Java对象在堆中的分配原理#
java对象new的一个过程
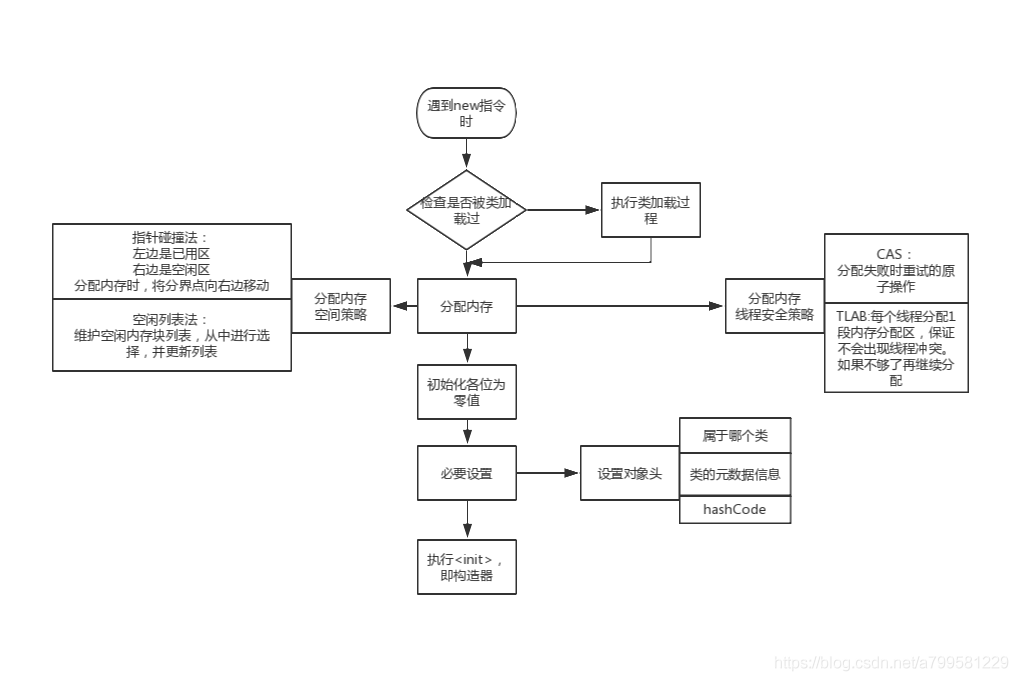
Q: 什么是TLAB?
A:
TLAB ——Thread Local Allocation Buffer
线程本地分配缓冲区
如果没有启用 TLAB,多个并发执行的线程需要创建对象、申请分配内存的时候,有可能在 Java 堆的同一个位置申请,这时就需要对拟分配的内存区域进行加锁或者采用 CAS 等操作,保证这个区域只能分配给一个线程。冲突概率很大
启用了 TLAB 之后(-XX:+UseTLAB, 默认是开启的),JVM 会针对每一个线程在 Java 堆中预留一个内存区域
一旦某个区域确定划分给某个线程,之后该线程需要分配内存的时候,会优先在这片区域中申请。这个区域针对分配内存这个动作而言是该线程私有的,因此在分配的时候不用进行加锁等保护性的操作
Q: TLAB给线程预分配空间的时候,如果多个线程竞争同一个预留空间冲突了怎么办?
A:
在预留这个动作发生的时候,需要进行加锁或者采用 CAS 等操作进行保护,避免多个线程预留同一个区域
Q: 分配的时候,在TLAB区域里,怎么知道放在哪个位置呢?
A:
具体的分配内存有两种情况:第一种情况是内存空间绝对规整,第二种情况是内存空间是不连续的。
对于内存绝对规整的情况相对简单一些,虚拟机只需要在被占用的内存和可用空间之间移动指针即可,这种方式被称为指针碰撞。
对于内存不规整的情况稍微复杂一点,这时候虚拟机需要维护一个列表,来记录哪些内存是可用的。分配内存的时候需要找到一个可用的内存空间,然后在列表上记录下已被分配,这种方式成为空闲列表。
java对象在内存上的分配:
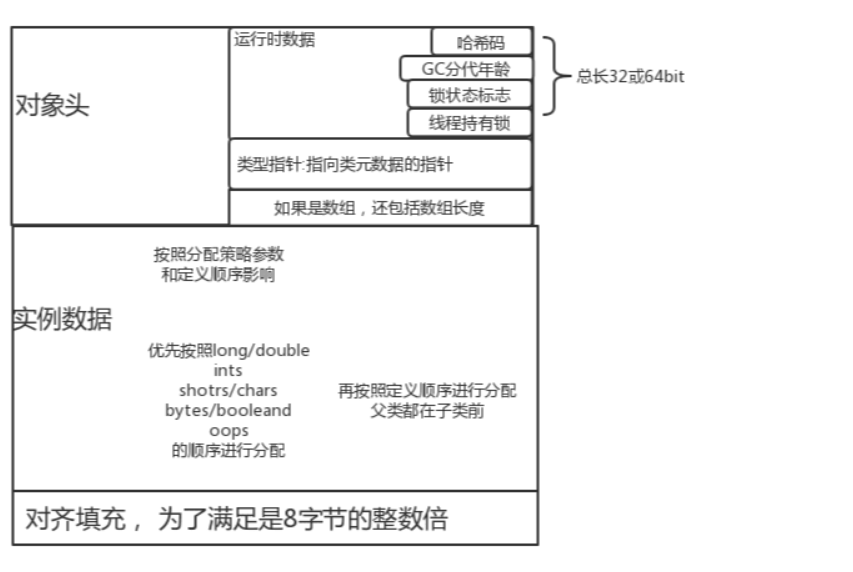
Q: 对象的hashcode确定是创建对象的时候生成的?
A:
不对。采用延迟加载技术
Q: 如何计算一个java对象大小?
例如下面的person?
1 | class People{ |
A:
这里假设使用64位机器,采用指针压缩,则对象头的大小为:8(_mark)+4(_klass) = 12(如果没开启,k_class即对象引用地址占8个字节)
然后实例数据的大小为: 4(age)+4(name) + 8(birthday) + 8(sallary) + 2(tag) + 4(引用,开启指针压缩) + 1或4(married) = 31 or 34
因此最终的对象本身大小为:12+31+5(padding) = 48 或者 12+ 34 + 2(padding) = 48
PS1: 注意布尔值可能是1或者4,根据虚拟机规范不同有不同,4字节的话好处是CPU
PS2: 注意,指针压缩不仅仅影响对象头,还影响了对象内的引用大小。
更详细的见如何计算Java对象所占内存的大小
Q: 对象头里的markword到底是啥?
A:
markword根据锁标记的状态,里面存储的了不同的内容。

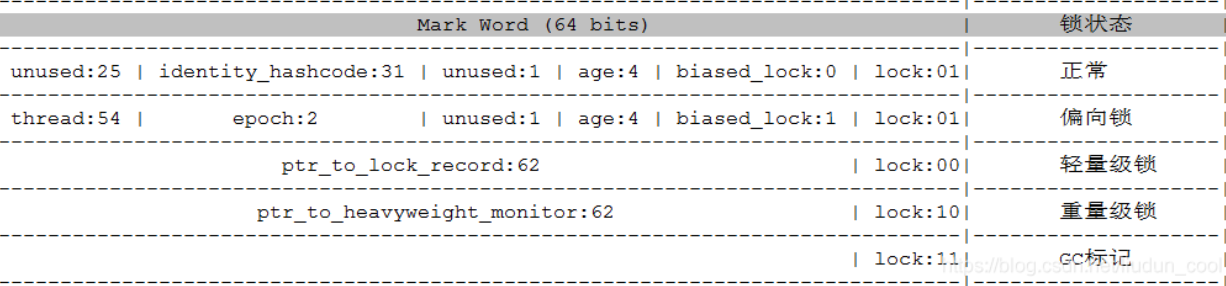
java对象头 MarkWord
Q: 哈希code 有锁的时候,hashcode又去哪了?
A:
identity_hashcode:31位的对象标识hashCode,采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。当对象加锁后(偏向、轻量级、重量级),MarkWord的字节没有足够的空间保存hashCode,因此该值会移动到管程Monitor中。
Q: 对象内存字节为什么要按8字节对齐?
A:
对齐填充是底层CPU数据总线读取内存数据时的要求
例如,通常CPU按照字单位读取,如果一个完整的数据体不需要对齐,那么在内存中存储时,其地址有极大可能横跨两个字
例如某数据块地址未对齐,存储为1-4,而cpu按字读取,需要把0-3字块读取出来,再把4-7字块读出来,最后合并舍弃掉多余的部分。这种操作会很多很多,且很频繁
但如果进行了对齐,则一次性即可取出目标数据,将会大大节省CPU资源。
另一种说法:
Scott oaks在书上给出的理由是:
其实在JVM中(不管是32位的还是64位的),对象已经按8字节边界对齐了;对于大部分处理器,这种对齐方案都是最优的。所以使用压缩的oop并不会损失什么。如果JVM
中的第一个对象保存到位置0,占用57字节,那下一个对象就要保存到位置64,浪费了7
字节,无法再分配。这种内存取舍是值得的(而且不管是否使用压缩的oop,都是这样),因为在8字节对齐的位置,对象可以更快地访问。不过这也是为什么JVM没有尝试模仿36位引用(可以访问64GB的内存)的原因。在那种情况下,对象就要在16字节的边界上对齐,在堆中保存压缩指针所节约的成本,就被为对齐对象而浪费的内存抵消了。
** 8字节对齐,是为了效率的提升,以空间换时间的一种方案**。当然你还可以16字节对齐。但是8字节是最优选择。
Q: jvm的指针压缩原理是什么?
A:
我们都知道java中的对象都是8字节对齐的,8字节对齐有一个特点就是总是加上1 000。 发现了吗, 所有对象的指针后三位总是0。这就是指针压缩的点。
压缩原理就是两句话:
1:存储的时候,后三位抹除0.
就变成:test1=00,test2=10
2:使用的时候,后三位补0.
它的指针不再表示对象在内存中的精确位置,而是表示 偏移量 。这意味着 32 位的指针可以引用 40 亿个 对象 , 而不是 40 亿个字节。最终, 也就是说堆内存增长到 32 GB 的物理内存,也可以用 32 位的指针表示。(4字节指针地址原先只能表示4个G的大小)
Q: 指针压缩什么时候会失效?
A:
因为寄存器中2的32次方只能寻址到32g左右(不是准确的32g,有可能在31g就发生指压缩失效)
所以当你的内存超过32g时,jvm就默认停用压缩指针,用64位寻址来操作,这样可以保证能寻址到你的所有内存,但这样所有的对象都会变大,实际上未开启开启后的比较,40g的对象存储个数比不上30g的存储个数
Q: 为什么对象头里的kclass也会受指针压缩的影响?class实例不是存储在方法区里么?
A:
JDK1.6中Class实例在方法区
JDK1.8之后, class实例本身就是一个对象,分配在java堆中。而class字节码加载后的各种细节内容则存储在永久代中。
HotSpot并不把永久代中的instanceKlass暴露给Java
而会另外创建对应的class对象instanceOopDesc来表示java.lang.Class对象(即这个对象里不会包含class细节字节码的内容),并将后者称为前者的“Java镜像”, 对象头里的klass就是持有指向类oopDesc引用(_java_mirror便是该instanceKlass对Class对象的引用);
Q: 在方法栈中执行代码时,如何通过引用定位到堆里的对象?
A:
两种方式,通过句柄池,或者通过指针。如下图所示
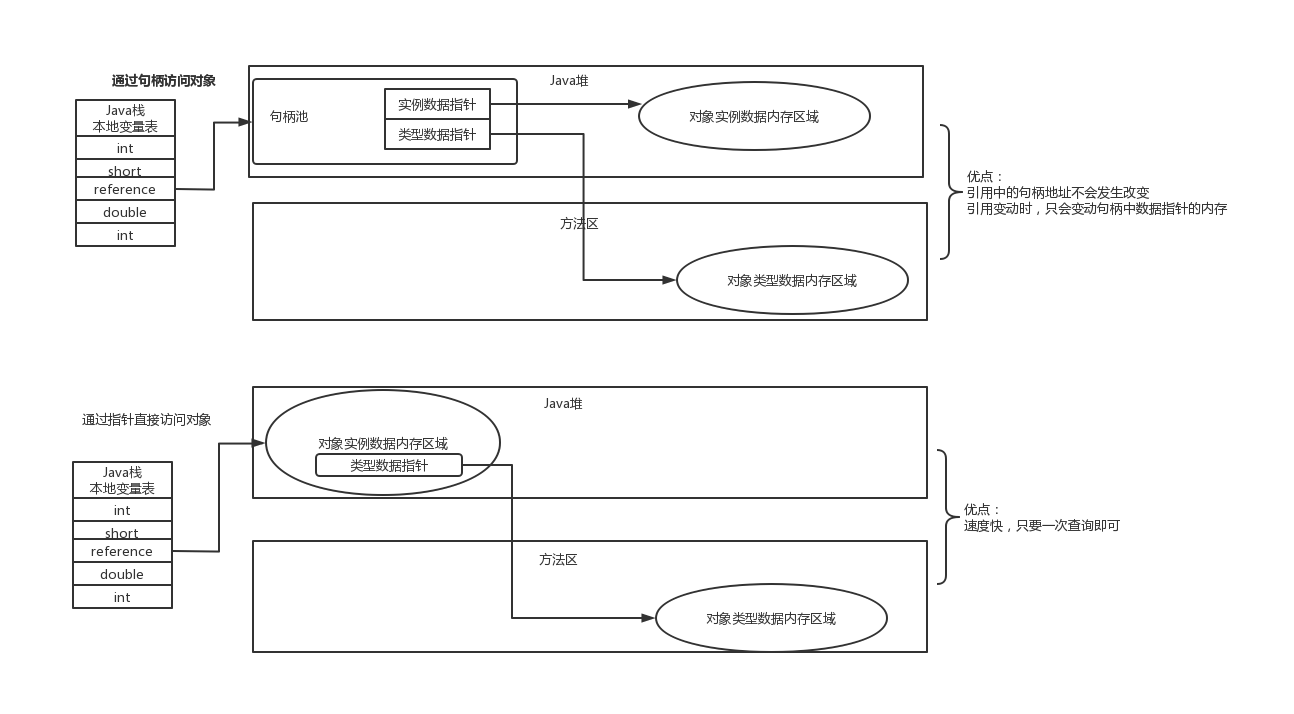
Q: 句柄和指针的区别是什么?
A:
句柄池, 引用中的句柄地址不会发生改变引用变动时,只会变动句柄中数据指针的内存
可以理解为,句柄池方式, 创建新对象后,句柄位置就定下来了。后面如果频繁修改引用, 只会修改句柄里的指针,但是本地变量表里寻找的位置都不会变化,因此不用经常跳到各种本地变量表去修改。
- 频繁gc、修改引用的,用句柄池引用
- 频繁访问固定对象的,用指针引用
Q: 怎么确认用的是句柄引用还是指针引用?
A:
sun HotSpot用的指针引用,速度快
访问方式,取决于虚拟机的实现。
Q: 方法里创建基本类型的局部变量时, 为什么不把基本类型放堆中呢?
A:
因为其占用的空间一般是 1~8 个字节——需要空间比较少,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的。
可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据
Q: 那我new出来的对象, 一定都在堆中吗?
A:
HotSpot虚拟机引入了JIT优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存。
Q: 刚才new对象的过程,可能存在重排序吗?
A:
存在。
①「JVM」为对象分配一块内存M。
②在内存M上为对象进行初始化。
③将内存M的地址复制给singleton变量。
可以是「①②③」或者「①③②」。 这也导致了双重检查锁时,为什么有了sync还要加volatile。
但是另一种说法,是JDK高版本之后, 将这个new语句看成一个大号的volatile写,因此这个大号volatile写前后会有内存屏障,与volatile读隔离开来,因此虽然volatile读不知道大号volatile写的内部顺序,但是知道它的结果一定是执行完那三步的。
因此重排序仍然存在,但是会特地限制其他对该对象的new的过程是有屏障的。
Q: 上面的过程的指令码是什么样的?
A:
1 | 0: new #16 // class jvm/fenixsoft/DynamicDispath$Man |
那么为什么要进行备份呢?
一开始是new指令在堆上分配了内存并向操作数栈压入了指向这段内存的引用
之后dup指令又备份了一份,那么操作数栈顶就有两个
再后是调用invokespecial #18指令进行初始化,此时会消耗一个引用作为传给构造器的“this”参数, 注意这个指令会将栈顶的引用拿走,因此dup指令都是用于这种场景的,即栈顶的引用存在消耗。
那么还剩下一个引用,会被astore_1指令存储到局部变量表中,后面调用的代码会用到。