[toc]
@[toc]
我们看下spark是怎么针对master、worker、executor的异常情况做处理的。
容错机制-exeuctor退出#
首先可以假设worker中的executor执行任务时,发送了莫名其妙的异常或者错误,然后对应线程消失了。
我们看这个时候会做什么事情
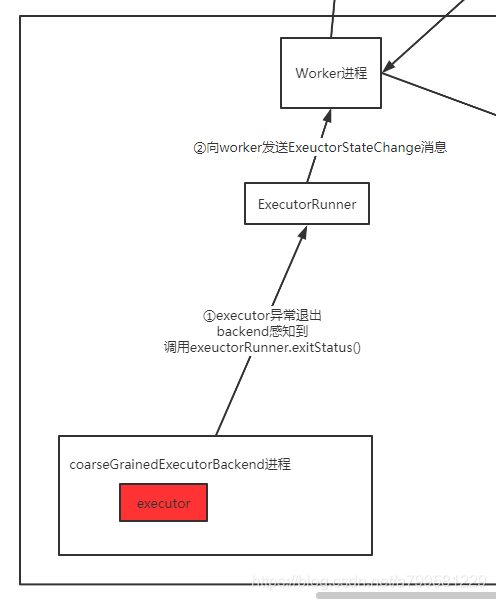
上图总结下来就是:
executor由backend进程包着,如果抛异常,他会感知到,并调用executorRunner.exitStatus(), 通知worker
看下通知worker之后发生了什么:
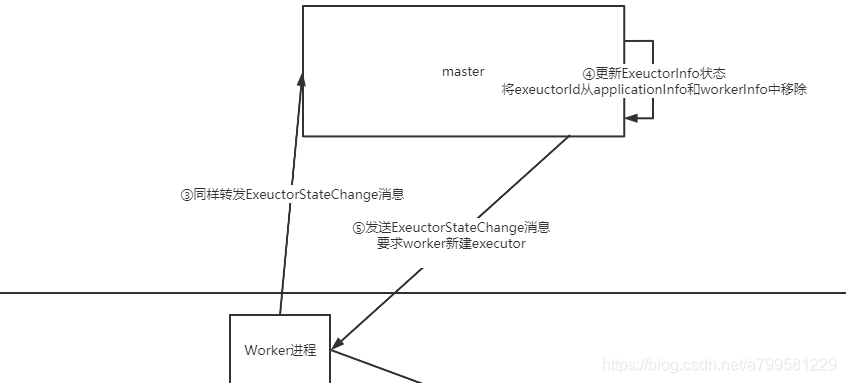
- worker会通知master,master会将exectorInfo清除,然后调度worker让他重新创建
- 这里可以看到worker创建executor的指令仍然是让master来调度和管理的,不是自己想创建就创建。
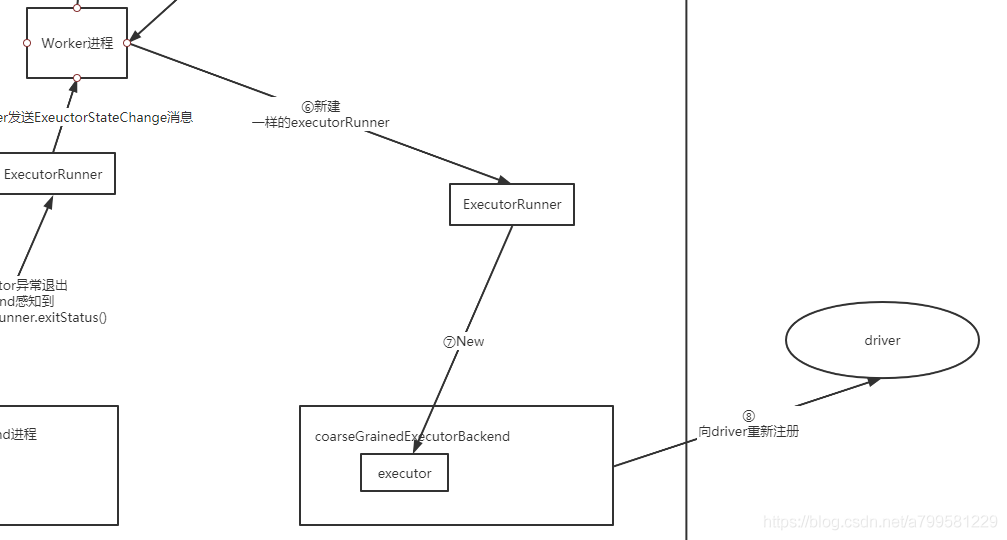
接下来就是重建executor,然后重新开始执行这个地方的任务了(因此数据也会重新拉,之前发送端缓存的数据就能够派上用场了)
完整流程图如下:
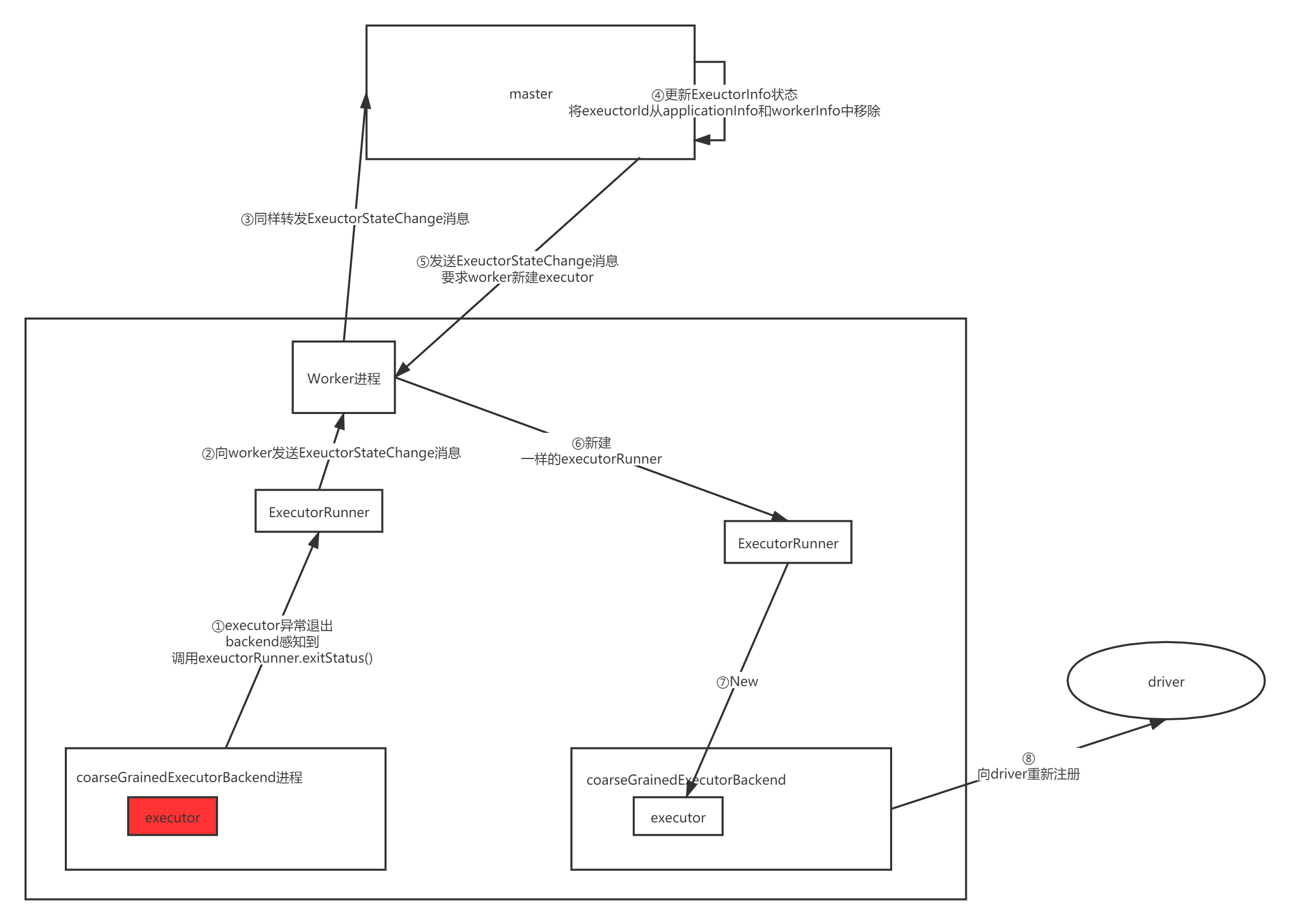
worker异常退出#
假设此时是worker挂掉了, 那么正在执行任务的exeuctor和master会怎么做呢?如下:
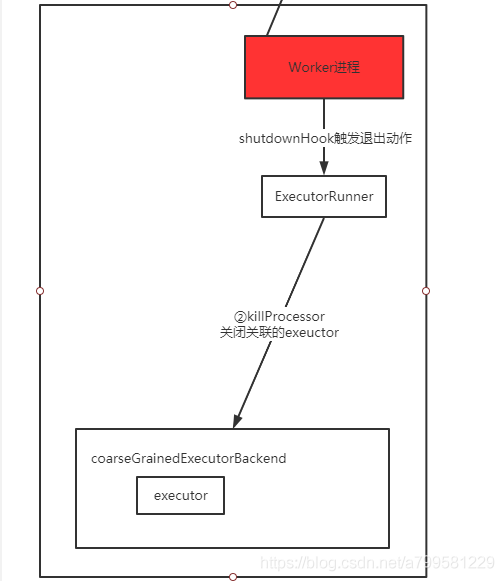
可以看到worker有一个shutdownHook,会帮忙关闭正在执行的executor。
但是此时worker挂了,因此没法往master发送消息了,怎么办?
上一节有讲到master和worker之间存在心跳,因此就会有如下处理:
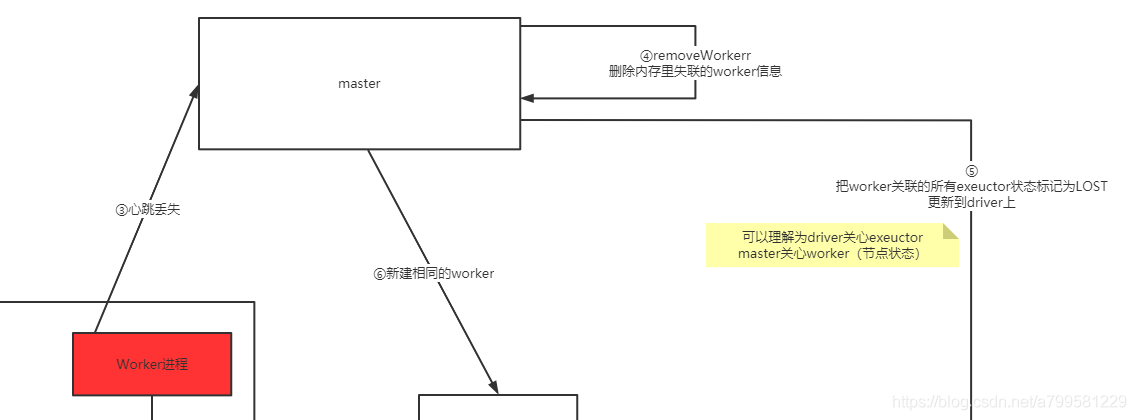
可以看到当master发现worker的心跳丢失时,会进行:
- 删除执行列表里的worker信息
- 重新下发创建worker的操作给对应spark节点
- 通知driver这个worker里面的exector都已经lost了
看下此时worker重建和driver分别做了什么:
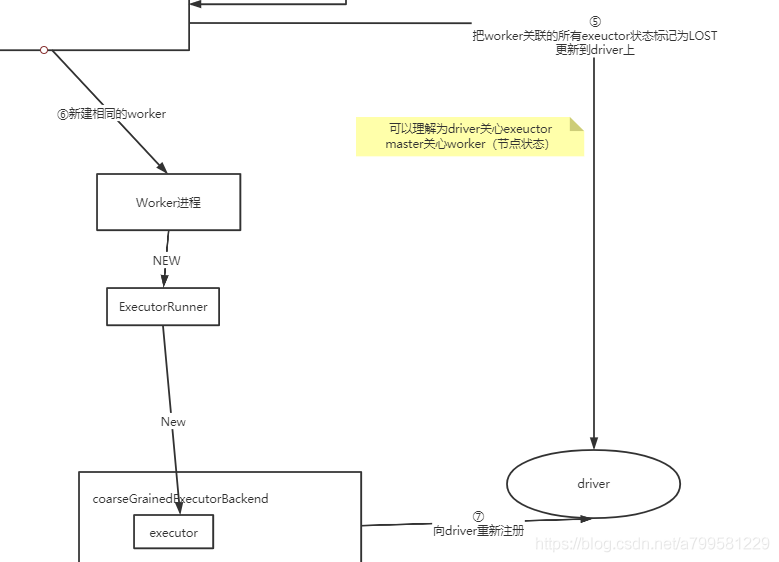
这里还可以看到1个很重要的概念:
- master关心worker状态
- driver会关心executor进展
- exeuctor重建后需要注册到driver上
完整流程图如下:
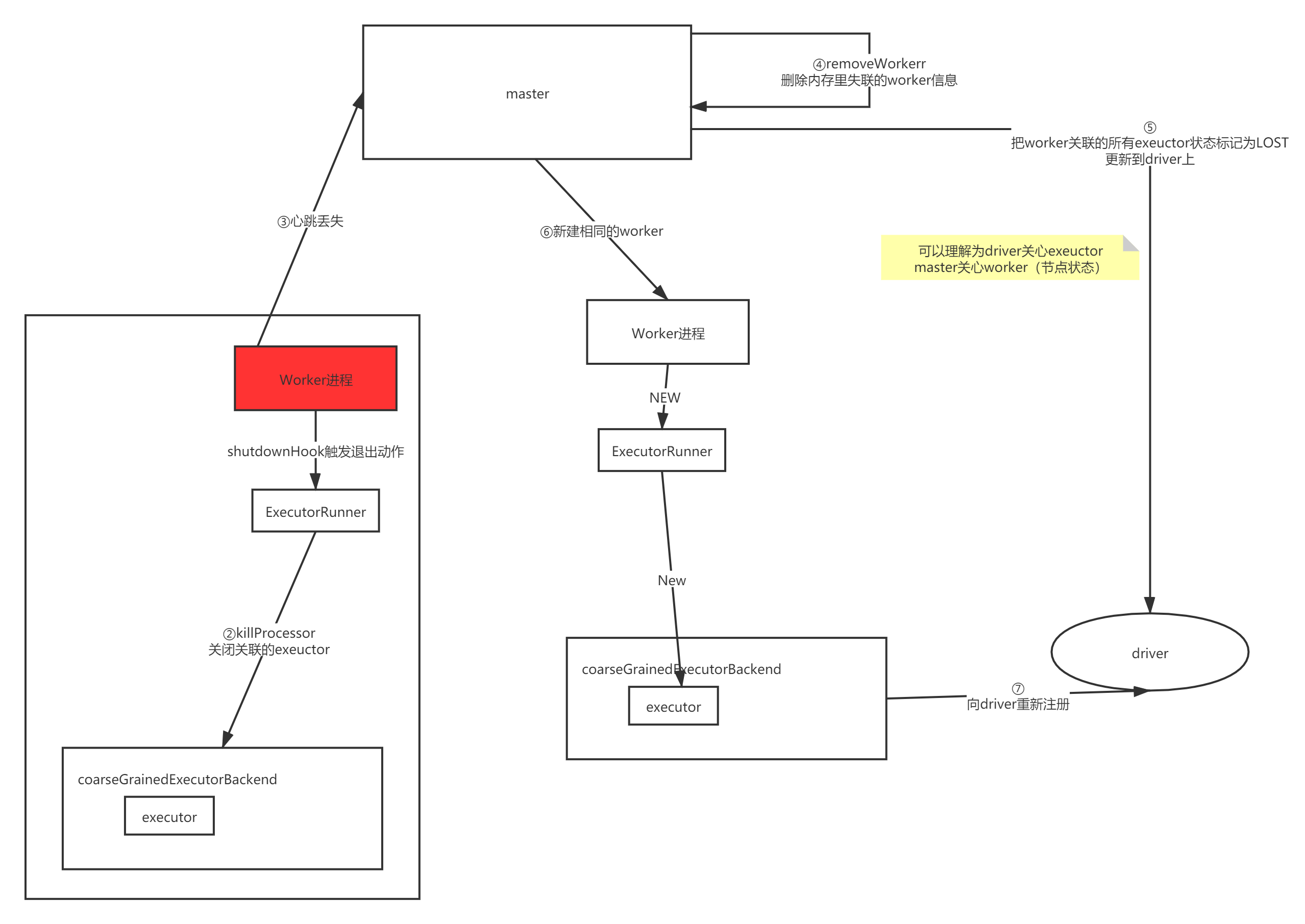
master异常#
由于master不参与任务的计算,只是对worker做管理,因此对于master的异常,分两种情况:
1:任务正常运行时master异常退出#
则流程如下:
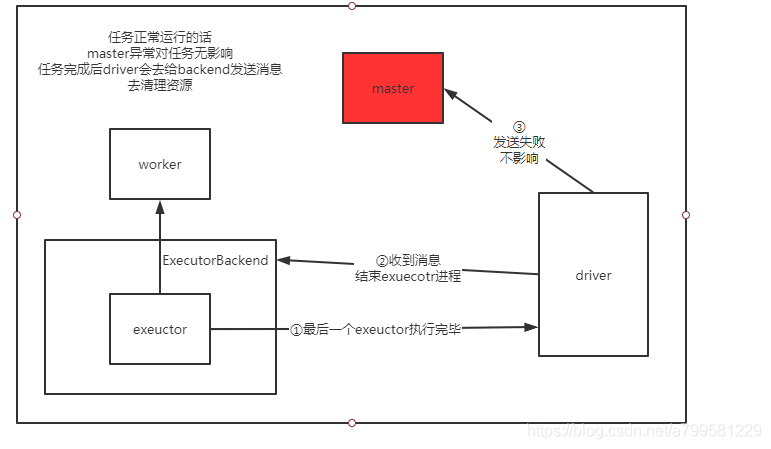
从这里可以看到当任务正常运行时,只会在结束时,由driver去触发master的清理资源操作,但是master进程已经挂掉了,所以也没关系。
2:当任务执行过程中,master挂掉后,worker和executor也异常了#
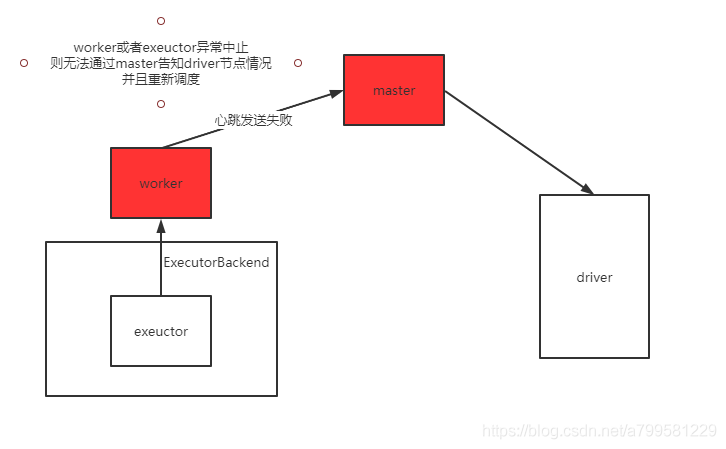
可以看到这时候时没办法重启exeuctor的
此时driver那边就会看起来任务一直没进展了。
为了避免这种情况,master可以做成无状态化,然后做主备容灾。当然master节点做的时候比较少,一般不容易崩溃,除非认为kill或者部署节点故障。