[toc]
ArrayList原理#
Q: 讲一下啊arrayList的扩容原理?
A:
比较简单,算出新容量后,直接Arrays.copy拷贝到新数组,搞定
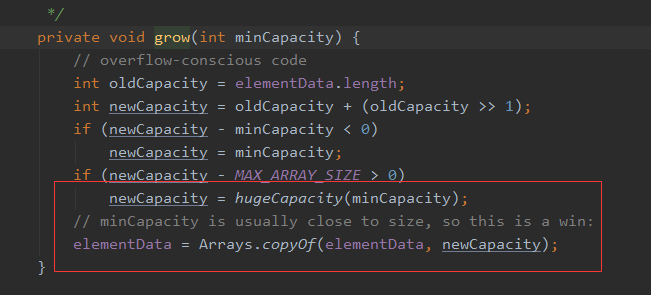
扩容容量= 原容量 + (原容量右移1位,即0.5倍)= 1.5倍

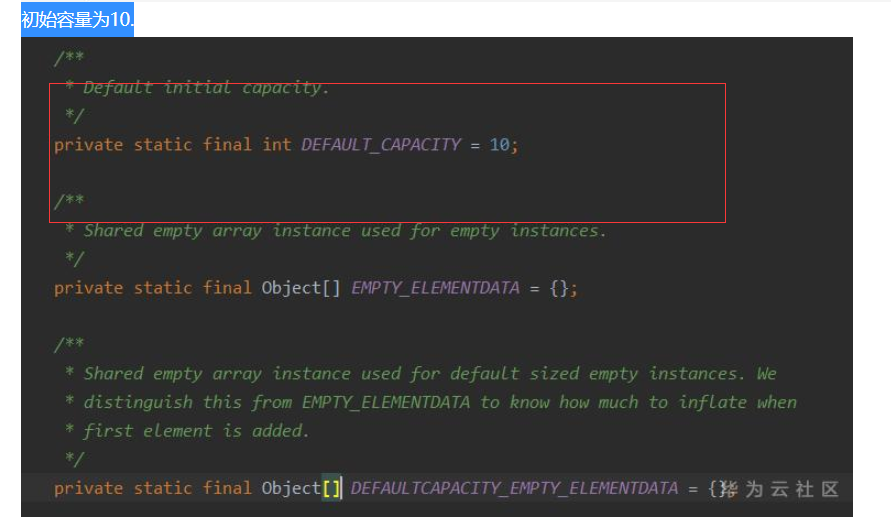
Q: arrayList的初始最大容量是多少?可以更改吗?
A:
初始容量为10。不可修改
CopyOnWriteArrayList 原理#
就是一个写时复制列表
当发生“删除/修改/新增”时,会先新建一个数组,更新后的数据拷贝到数组中
最后再更新到CopyOnWriteArrayList的数组成员引用上。
为什么需要写时复制?#
针对多线程环境下,读多写少的情况,如果每个读都加线程同步,太浪费了
因此可以读的时候不加锁
只有写的时候加锁,写完更新
读的时候可能会有点延迟的数据,但不影响。
如何避免多线程修改的冲突?#
加了一个sync锁,修改动作是线程安全的。
如何保证更新后,数组引用的变动能及时对外呈现?#
数组成员设置成volatile
HashMap核心原理#
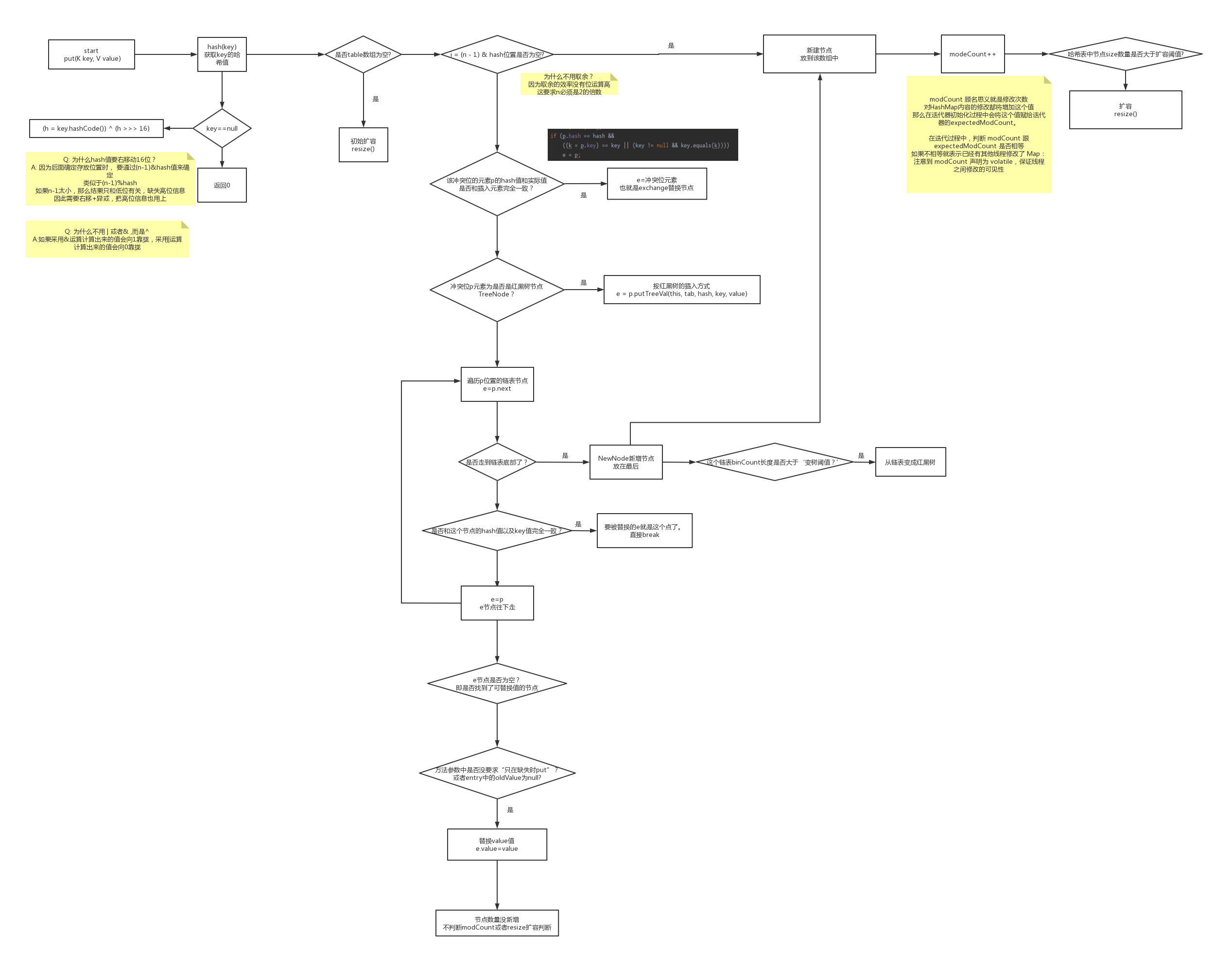
hashMap完整的put过程#
- 首先,要获取key的哈希值。
如果为空,就统一是0
否则,调用对象的.hashCode()方法,接着再与自己的右移16位进行异或,以便充分利用高位信息。 - 接着判断内部node数组是否为空,如果是,先进行初始化扩容。默认为16。
- 根据(n-1)&hash值,获取哈希表索引位置。 (&的性能比取余要高,具体讨论见CPU取余原理)
- 哈希表的node数组中,存放的是每组链表的头节点。
先检查头节点是否和自己要存放的key完全匹配 (hash值相同,key值相同,先hash再key,是因为hash的判断简单,key的equals判断可能会复杂)
如果匹配,得到需要替换的节点。 - 头节点和自己要放的key不匹配,则判断一下这个头节点是否是红黑树节点,如果是,说明已经升级成红黑树了,调用putTree插入到红黑树中。
- 如果不是红黑树, 那就是遍历链表,完全匹配就得到需要替换的节点。如果到尾部了,也没匹配的,则插入新节点。
- 如果前面找到了要替换的节点,则判断一下是否可以替换(是否没要求putIfAbsent,或者value为null),是就替换,不是就结束
- 如果前面是插入了新节点,非替换, 则要modCount++(方便迭代器确认map是否更新), 同时++size, 然后和扩容阈值做判断, 如果太大,就resize进行扩容
hashMap的扩容过程,java7和8扩容的区别#
- java7:
- 当resize时,新建一个数组newTable
- 遍历原table中的每个链表和节点,重新hash,找到新的位置放入
- 放入的方式是头插法,即始终插在链表的头节点。
- java8:
- 不再每个点rehash放置,而是最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标. 避免了频繁的哈希计算和搬移过程。
- 使用尾插法在链表上插入节点
- 桶内元素超过8个,链表转成红黑树
为什么java8要改成尾插法?#
A:
多线程时,java7的map-put可能造成死循环。
A线程扩容到那一半, 还处在遍历链表做头插法搬移的过程时,存了2个局部变量,当前链点now指向a, next指向b,正准备搬移(a->b->c这样的链表,a是头节点)
B线程则同时完成线程扩容,但是map里都是引用,浅拷贝,** 因为是头插法, 会导致顺序变化**, 原本a->b->c 变成了c->b->a。
因此A恢复时, 链点还是a,next还是b, 于是往下走到了b, 取bbs的next时,已经变成了a, 于是发生了a->b->a的循环
导致后续操作的next都是错误操作,引发环形指针。
java8里改成尾插法,这样做resize时,a->b->c 如果仍然哈希到同一个节点, 顺序是不会发生变化的。
虽然解决了死循环问题, 但java8的hashMap仍然是线程不安全的,为什么?#
A:
因为缺乏同步,导致同节点发生哈希碰撞时,if条件的判断都可能是有问题的,导致本该插在链表头节点后面的,结果直接作为链表头覆盖到数组上了。
具体到底满足什么情况,才会resize扩容呢?#
A:
HashMap负载因子 LoadFactor,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
HashMap.Size >= Capacity * LoadFactor
另一种情况。JDK1.8源码中,执行树形化之前,会先检查数组长度,如果长度小于64,则对数组进行扩容,而不是进行树形化
扩容后,capacity扩容多少倍呢?#
A:
哈希表每次扩容是两倍
ConcurrentHashMap 核心原理#
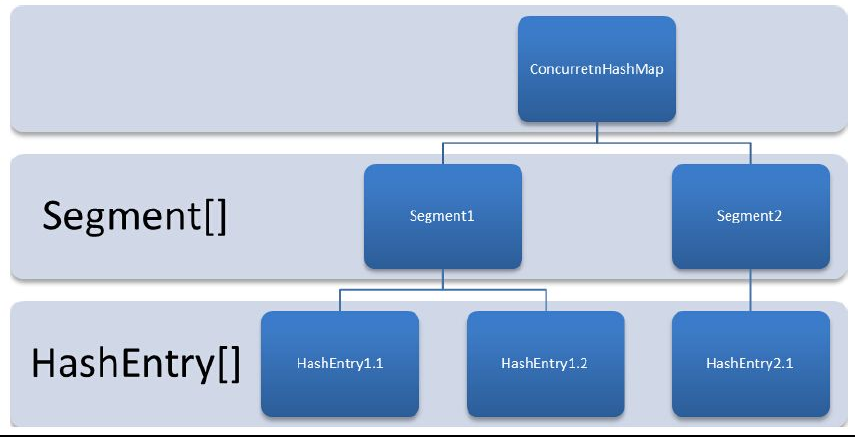
CHM结构
每个concurrentHashMap里有一个segment数组
每个segment里有HashEntry数组
每个hashEntry可以演变为链表或者红黑树
https://blog.csdn.net/qq_18300037/article/details/123795776
https://blog.csdn.net/every__day/article/details/114293107
JDK6-7中的实现原理#
初始化map#
初始化segment数组(通过concurrencyLevel和ssize)#
sszie即segment size,是seg数组的大小
ssize一定是2的N次方,且一定是 大于等于concurrencyLevel的最小值
sszie的最大值为65535
ssize的默认值是16
初始化segmentShift段偏移量和segmentMask段掩码#
这2个变量用于后面定位segment的散列算法使用
sshift 是 ssize的2的次方数
segmentShift = 32 - sshift 默认等于32-4=28
segmentMask = ssize -1 默认等于15
初始化每个segment#
每个segment里有一个entry数组
这个数组的大小cap也是2的N次方, 且大于等于 initialCapacity(就是你传的初始容量值) / ssize 即平均每段数量
1 | this.segments[i] = new Segment<K,V>(cap, loadFactor); |
loadFactor默认0.75
initialCapatity默认值为16
定位Segment#
对于一个key ,先是获取hashcode, 然后对hashcode进行变种算法再散列
1 | private static int hash(int h) { |
这个算法能保证各位都能利用上,尽可能均匀, 相比hashmap里单纯和高16位做异或不同。
1 | return segments[(hash >>> segmentShift) & segmentMask]; |
可以看出
segmentShift的作用是让hash通过右移动,只保留符合ssize的2进制位数长度
顺便通过和segmentMask进行&操作,剔除其他的位
总目的就是为了让32位的hash偏移后保持在ssize的范围内
按默认值而言,即 (hash>>>28) & 15
get操作#
先按照上文进行哈希, 获取segment后再进行get操作
整个过程都不需要加锁!
除非读到的值时空的,才会加锁重读确认(可能是被修改过了)
获取segment这个操作中,涉及的数组count、存储HashEntry的value,都涉及成了volatile,保持可见性。
put操作#
put操作处理共享变量(例如count等)是一定会加锁的。
区别在于扩容时,只对某一个segment扩容,不会影响其他的segment
扩容时会先创建容量两倍的数组,重新放入后在修改引用。
CHM是插入前先判断,再选择是否扩容
而hashMap是插入后判断,再选择是否扩容
size操作#
size自然是要把所有segment里的size进行相加
但是for循环相加可能会有前面的segment被修改,导致size变化,但如果加锁又太耗时间
因此引入了modCount,如果统计完成过程中发现modCount变化,则会加锁的方式重新统计。
JDK8的改造升级(重要)#
在`JDK8中,它进行了以下重要改进:
-
取消分段锁机制
(Segment),进一步降低冲突概率; 使用桶的概念。其内部虽然仍然有
Segment定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构 上的用处。因为不再使用
Segment,初始化操作大大简化,修改为lazy-load形式,这样可以有效避免 初始开销 -
size()方法做了优化,表达范围变大。原来
map原有的size方法最大只能表达2的31次方减一,现在额外提供mappingCount方法,最大表示为2的63次方减一 -
使用
Unsafe、LongAdder之类底层手段,进行极端情况的优化。使用CAS等操作,在特定场景进行无锁并发操作。 即get使用volatile读, 而put则使用cas进行并发put。 -
类似hashMap引入红黑树解构,同一个哈希槽元素个数超过一定的阙值后,单链表转化成红黑树;
-
支持多线程并发扩容,大大提升扩容速度。
(4条消息) java8中concurrentHashmap的改进_庄国帅哥的博客-CSDN博客
(1条消息) JDK 8 ConcurrentHashMap_黄泥川水猴子的博客-CSDN博客_concurrenthashmap jdk8
ConcurrentLinkedQueue核心原理#
核心是使用CAS而不是锁来处理链式队列。
比较容易想到的是每次用cas来处理next指针的跟新以及tail指针的指向
1 | public boolean offer(E e) { |
但是缺点在于及时没有并发,也要频繁cas更新tail节点。
实际上只需要用到tail节点的时候再去定位即可。
所以设置了一个HOPS值
当tail节点和实际尾节点的距离大于等于HOPS值,才去定位并cas更新tail节点,否则只更新next指针。
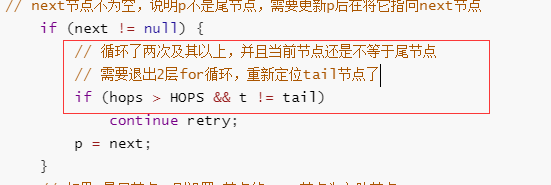
完整代码:
1 | public boolean offer(E e) { |
代价是距离越长,入队时定位队尾的时间越长。
但是效率总体上提升了, 因为通过增加对volatile变量的读操作来减少对volatile变量的写操作。