[toc]
因为http是非常重要的东西,restful经常问道, 所以单独抽出一章节讲解。
这个最好看图解HTTP笔记里的内容。
HTTP常见问题和概念#
Q: Http为什么是无连接 和无状态的?#
A:
- 一.无连接:每一个访问都是无连接,服务器挨个处理访问队列里的访问,处理完一个就关闭连接,这事儿就完了,然后处理下一个新的无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接
- 二.无状态:
- 协议对于事务处理没有记忆能力
- 对同一个url请求没有上下文关系
- 每次的请求都是独立的,它的执行情况和结果与前面的请求和之后的请求是无直接关系的,它不会受前面的请求应答情况直接影响,也不会直接影响后面的请求应答情况
- 服务器中没有保存客户端的状态,客户端必须每次带上自己的状态去请求服务器
Q: 1.1.2 那么HTTP的持久连接又是怎么回事?#
A:
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
TCP短连接长连接都由客户端发起,而TCP长连接的保活功能主要为服务器应用提供。
如果客户端已经消失而连接未断开,则会使得服务器上保留一个半开放的连接,而服务器又在等待来自客户端的数据,此时服务器将永远等待客户端的数据。保活功能就是试图在服务端器端检测到这种半开放的连接。也因为短连接、长连接的实现在HTTP之外,与HTTP无关,从HTTP自身来看,HTTP依然是无连接的
Q: 浏览器从发送到接收,发生了什么?#
A:
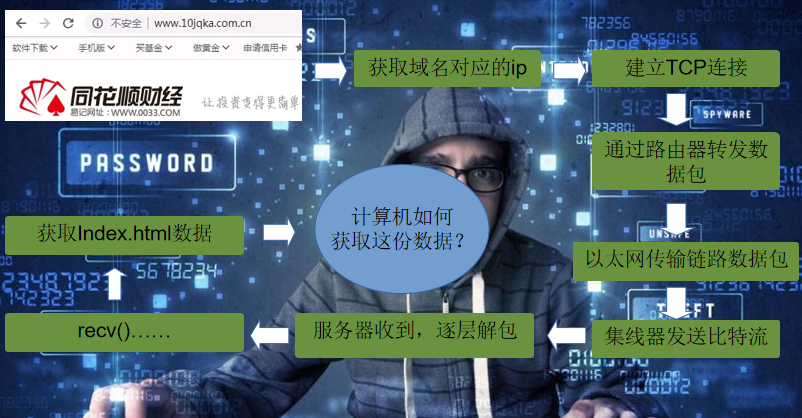
HTTP状态码和重定向#
Q: HTTP状态码有哪些?#
A:
状态码分类表
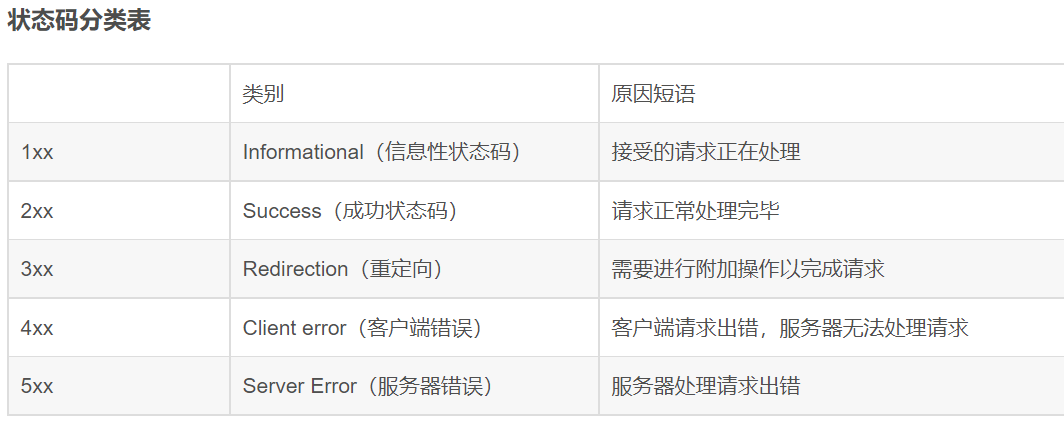
各类别常见状态码:
- 2xx (3种)
200 OK:表示从客户端发送给服务器的请求被正常处理并返回;
204 No Content:表示客户端发送给客户端的请求得到了成功处理,但在返回的响应报文中不含实体的主体部分(没有资源可以返回);
206 Patial Content:表示客户端进行了范围请求,并且服务器成功执行了这部分的GET请求,响应报文中包含由Content-Range指定范围的实体内容。
- 3xx (5种)
301 Moved Permanently:永久性重定向,表示请求的资源被分配了新的URL,之后应使用更改的URL;
302 Found:临时性重定向,表示请求的资源被分配了新的URL,希望本次访问使用新的URL;
301与302的区别:前者是永久移动,后者是临时移动(之后可能还会更改URL)
303 See Other:表示请求的资源被分配了新的URL,应使用GET方法定向获取请求的资源;
302与303的区别:后者明确表示客户端应当采用GET方式获取资源
304 Not Modified:表示客户端发送附带条件(是指采用GET方法的请求报文中包含if-Match、If-Modified-Since、If-None-Match、If-Range、If-Unmodified-Since中任一首部)的请求时,服务器端允许访问资源,但是请求为满足条件的情况下返回改状态码;
307 Temporary Redirect:临时重定向,与303有着相同的含义,307会遵照浏览器标准不会从POST变成GET;(不同浏览器可能会出现不同的情况);
- 4xx (4种)
400 Bad Request:表示请求报文中存在语法错误;
401 Unauthorized:未经许可,需要通过HTTP认证;
403 Forbidden:服务器拒绝该次访问(访问权限出现问题)
404 Not Found:表示服务器上无法找到请求的资源,除此之外,也可以在服务器拒绝请求但不想给拒绝原因时使用;
- 5xx (2种)
500 Inter Server Error:表示服务器在执行请求时发生了错误,也有可能是web应用存在的bug或某些临时的错误时;
503 Server Unavailable:表示服务器暂时处于超负载或正在进行停机维护,无法处理请求;
Q: HTTP的重定向是什么?#
在 HTTP 协议中,重定向操作由服务器通过发送特殊的响应(即 redirects)而触发。HTTP 协议的重定向响应的状态码为 3xx 。
浏览器在接收到重定向响应的时候,会采用该响应提供的新的 URL ,并立即进行加载;大多数情况下,除了会有一小部分性能损失之外,重定向操作对于用户来说是不可见的。
HTTP 的重定向
Q: HTTP的Forward和Redirect 有什么区别?#
A:
直接转发方式(Forward),客户端和浏览器只发出一次请求,Servlet、HTML、JSP或其它信息资源,由第二个信息资源响应该请求,在请求对象request中,保存的对象对于一个每个信息资源是共享的。
间接转发方式(Redirect)实际是两次HTTP请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。
直接转发就相当于:“A找B借钱,B说没有,B去找C借,借到借不到都会把消息传递给A”;
间接转发就相当于:“A找B借钱,B说没有,让A去找C借”。
HTTPS安全#
Q: 讲一下HTTPS双向认证的过程?#
A:
- 服务端发送证书, 证书中包含网站信息、CA签名、网站公钥
- 客户端校验CA签名,确认是CA所签且来源方正是该网站。
- 客户端生成会话密钥
- 客户端用网站公钥对会话密钥进行加密,生成非对称的会话密钥密文
- 客户端发送会话密钥密文给服务端
- 服务端用私钥解密, 得到明文会话密钥。
- 二者使用会话密钥进行加密传输
Q: MD5 在双向认证过程中有什么用?#
A:
对网址申请信息进行摘要, 避免签名内容过长。同时也避免了逆向推导原网址信息的过程。
Q: 什么是证书链?#
A:
-
一个证书或证书链的拆封操作,是为了
从中获得一个公钥。可示为X1p?X1<>,这为一个中缀操作,其左操作数为一个认证机构的公钥,
右操作数则为该认证机构所颁发的一个证书。如果能正确解开,输出结果为用户的公钥 -
证书链验证的要求是,路径中每个证书从最终实体到根证书
都是有效的,并且每个证书都要正确地对应发行该证书的权威可信任性CA。操作表达式为 Ap?A<>B<>,
指出该操作使用A的公钥,从B的证书中获得B的公钥Bp,然后再通过 Bp来解封C的证书。操作的最终结果
说人话就是下游证书解出来是上游父证书的密文公钥,然后继续解
HTTP语义——POST和GET#
Q: post和get的区别是什么?#
A:
- GET参数包含在url中, post参数还包含在requestBody中。 所以不建议用get参数传递敏感信息。
- get最大提交url为2k,即放在url里的参数有限制。 post的requestBody则比get大很多。
- get一次只生成1个数据包(header和data一起发,返回200), post会生成2个(先发header,响应100,再发data,返回200)。
- get请求可以被浏览器主动缓存, post则不会,除非浏览器中主动设置缓存post
- 浏览器回退的时候,get没影响,但是post会再次提交数据,可能导致重复提交。
GET和POST两种基本请求方法的详细区别 - get只接收ASCII码,post则可以在body中传输多种编码内容。
- post比get更安全, 因为参数没有直接暴露在url里。
Q: 上面提到了get缓存, 浏览器怎么确定缓存是否要更新?#
A:
首先, 请求有个Cache-Control, 里面可以指定最大缓存时间。
Q: 如果缓存超期了, 但服务端资源确实没有变化,如何避免客户端重发请求?#
A:
服务端的响应中,携带last-modified时间给客户端。
客户端缓存超期时,把last_modified这个时间传递过去, 服务端校验如果发现时间一致,则不做业务处理,直接返回304, 让客户端直接继续用本地缓存即可。
Q: 上面提到的, 浏览器get缓存,有什么办法避免缓存?#
A: 给get请求的url中加个时间戳。或者设置no-cache指令
关于浏览器缓存的其他解答
Q: 除了POST和GET请求, 还有哪些HTTP方法?#
A:
- HEAD:类似get请求, 返回的响应里不包含body,只给响应报头
- PUT:发送的数据专门用于覆盖某数据
- DELETE:请求服务器删除指定资源或者页面
- TRACE: 回显服务起收到的请求, 用于测试或者诊断
- CONNECT: HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
- OPTIONS: 返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性
Q: 我可以在get里加body么?#
A:
完全可以加,没有问题, GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。 例如某些框架可能针对get和post做过封装来限制一些语义。
Q: post一定就比get安全么?#
A:
如果用了HTTPS, 则post比get安全, 否则是一样的的,因为传输时都是明文传输。
HTTP额外特性#
Q: HTTP的keep-alive和 TCP的keep-alive有什么区别?#
A:
区别一:
- HTTP 的 Keep-Alive,是由应用层(用户态) 实现的,称为 HTTP 长连接;
- TCP 的 Keepalive,是由 TCP 层(内核态) 实现的,称为 TCP 保活机制;
区别二:
- HTTP 的 Keep-Alive 就是实现了这个功能,可以使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,避免了连接建立和释放的开销,这个方法称为 HTTP 长连接
- TCP 的 Keepalive 这东西其实就是 TCP 的保活机制
如果两端的 TCP 连接一直没有数据交互,达到了触发 TCP 保活机制的条件,那么内核里的 TCP 协议栈就会发送探测报文
区别三:
- HTTP添加方式——请求头添加Connection: Keep-Alive
- TCP添加方式——通过 socket 接口设置SO_KEEPALIVE
阿里一面:TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一个东西吗?
Q: 什么是HTTP 流水线技术?#
A:
所谓的 HTTP 流水线,是客户端可以先一次性发送多个请求,而在发送过程中不需先等待服务器的回应,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。HTTP 流水线机制则允许客户端同时发出 A 请求和 B 请求。
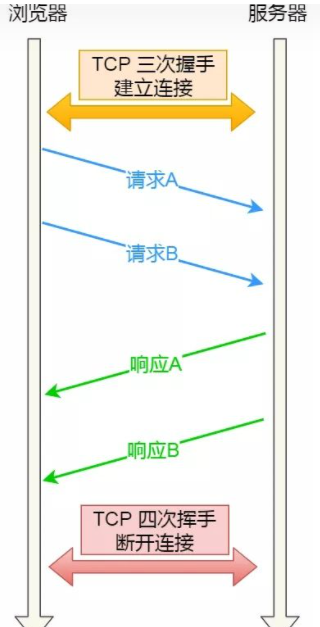
Q: HTTP请求头里有什么东西?#
A:
- Host: www.study.com // 请求的地址域名和端口,不包括协议
- Connection: keep-alive // 连接类型,持续连接
- Upgrade-Insecure-Requests:1 // http 自动升级到https,防止跨域问题但是域名端口都不同的不会提升
- User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36 //浏览器的用户代理信息
- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,
*/*;q=0.8 //浏览器支持的请求类型 - Accept-Encoding: gzip, deflate, sdch //浏览器能处理的压缩代码
- Accept-Language: zh-CN,zh;q=0.8,en;q=0.6 //浏览器当前设置语言
post新加的请求头: - Content-Length: 29 //请求参数长度
- Cache-Control: max-age=0 //强制要求服务器返回最新的文件内容,也就是不走缓存,返回的200
- Origin: http://www.study.com //请求来源地址,包括协议
- Referer: http://www.study.com/day02/01-login.html //原始的url,不带锚点,比方说在谷歌打开百度,feferer显示的是谷歌的url
#
A:
HTTP协议作为无状态协议,对于HTTP协议而言,无状态同样指每次request请求之前是相互独立的,当前请求并不会记录它的上一次请求信息。那么问题来了,既然无状态,那完成一套完整的业务逻辑,发送多次请求的情况数不胜数,使用http如何将上下文请求进行关联呢?机智的人类通过优化,找到了一种简单的方式记录http协议的请求信息.
- 浏览器发送request请求到服务器,服务器除了返回请求的response之外,还给请求分配一个唯一标识ID,协同response一并返回给浏览器。
- 同时服务器在本地创建一个MAP结构,专门以key-value(请求ID-会话内容)形式将每个request进行存储
- 此时浏览器的request已经被赋予了一个ID,第二次访问时,服务器先从request中查找该ID,根据ID查找维护会话的content内容,该内容中记录了上一次request的信息状态。
- 根据查找出的request信息生成基于这些信息的response内容,再次返回给浏览器。如果有需要会再次更新会话内容,为下一次请求提供准备。
根据这个会话ID,以建立多次请求-响应模式的关联数据传递, 这就是cookie和session对无状态的http协议的强大作用。
服务端生成这个全局的唯一标识,传递给客户端用于唯一标记这次请求,也就是cookie;而服务器创建的那个map结构就是session。
#
A:
- Domain:域,表示当前cookie所属于哪个域或子域下面。
对于服务器返回的Set-Cookie中,如果没有指定Domain的值,那么其Domain的值是默认为当前所提交的http的请求所对应的主域名的。比如访问 http://www.example.com,返回一个cookie,没有指名domain值,那么其为值为默认的www.example.com。 - Path:表示cookie的所属路径。
- Expire time/Max-age:表示了cookie的有效期。expire的值,是一个时间,过了这个时间,该cookie就失效了。或者是用max-age指定当前cookie是在多长时间之后而失效。如果服务器返回的一个cookie,没有指定其expire time,那么表明此cookie有效期只是当前的session,即是session cookie,当前session会话结束后,就过期了。对应的,当关闭(浏览器中)该页面的时候,此cookie就应该被浏览器所删除了。
- secure:表示该cookie只能用https传输。一般用于包含认证信息的cookie,要求传输此cookie的时候,必须用https传输。
- httponly:表示此cookie必须用于http或https传输。这意味着,浏览器脚本,比如javascript中,是不允许访问操作此cookie的。
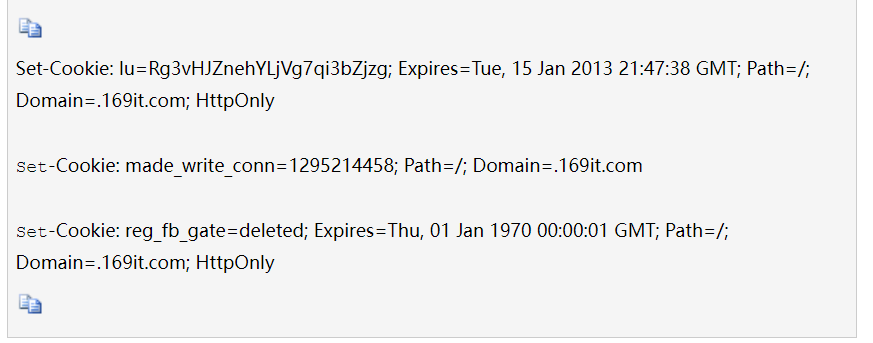
Http协议中Cookie详细介绍
#
A:
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。
常用的会话跟踪技术是Cookie与Session。
-
Cookie通过在客户端记录信息确定用户身份,Cookie具有不可跨域名性
Session通过在服务器端记录信息确定用户身份。 -
Session需要使用Cookie作为识别标志
-
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
-
session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie
Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
#
A:
URL地址重写是对客户端不支持Cookie的解决方案。URL地址重写的原理是将该用户Session的id信息重写到URL地址中。服务器能够解析重写后的URL获取Session的id。这样即使客户端不支持Cookie,也可以使用Session来记录用户状态
Q: 服务端如何涉及高可用的session特性?#
A:
保证session一致性的架构设计常见方法:
- session同步法:多台web-server相互同步数据(代价高,无法水平扩容)
- 客户端存储法:session存到用户本地cookie中(带宽变大,不安全)
- 反向代理hash一致性:四层hash和七层hash都可以做,保证一个用户的请求落在一台web-server上
- 后端统一存储:存到redis集群或者数据库,web-server重启和扩容,session也不会丢失
建议:
web层、service层无状态是大规模分布式系统设计原则之一,session属于状态,不宜放在web层
让专业的软件做专业的事情,web-server存session?还是让cache去做这样的事情吧
Q: token又是什么?#
A:
Token的引入:Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,Token便应运而生。
Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。最简单的token组成:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,由token的前几位+盐以哈希算法压缩成一定长的十六进制字符串,可以防止恶意第三方拼接token请求服务器)。
使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
Token 、Cookie和Session的区别