[toc]
Executor线程池应用详解#
corePoolSize和maximumPoolSize参数有什么区别?#
A:
当提交新线程到池中时
- 如果当前线程数 < corePoolSize,则会创建新线程
- 如果当前线程数=corePoolSize,则新线程被塞进一个队列中等待。
- 如果队列也被塞满了,那么又会开始新建线程来运行任务,避免任务阻塞或者丢弃
- 如果队列满了的情况下, 线程总数超过了maxinumPoolSize,那么就抛异常或者阻塞(取决于队列性质)。
- 调用prestartCoreThread()可提前开启一个空闲的核心线程
- 调用prestartAllCoreThreads(),可提前创建corePoolSize个核心线程。
keepalive参数是干嘛的?#
A:当线程数量在corePoolSize到maxinumPoolSize之间时, 如果有线程已跑完,且空闲时间超过keepalive时,则会被清除(注意只限于corePoolSize到maxinumPoolsize之间的线程)
核心线程可以被回收吗?(线程池没有被回收的情况下)#
A:
ThreadPoolExecutor有个allowCoreThreadTimeOut(boolean value)方法,可以设置是否在超期后做回收
核心线程数设置多少,怎么考虑?#
A:
io密集型, 可以设置多一点, 因为多一个线程,他可能也没太占cpu,都是在等待IO。
如果是计算密集型,则要设置少一点,别把cpu搞满载了。
有超线程技术的话, 一般可以设置成2倍CPU数量的线程数
超线程技术把多线程处理器内部的两个逻辑内核模拟成两个物理芯片,让单个处理器就能使用线程级的并行计算,进而兼容多线程操作系统和软件。超线程技术充分利用空闲CPU资源,在相同时间内完成更多工作
线程池有哪三种队列策略?#
A:
- 握手队列
相当于不排队的队列。可能造成线程数量无限增长直到超过maxinumPoolSize(相当于corePoolSize没什么用了,只以maxinumPoolSize做上限) - 无界队列
队列队长无限,即线程数量达到corePoolSize时,后面的线程只会在队列中等待。(相当于maxinumPoolSize没什么用了)
缺陷: 可能造成队列无限增长以至于OOM - 有界队列
线程池队列已满且maxinumPoolSize已满时,有哪些拒绝策略?#
A:
- AbortPolicy 默认策略:直接抛出RejectedExecutionException异常
- DiscardPolicy 丢弃策略: 直接丢了,什么错误也不报
- DiscardOldestPolicy 丢弃队头策略: 即把最先入队的人从队头扔出去,再尝试让该任务进入队尾(队头任务内心:不公平。。。。)
- CallerRunsPolicy 调用者处理策略: 交给调用者所在线程自己去跑任务(即谁调用的submit或者execute,他就自己去跑) 注意这个策略会用的比较多
- 也可以用实现自定义新的RejectedExecutionHandler
线程池为什么需要阻塞队列?#
A:
线程池创建线程需要获取mainlock这个全局锁,影响并发效率,阻塞队列可以很好的缓冲。避免大量线程获取这个创建锁。
五种常见的Executor自带线程池#
有以下五种Executor提供的线程池,注意记忆一下他们的用途,就能理解内部的原理了。
-
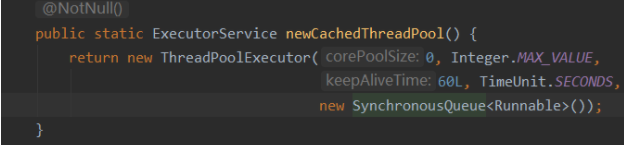
newCachedThreadPool: 缓存线程池#
corePoolSize=0, maxinumPoolSize=+∞,队列长度=0 ,
因此线程数量会在corePoolSize到maxinumPoolSize之间一直灵活缓存和变动, 且不存在队列等待的情况,一来任务我就创建,用完了会释放。
-
newFixedThreadPool :定长线程池#
corePoolSize= maxinumPoolSize=构造参数值, 队列长度=+∞。
因此不存在线程不够时扩充的情况 -
newScheduledThreadPool :定时器线程池#
提交定时任务用的,构造参数里会带定时器的间隔和单位。 其他和FixedThreadPool相同,属于定长线程池。
-
newSingleThreadExecutor : 单线程池#
corePoolSize=maxinumPoolSize=1, 队列长度=+∞
只会跑一个任务, 所以其他的任务都会在队列中等待,因此会严格按照FIFO执行 -
newWorkStealingPool(继承自ForkJoinPool ): 工作密取线程池#
如果你的任务执行时间很长,并且里面的任务运行并行跑的,那么他会把你的线程任务再细分到其他的线程来分治。这种特点在于可以在任务队列的两头取任务
submit和execute方法区别是什么?#
A:
- execute只能接收Runnable类型的任务,而submit除了Runnable,还能接收Callable(Callable类型任务支持返回值)
- execute方法返回void, submit方法返回FutureTask。
- 异常方面, submit方法因为返回了futureTask对象,而当进行future.get()时,会把线程中的异常抛出,因此调用者可以方便地处理异常。(如果是execute,只能用内部捕捉或者设置catchHandler)
线程池中, shutdown、 shutdownNow、awaitTermination的区别?#
A:
- shutdown: 停止接收新任务,等待所有池中已存在任务完成( 包括等待队列中的线程 )。异步方法,即调用后马上返回。
- shutdownNow: 停止接收新任务,并 停止所有正执行的task,返回还在队列中的task列表 。
- awaitTermination: 仅仅是一个判断方法,判断当前线程池任务是否全部结束。一般用在shutdown后面,因为shutdown是异步方法,你需要知道什么时候才真正结束。
ForkJoin线程池#
forkJoin核心概念#
ForkJoin线程池在常规的java书籍里还是提到比较少的,毕竟是java8引入的产物。
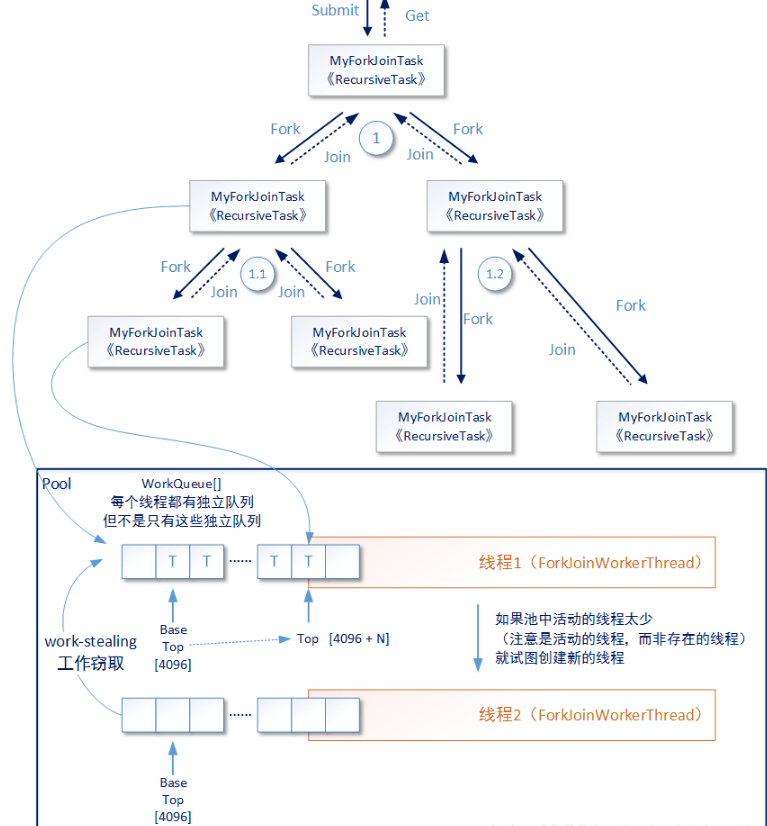
首先这里简单解释一下forkJoin的运作原理, 本质上有点像归并计算。
- 他会将提交大任务按照一定规则拆解(fork)成多个小任务
- 当任务小到一定程度时,就会执行计算
- 执行完成时会和其他的小任务进行合并(join), 逐步将所有小结果合成一个大结果。
可以看这个forkJoinTask的实现伪代码,即如果想使用forkJoin并发执行任务,需要自己把任务继承RecursiveTask,作为forkJoin池的submit对象:
1 |
|
然后实际上整个forkjoin的细节非常多,这里我通过给自己提好几个问题,来逐步理解forkJoin的原理,
forkJoin中各个线程是如何获取那些小任务的呢?#
A:
他是通过工作密取的方式获取。(java并发那本书里提到过工作密取workSteal,原来是用在这了)
- 假设我们给forkJoin设置3个工作线程,那么就会有3个工作队列, 注意,这个队列是双端队列。
- 每当执行任务时,如果不满足小任务的条件,他会fork出2个子任务,并push进自己的工作队列中。
- 每个工作线程不断取自己队头的任务执行。
- 关键点:如果自己队列里没有数据,则会从其他队列的队尾取数据。
fork时具体发生了什么?#
A:
是一个异步的操作, 就是向当前线程队列中添加这个fork出来任务,能放进去的话就返回,不会等待。
注意,默认fork出的任务是先默认给自己的。 当自己做不完时,才可能被别人取走!

join是什么含义?什么时候做的?#
A:
见实现forkJoin任务接口时的代码:
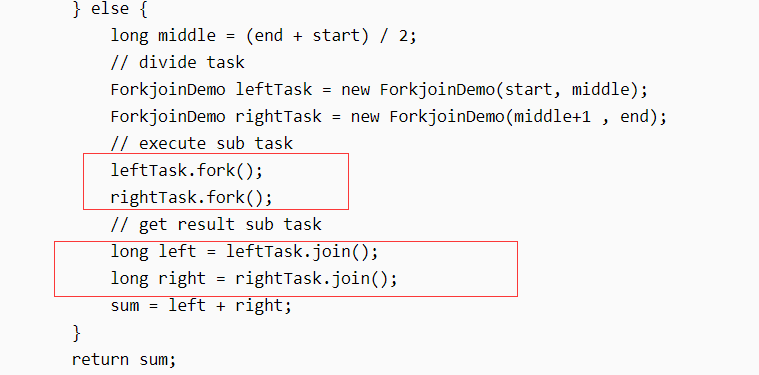
可以看到时每次fork完之后, 通过join,来获取子task的结果,获取到之后,再合并计算,返回结果。
join这个阻塞过程是怎么做的?如果把线程挂起,那这个线程岂不是无法工作了?#
A:
首先,之前fork时,新的子任务已经被放入队列了。
每个子任务都有一个任务状态。
当调用该子任务的join时, 会循环判断他的状态
如果这个子任务状态未完成, 则从自身队列或其他人的队列中取出新的任务执行,因此进入了下一层的exec()操作。
如果发现子任务状态更新为了完成(这个更新动作可能是自己线程完成的,也可能是别的线程完成的,反正这个任务的状态实现了同步和可见), 则将结果返回给上层。
因此join的本质是一个递归的过程, 任务没完成的话,他就取其他任务继续递归往下执行。
更详细的可以看这个链接fork+join过程详细解读
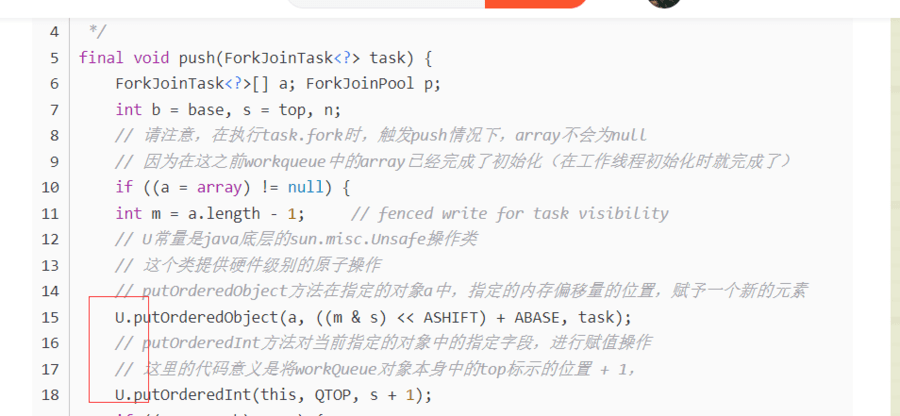
forkJoin存放任务的时候,怎么保证不会出现并发问题?比如同时往队尾插入的话#
A:
- n个工作线程是通过数组存放的(即有一个工作线程数组)
- sun.misc.Unsafe操作类直接基于操作系统控制层在硬件层面上进行原子操作,它是ForkJoinPool高效性能的一大保证,类似的编程思路还体现在java.util.concurrent包中相当规模的类功能实现中。
forkJoin应用在哪?#
A:
java8 stream的parallel并发功能就是基于forkJoin做的, parallelStream实现的forkJoin拆解任务和执行任务的接口, 默认用机器所有CPU数量的forkJoin线程池。
如果需要限制线程数量,可以用
new forkJoin(线程数).submit(()->(list.stream().parallel().map()…)); 即可
关于java8和forkJoin究竟是如何配合的,可以看这个链接:
源码级别学习java8并行流执行原理
https://www.cnblogs.com/Dorae/p/7779246.html
TheadLocal核心原理#
ThreadLocal的常见使用场景?#
每个线程中需要维护1个不同的副本, 但这个副本可能是某一个时刻一起塞入每个线程的, 只不过之后该副本的变化 不再受其他线程的影响。
常见场景有连接器管理模块connectorManager, 每个线程持有的connect变量是单独使用的,不会互相影响或者需要加锁。原因就是将其作为副本放入每个线程,当线程启动连接或者关闭时,不影响其他线程里的getConnect方法。
ThreadLocal和Synchronized关键字的区别?#
A:
Synchronized是用时间的消耗,来换取数据同步以及互不冲突
ThreadLocal则是用空间的消耗,来换取数据之间互不冲突(不涉及同步)
TheadLocal在每个线程中是以什么形式存储的? 原理是什么#
这篇文章讲解ThreadLocal源码讲解的蛮好的:
Java并发编程:深入剖析
看完后用我自己的话总结一下就是:
-
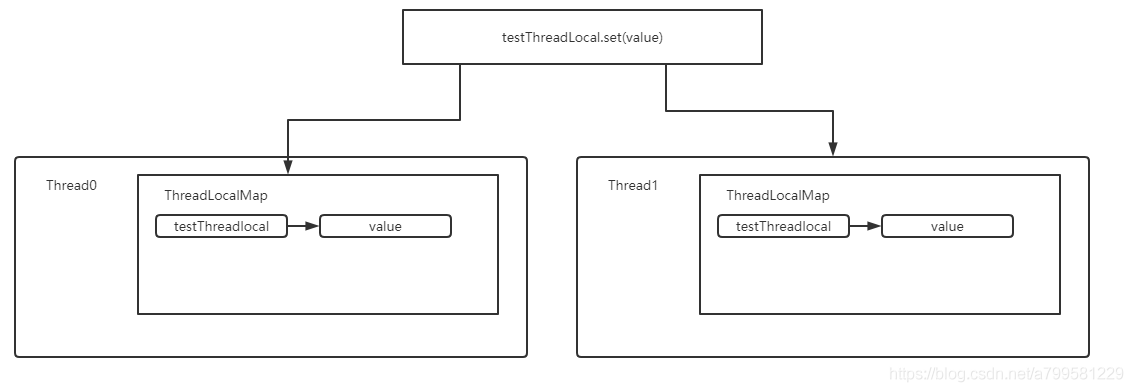
在某个线程中调用 某threadlocal.set(value)时, 其实就是在该线程中新建了1个threalocalMap, 然后把threadLocal作为键,value作为值,放进本线程的threalocalMap中。
-
当在线程中调用threadlocal.get()的时候,就是从线程的threadLocalMap中获取这个threadLocal对应的值
如果get不到,则可以通过自定义initValue方法生成一个threadLocal的默认值
见如下图所示:
下面这个代码会报什么错?(例子改编自上面链接的文章)
1 | public class Test { |
在Thread1中,会报空指针, 因为调用get之前没有做过set, 此时做get会报错。
一种方式改成这样:
1 | Thread thread1 = new Thread(){ |
另一种是给stringLocal设置默认值,这种一般用于能直接根据线程推导出初始值的情况:
ThreadLocal
protected String initialValue() {
return xxx;
};
};
正确set之后, 答案就会返回thread0和thread1, 且后续怎么set,两边都不会互相影响各自的threadLocal,虽然看起来是都用的是同一个Test里的成员。