[toc]
假设此时已经构建好DAG划分好stage,接着就是要分发task了。
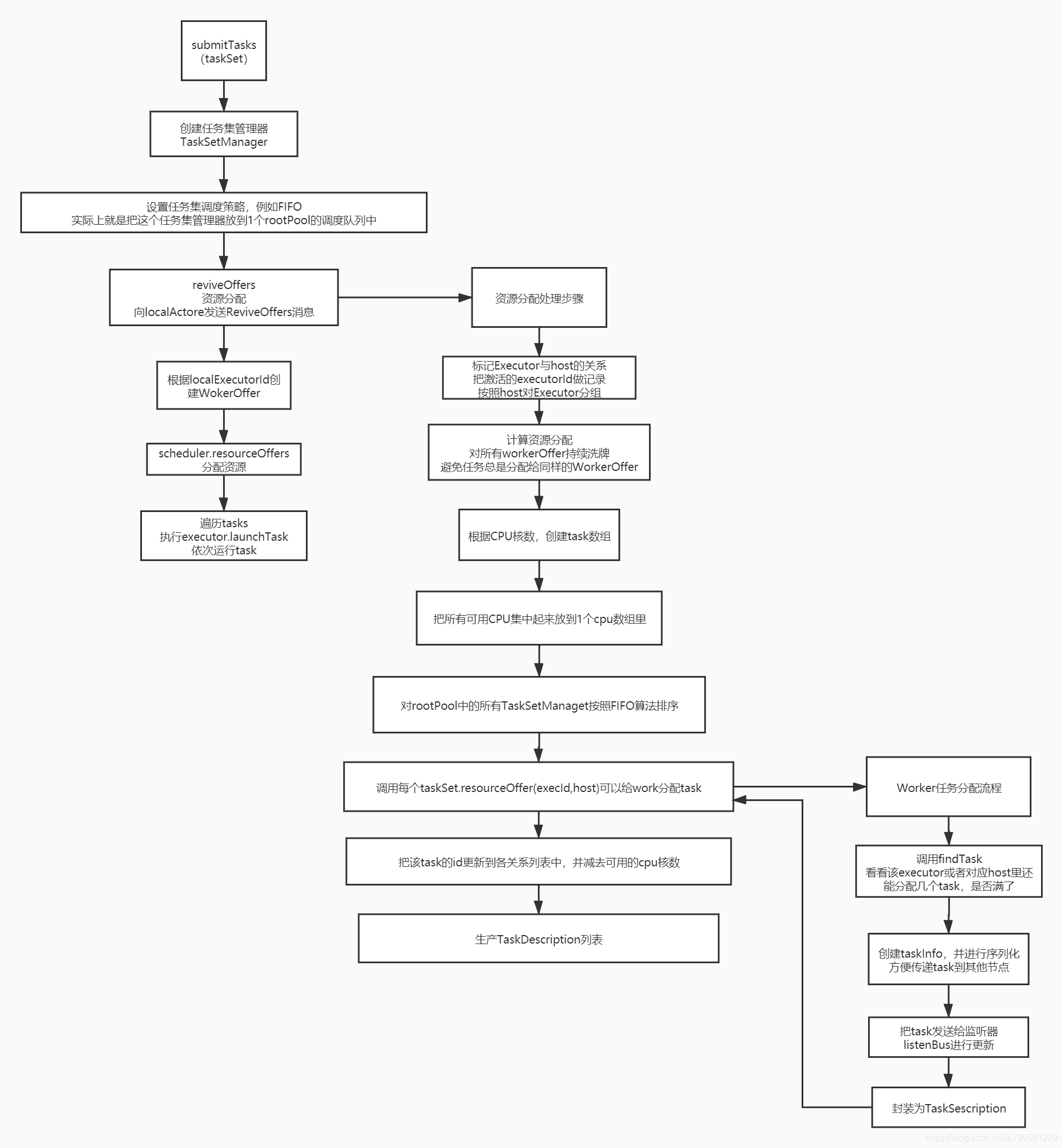
当运行submitTask时,有如下的过程:
上图可以看到,每次都会新建一个专门的taskManager,都运行ok后就会消失,并不是独立持续存在的一个角色。
reviveOffers具体做什么的呢?看一下
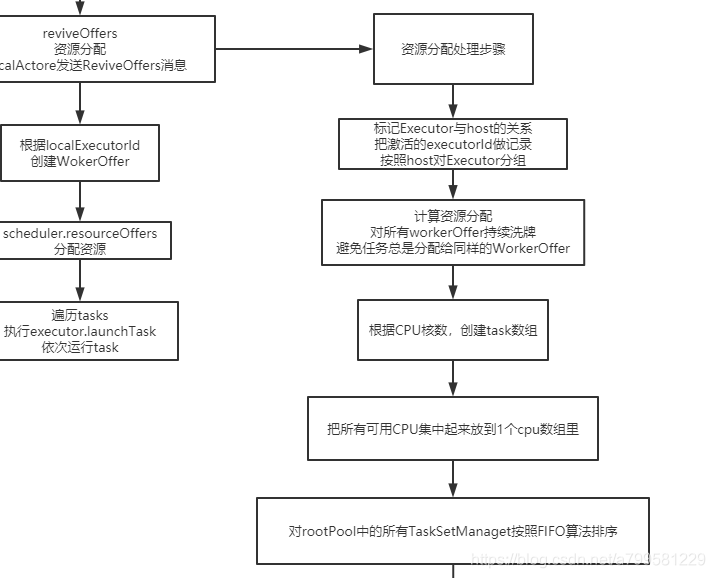
- 可以看到reciveOffer主要是做worker资源分配的。
- workerOffer列表一般需要做随机处理,避免一直分给同一个
- 各机器上的CPU核数在分配的考虑范围之内。
- spark每次可能会有多个TaskSetManager提交到rootPool中, 此时会根据FIO做分配, 先给抵押给TaskSetManager做worker分配,再给第二个分配。
看一下之后做了什么:
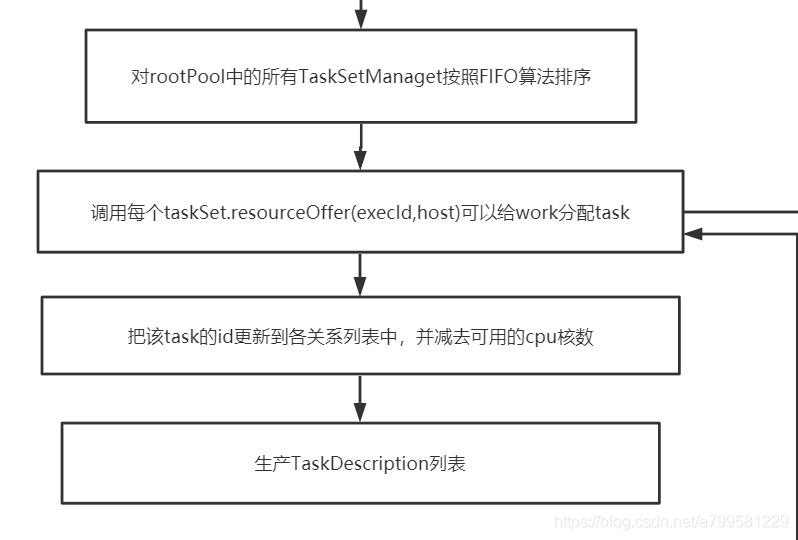
可以看到经过分配后, 各task都绑定到了对应的worker上,生成一个列表,很明显后面就会的、根据这个列表,进行task的发送。
看一下具体的资源的分配过程在做什么:
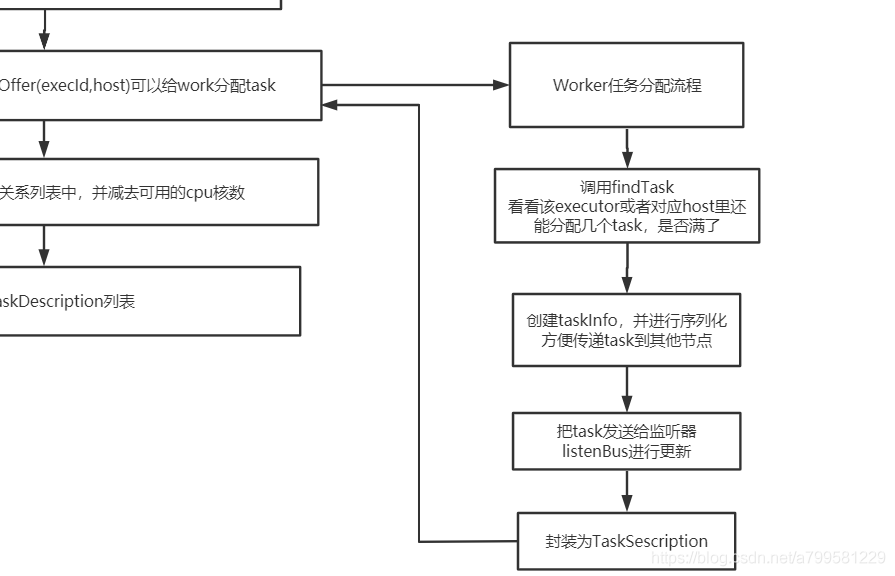
可以看到发送前,会依次检查对应节点的task是否够,如果够就分配一些task给这个几点,并进行序列化。
分配已经完成,回到之前的地方
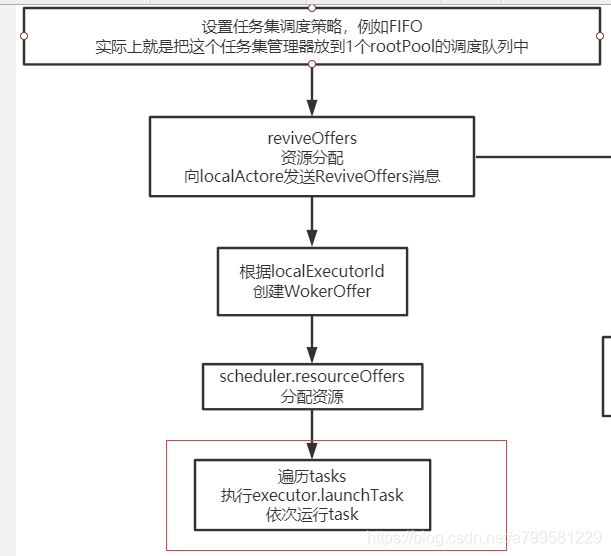
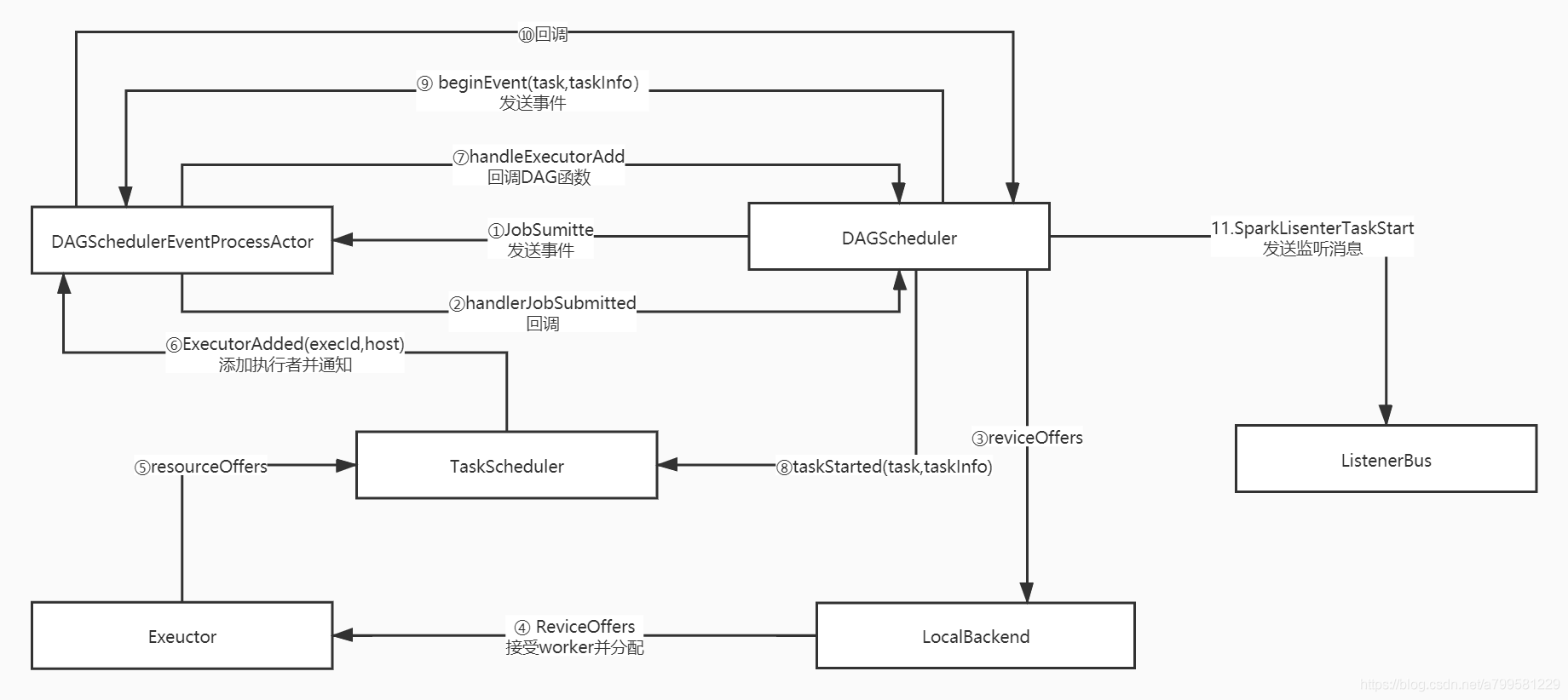
看一下刚才这几个过程在各模块间怎么运行的
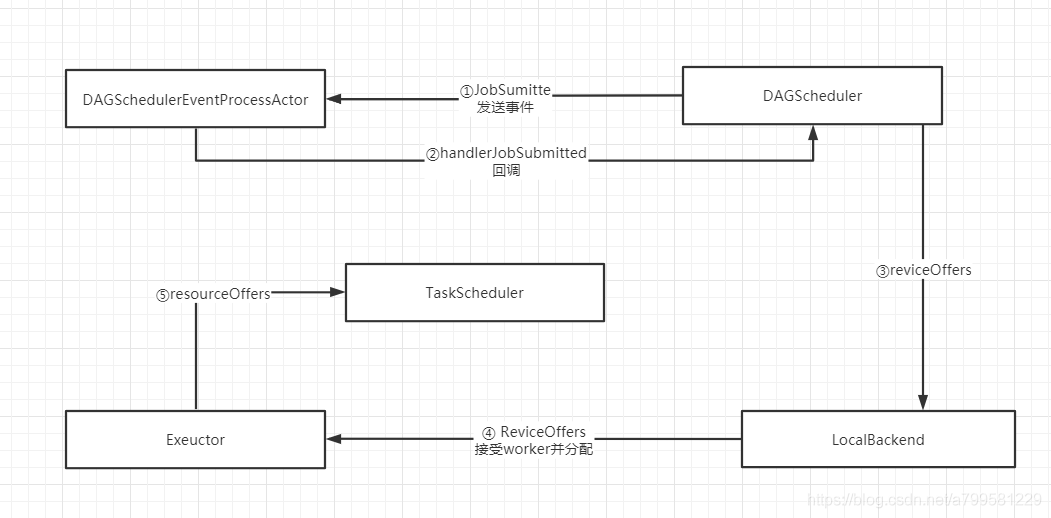
注意每次都是一个新的executor
因此当executor给taskScheduler发消息时
会进行如下操作, 即告诉全局的管理者,我有新的执行者加入了。
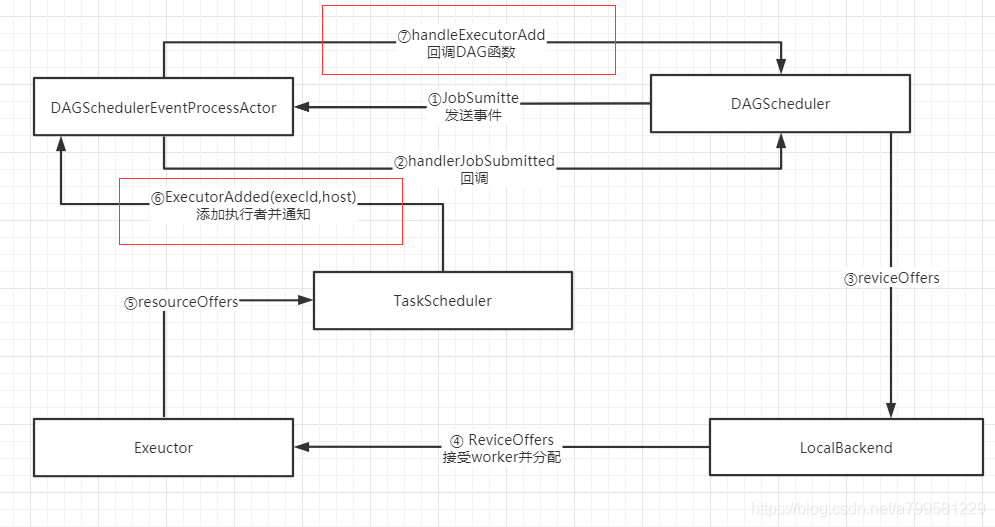
接着DAGScheduer确认到有executor加入后,说明没问题了,于是通知TaskSchduler,去告诉对应的executor,可以运行任务了
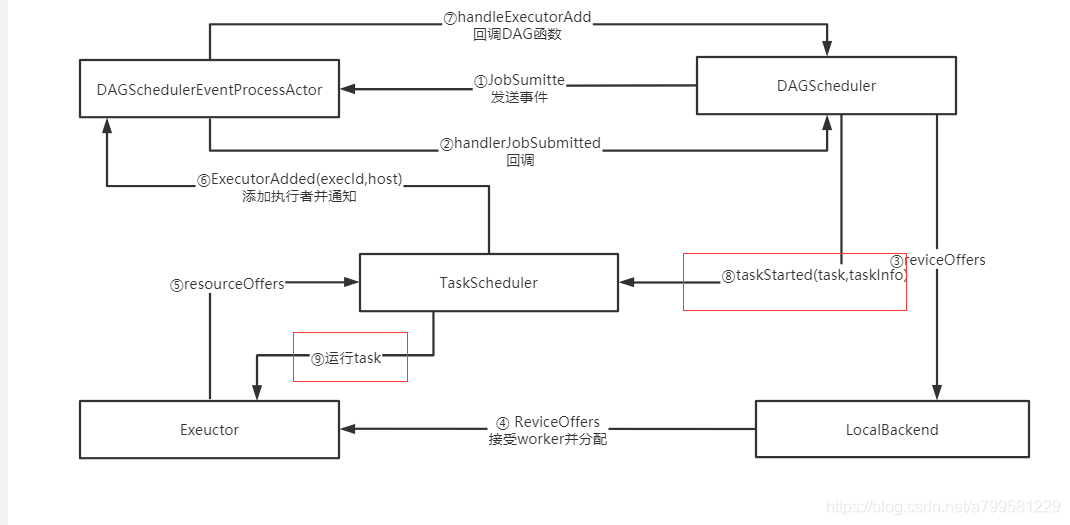
为什么分了那么多角色
我认为是为了解耦。
即DAGScheduler不知道task具体分给了哪个host上。 也不持有exeuctor, 必须通过TaskScheduler来统一调度和通知。
executor执行任务#
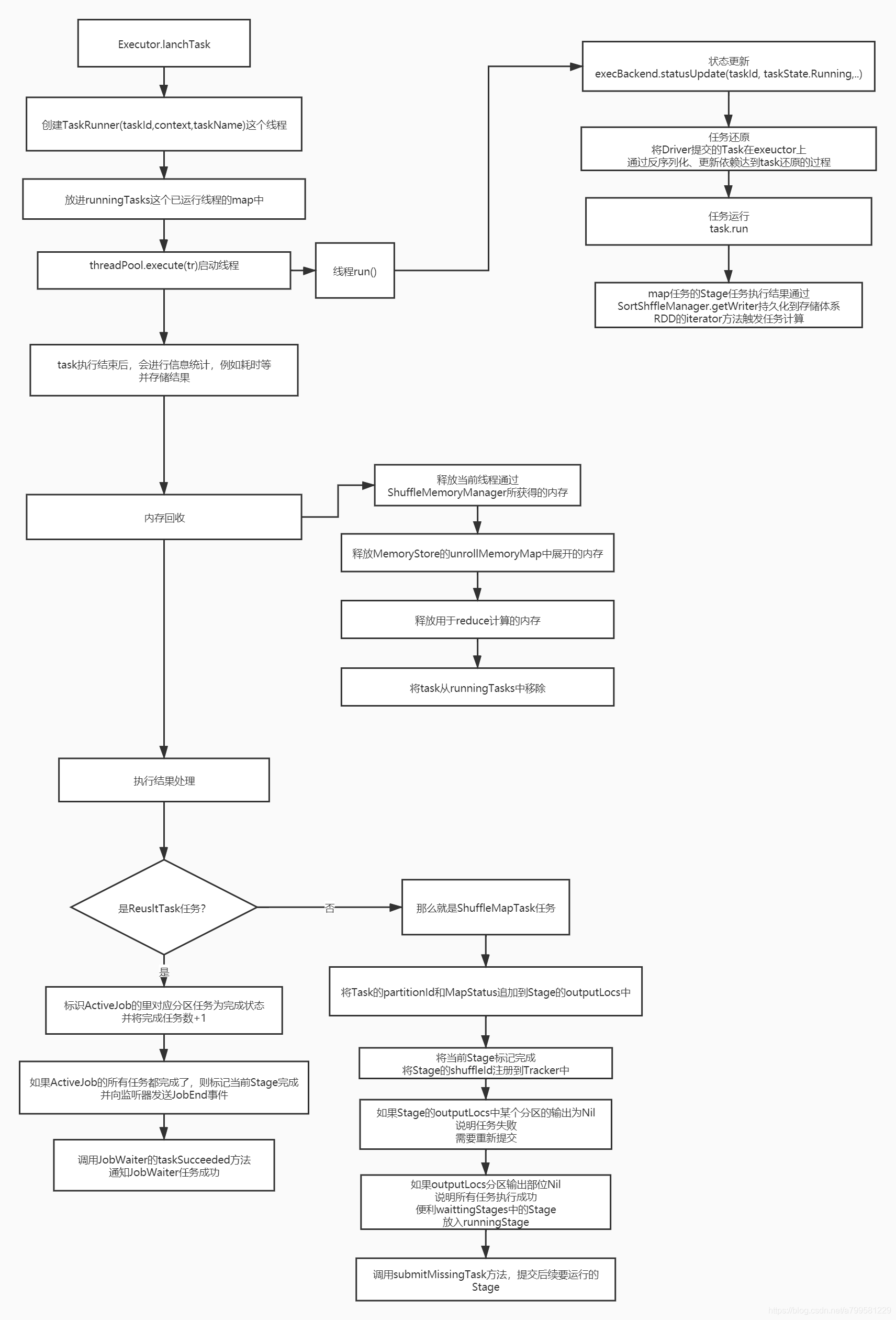
看一下真正执行任务时发生了啥。
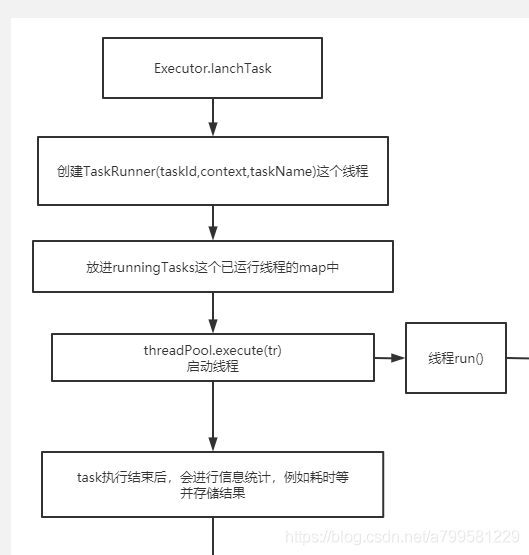
可以看到每个task都是独立一个线程,并放到一个map中做管理。
看一下线程run的时候做了什么
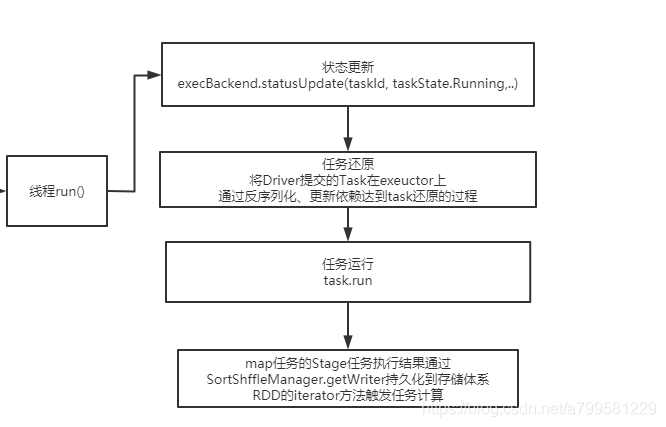
task的反序列化是在task线程中去执行的,即进入线程时,executor根本不知道这是什么任务。
运行的中间结果会做保存。
task线程运行结果后,会进行内存的回收
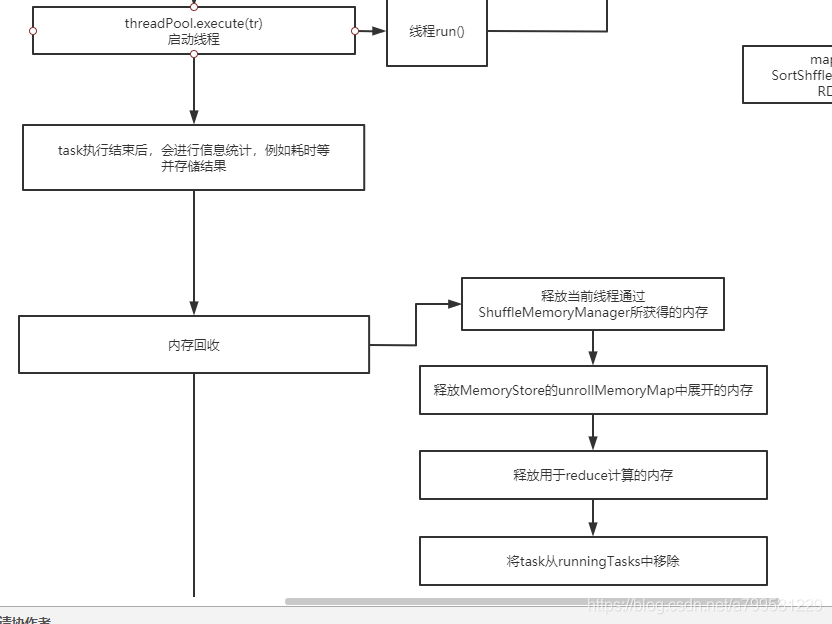
回收内存后开始做最后结果的处理
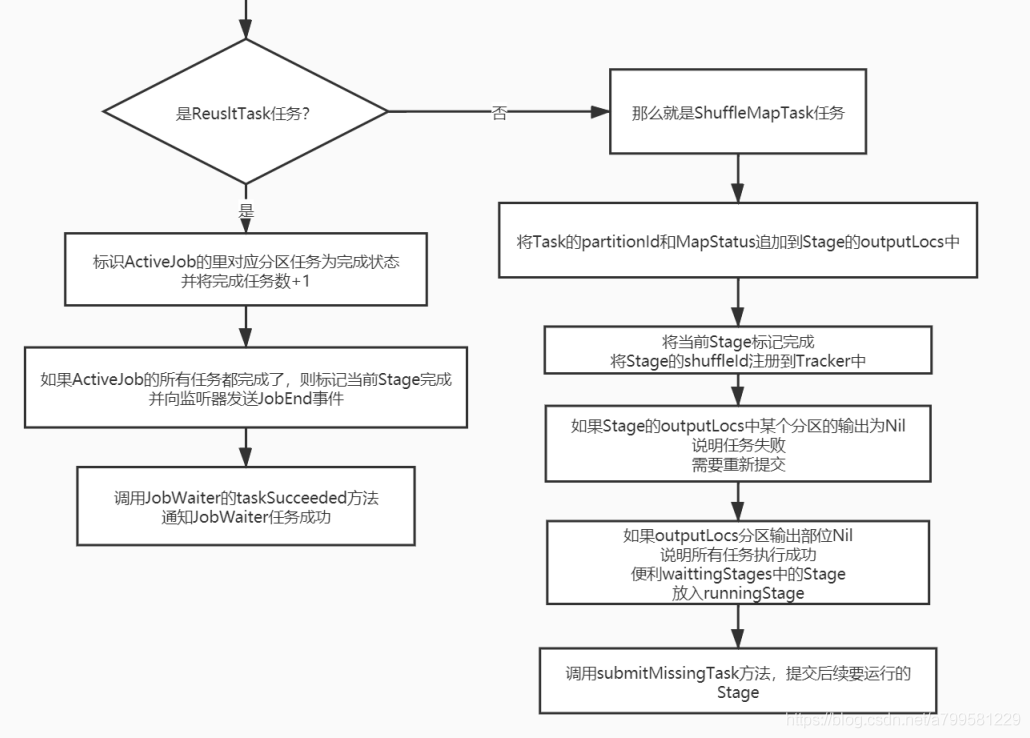
注意任务分成了resultTask和ShuffleMapTask
最终结果任务完成后就不需要再跑stage了
而如果是shuffleMapTask,则需要跑后续的stage,并且会检查一下他的outputLocs分区(这个分区的数据用于给后面的task做拉取), 如果有问题为null,则重新运行再考虑是否通知后续的stak执行。
完整流图#
上面提到的完整图如下: