[toc]
Q: 单纯的redis主从模式有什么缺点?
A:
单纯的读写分离,无法应对大规范的请求访问。
- 读的话可以通过主-从-从-从实现多节点读,但是同步的过程会导致不一致。
- 主从模式,内存里能存储的缓存大小也有限
- 只能主节点写, 写能力有限
Q:redis集群,集群中每个节点是存储了相同的数据吗?
A:
不是的, 采用是类似数据库水平扩容的方式。(主从模式才是数据完全相同)
通过响应的分片算法, 每个redis节点处理的key是不同的,保证每个key映射到唯一的redis节点。
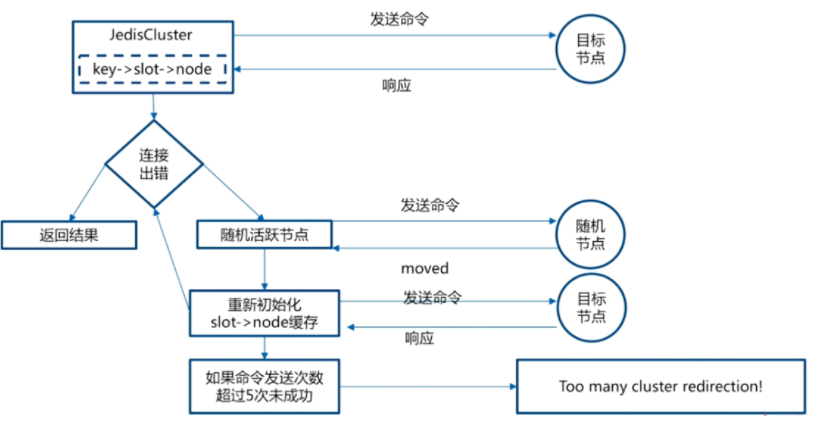
Q:客户端怎么知道数据分布到哪个节点上?难道需要每个客户端自己根据集群信息+分片算法进行计算吗?
A:
客户端在初始化的时候只需要知道一个节点的地址即可
客户端会先尝试向这个节点执行命令
如果key所在的slot刚好在该节点上,则能够直接执行成功。
如果slot不在该节点,则节点会返回MOVED错误,并告知实际节点ip
换句话说, redis集群中每个节点都知道实际的slot分布,并会告知客户端真实地址进行重定向
Q: 每次都要MOVED,那岂不是每次都多访问了1次?
A:
当客户端拿到了MOVED信息的响应后,可通过cluster nodes命令获取整个数据分布表,并缓存在客户端内存中。 这样每次就能根据分布表每次请求到正确的节点
一旦数据分布表发生变化,请求到错误的节点,返回MOVED信息后,重新重新执行cluster nodes命令更新数据分布表。
Q: 除了返回MOVED,还有可能可能返回ASK,这2个的区别是什么?
A:
ASK这种错误是在key对应的slot正在进行数据迁移时产生的。
这时候向slot的原节点访问,如果key在迁移源节点上,则该次命令能直接执行。
如果key不在迁移源节点上,则会返回ASK错误,描述信息会附上迁移目的节点的地址。
客户端这时候要先向迁移目的节点发送ASKING命令,然后执行之前的命令。
Q: 每次客户端代码都要这样自己写一堆逻辑吗?
A:
这些细节一般都会被redis客户端sdk封装起来,使用者完全感受不到访问的是集群还是单节点。即不需要使用者来写这块的重定向、缓存分布表等逻辑。
类似的有JedisCluster。
Q: 那redis集群的分片算法是怎样的,哈希后按照节点数量取余么还是?
A:
Redis-cluster中有16384(即2的14次方)个哈希槽。
每个key通过CRC16校验生成一个数字后, 对16383取模来决定放置哪个槽。
Cluster中的每个节点负责一部分hash槽(hash slot)。
例如节点A负责0到5000, 节点B负责5001-10000,节点C负责10000-16384.
Q: 为什么只有16384个槽?会不会太少了? 一致性哈希算法是2^16的圈长度
A:
16384个槽时,只需要16k(压缩后2k)来存和传输槽信息
65535时,需要65k(压缩后8k)
而redis作者认为redis集群一般不会有超过1000个master节点。
Q: 如果某个redis节点挂了, 是不是马上就要重新分配哈希槽了?
A:
不是的,每个redis-cluster节点本身都是主从双活, 即有5个cluster节点的话,就有5个主和5个从(甚至更多从), 来尽可能让哈希槽不要重新分配。
Q: 那么什么情况下,会进行哈希槽的重新分配?
A:
- 有新的redis-master节点加入(新增从节点不影响分配)
- 某组节点要统一下线,即主从都不在了
- 检测到负载不均匀,需要调整,例如均分成0-5000、5000-10000、10000、16384时, 发现0-5000比其他2个节点的压力多太多,则调小0-5000,分配给其他节点。
Q:新增一个节点时, 扩容的过程是怎么样的?
A:
-
当需要将新节点加入到集群中时, 可以通过管理redis集群的客户端执行“cluster meet 新节点ip:端口”命令,或者通过“redis-trib add node”命令添加新节点
新添加的节点默认在集群中都是主节点
-
客户端向节点B发送状态变更命令,将B的对应slot状态置为IMPORTING
-
客户端向节点A发送状态变更命令,将A的对应slot状态置为MIGRATING
-
客户端针对A的slot上的所有的key,分别向A发送MIGRATE命令,告知A将对应key的数据迁移到B。
-
客户端向集群所有主节点广播槽(数据)全部迁移到了目标节点
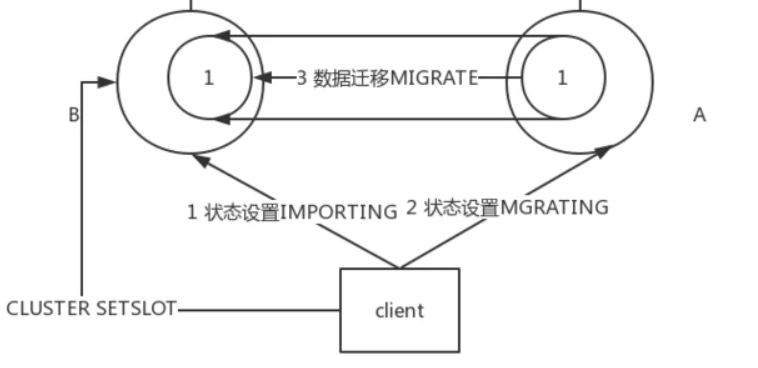
- 注意这个功能是由客户端完成,而非集群内自动完成。
- redis-trib工具做数据迁移
Q: 刚才提到每个redis集群节点中存了实际的哈希槽分布, 这个是怎么传输的,还是说他们都有全局信息进行自己计算?
A:
通过gossip协议实现信息交换。
换句话说, 经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的
Q: 但集群最开始的阶段,只有自己的信息,怎么知道给谁发ping消息呢?
A:
通过MEET消息进行最初的建立。
- redis的集群管理员给第一个redis集群发送“CLUSTER MEET ip port”命令, 然后就能建立2个之间的连接。
- 后面逐步添加时,给任意一个节点发送meet即可。 他们会通过之前提到的ping+pong机制乱序地建立关联
- 可以先建立2个集群, 再通过MEET进行集群连接,合并成一个集群。(有点像并查集)
Q: 刚才只提到了节点加入, 那如果有一个主从节点挂了或者下线, 也是要管理员自己检测然后下线吗?
A:
节点下线问题不能全依赖管理员,因为一旦因为异常情况主从节点都挂了,会导致对应key不可用,必须尽快响应。
- 当节点A ping不通某节点B后,标记为“疑似下线”状态, 会继续用ping命令向集群其他节点同步这个疑似下线的状态
- 节点C收到消息后,把B节点纳入到fail_reports链表中。并同样发送FAIL消息给其他节点。
- 当越发越多,最终有一半以上的节点收到B节点下线的消息时,节点B将被标记成真正下线。
- 标记B下线的这个节点E会直接用FAIL消息进行广播, 而不再慢慢通过ping同步。
Q: E节点怎么知道超过了半数?他难道有全局的视野吗?
A:
当E受到的来自其他master节点的B:PFAIL消息达到一定数量后,会将B的PFAIL升级为FAIL状态,表示B已确认为故障,后续将会发起slave选举流程
换句话说, 当E收到B的PFAIL后,会维护一个fail_reports链表, 记录一下是谁认为B离线了。
当收到的B离线报告越来越多,且人数超过了一半,E就认为可以宣布B真正离线了
Q: 为什么要一半以上下线,才真正认为下线? 直接广播不行么?
A: 因为有可能是某个节点自己网络故障,导致不通。
当他发了疑似下线的状态给别的节点时, 别的节点也许能ping通,那么就会覆盖他的疑似下线状态。
所以需要半数选举,如果节点真的挂了, 那么就不会存在状态覆盖,多次ping同步中肯定会超过半数。
Q: 发ping时的原理讲一下?比如怎么选择给谁发ping, 隔多久发一次?
A:
- 每x秒从所有已知节点中随机选取5个,向其中上次收到pong最久远的一个发送ping
- 如果有未建立连接,但是从别人那里收到过信息的节点,则有限ping或者meet一下。
Q: 心跳中包含了哪些内容?
A:
- Header部分,发送者自己的信息
- 所负责slots的信息
- 主从信息
- ip+port信息
- 自己的状态信息
- Gossip,发送者所了解的部分其他节点的信息
- ping_sent, pong_received
- ip, port信息
- 状态信息,比如发送者认为该节点已经不可达,会在状态信息中标记其为PFAIL或FAIL
Q: gossip的同步过程可以看到是很混乱的,万一redis-master节点先收到了新的slot信息后, 再收到了旧的slot信息,怎么办?
A:
Redis Cluster 使用了类似于 Raft 算法 term(任期)的概念称为 epoch(纪元),用来给事件增加版本号。
每当收到ping里的slots信息, 会判断发送者声明的slots信息,跟本地记录的是否有不同
- 如果不同,且发送者epoch较大,更新本地记录
- 如果不同,且发送者epoch小,发送Update信息通知发送者
Q: cluster bus是什么?
A:
中文名词 集群总线。其实就是特定的集群端口,专用于gossip协议交互。
Redis Cluster Bus通过单独的端口进行连接
bus是节点间的内部通信机制,交互的是字节序列化信息,而不是client到Redis服务器的字符序列化以提升交互效率。
Q: redis集群中可以使用publish吗?为什么?
A:
- 在集群模式下,所有的publish命令都会向所有节点(包括从节点)进行广播
- 这会造成每条publish数据都会在集群内所有节点传播一次,加重了带宽负担
换言之, 如果要用到publish操作,建议换一个redis集群专门做publish, 不要去占用做缓存作用的redis集群带宽。