复用技术以及epoll实现原理
精通Redis!epoll?IO的同/异步、阻塞/非阻塞?都懂了吗?
Q: select/poll的缺点?#
A:
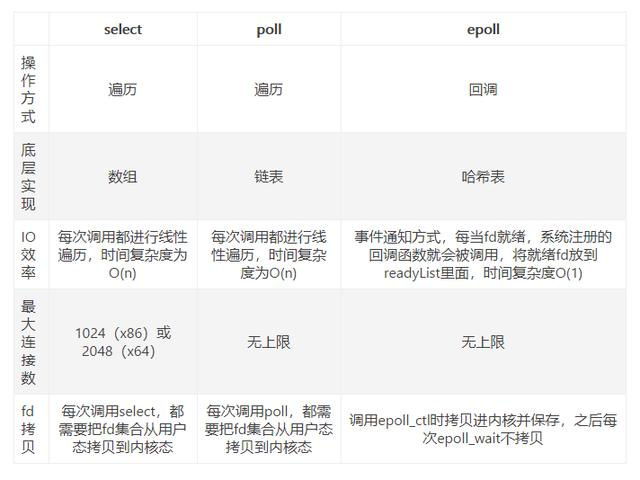
- select的本质是采用32个整数的32位,即3232= 1024来标识,fd值为1-1024。当fd的值超过1024限制时,就必须修改FD_SETSIZE的大小。这个时候就可以标识32max值范围的fd。
- poll与select不同,通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制,pollfd中的events字段和revents分别用于标示关注的事件和发生的事件,故pollfd数组只需要被初始化一次。
- select/poll的几大缺点:
- 每次调用select/poll,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 同时每次调用select/poll都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- 针对select支持的文件描述符数量太小了,默认是1024
- select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
- 相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制 ,但其他三个缺点依然存在。
而用了epoll,上面select的缺点都不复存在了。
他们三者的对比如下:
epoll的设计要点#
A:
-
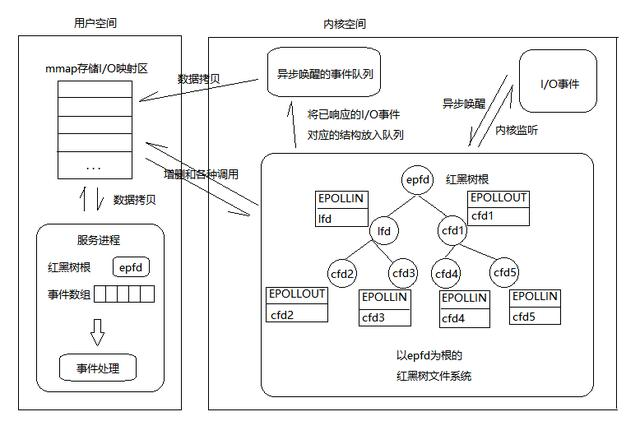
首选Epoll在Linux内核中构建了一个文件系统,该文件系统采用红黑树来构建,红黑树在查询、新增、删除的效率极高,保障了在存在大量活跃连接的情况下的性能。 即新连接通过红黑树方式插入和更新
-
其次Epoll红黑树上采用事件异步唤醒,内核监听I/O,事件发生后内核搜索红黑树并将对应节点数据放入异步唤醒的事件队列中。这就避免了无差别的轮询,不会因为连接数增加而导致性能的快速下降。
-
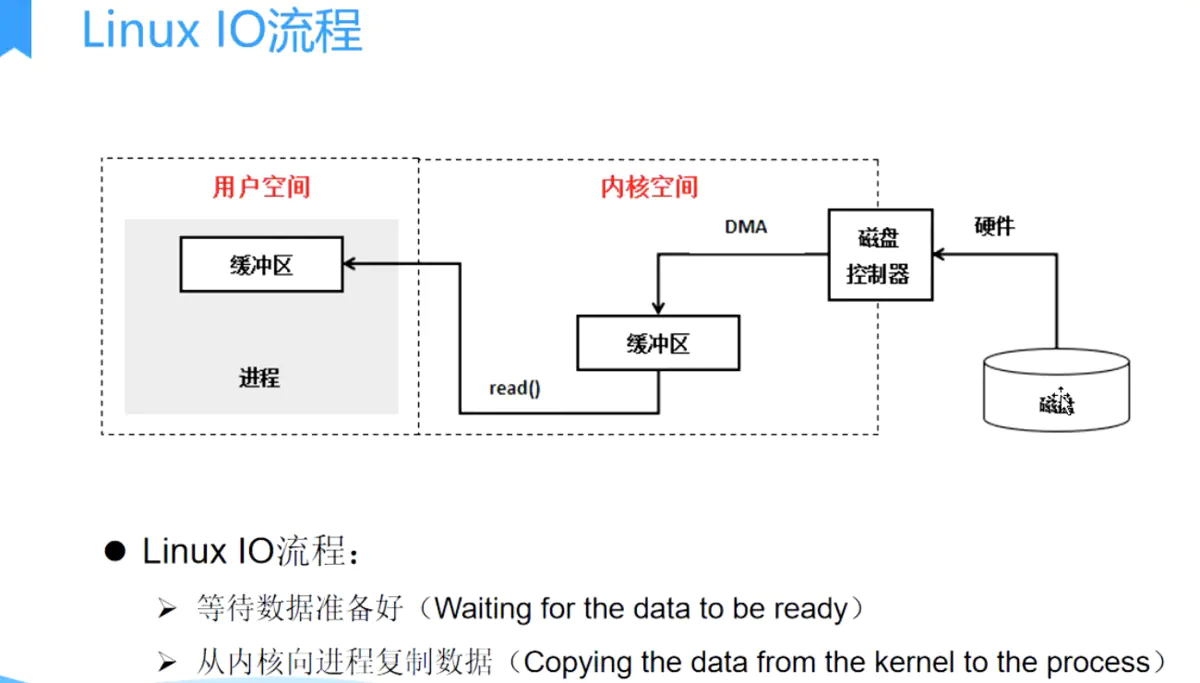
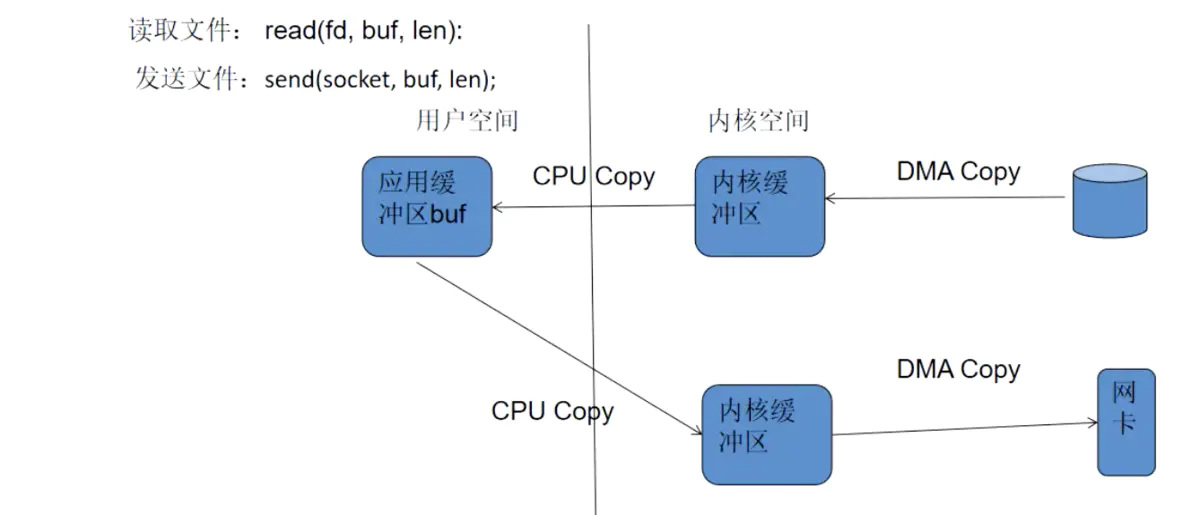
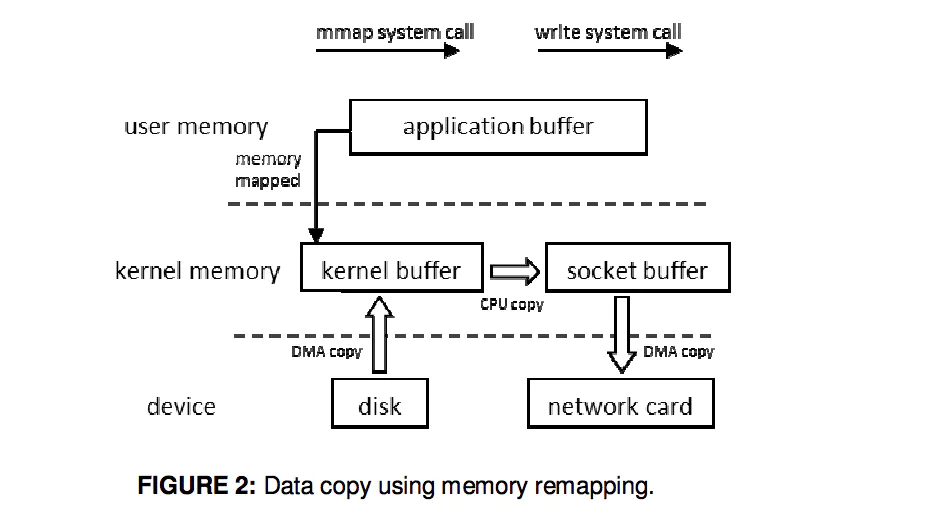
最后Epoll的数据从用户空间到内核空间采用mmap存储I/O映射来加速。该方法是目前Linux进程间通信中传递最快,消耗最小,传递数据过程不涉及系统调用的方法。这点大大提升了存在大量FD时数据拷贝的消耗
详细解释:epoll在被内核初始化时(操作系统启动),同时会开辟出epoll自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。这个内核高速cache区,就是建立连续的物理内存页,然后在之上建立slab层,简单的说,就是物理上分配好你想要的size的内存对象,每次使用时都是使用空闲的已分配好的对象