[toc]
简述spark的任务运行流程#
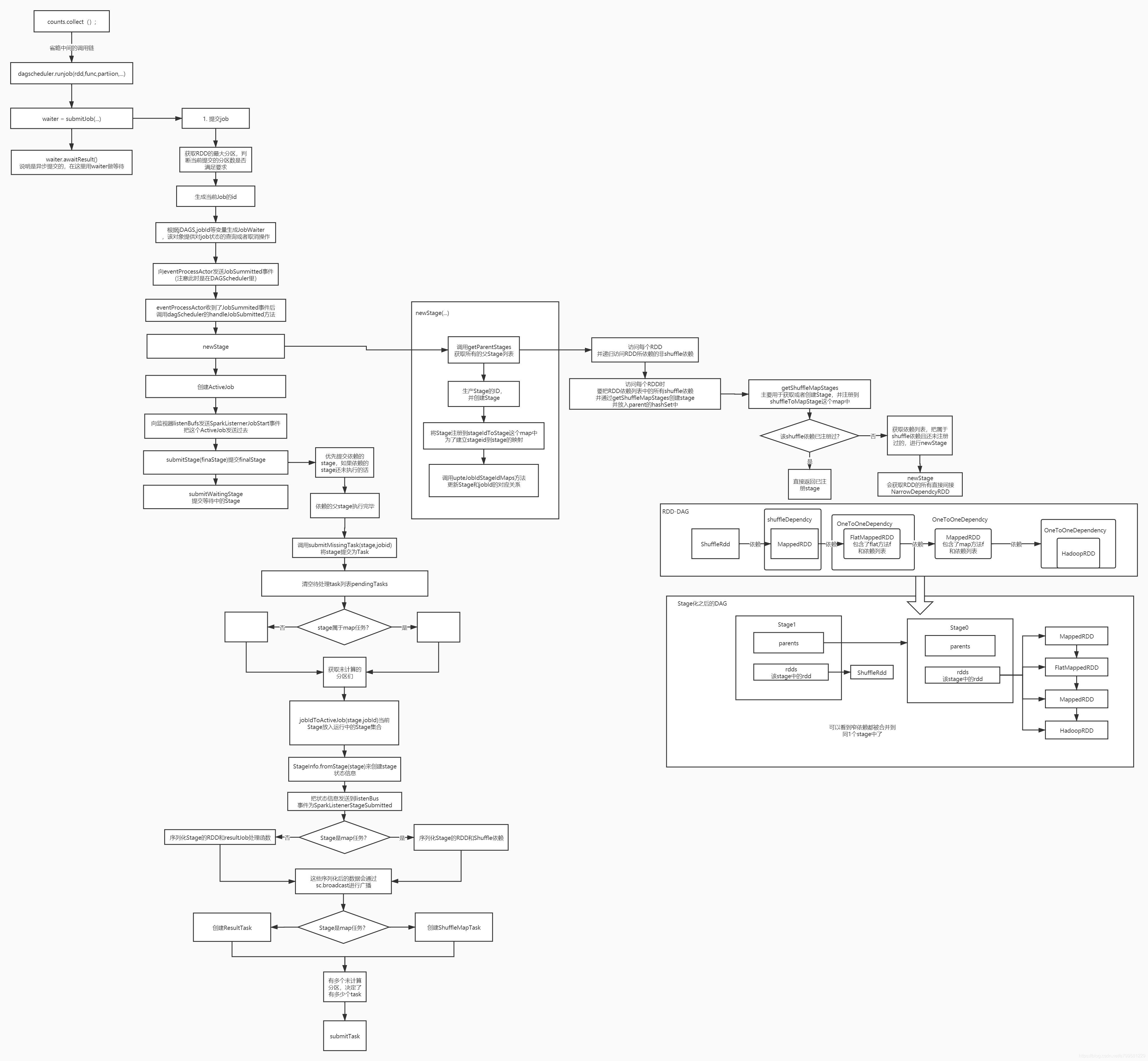
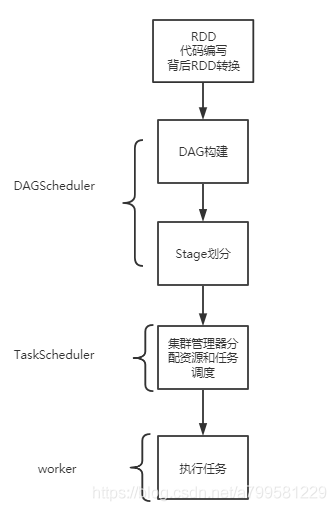
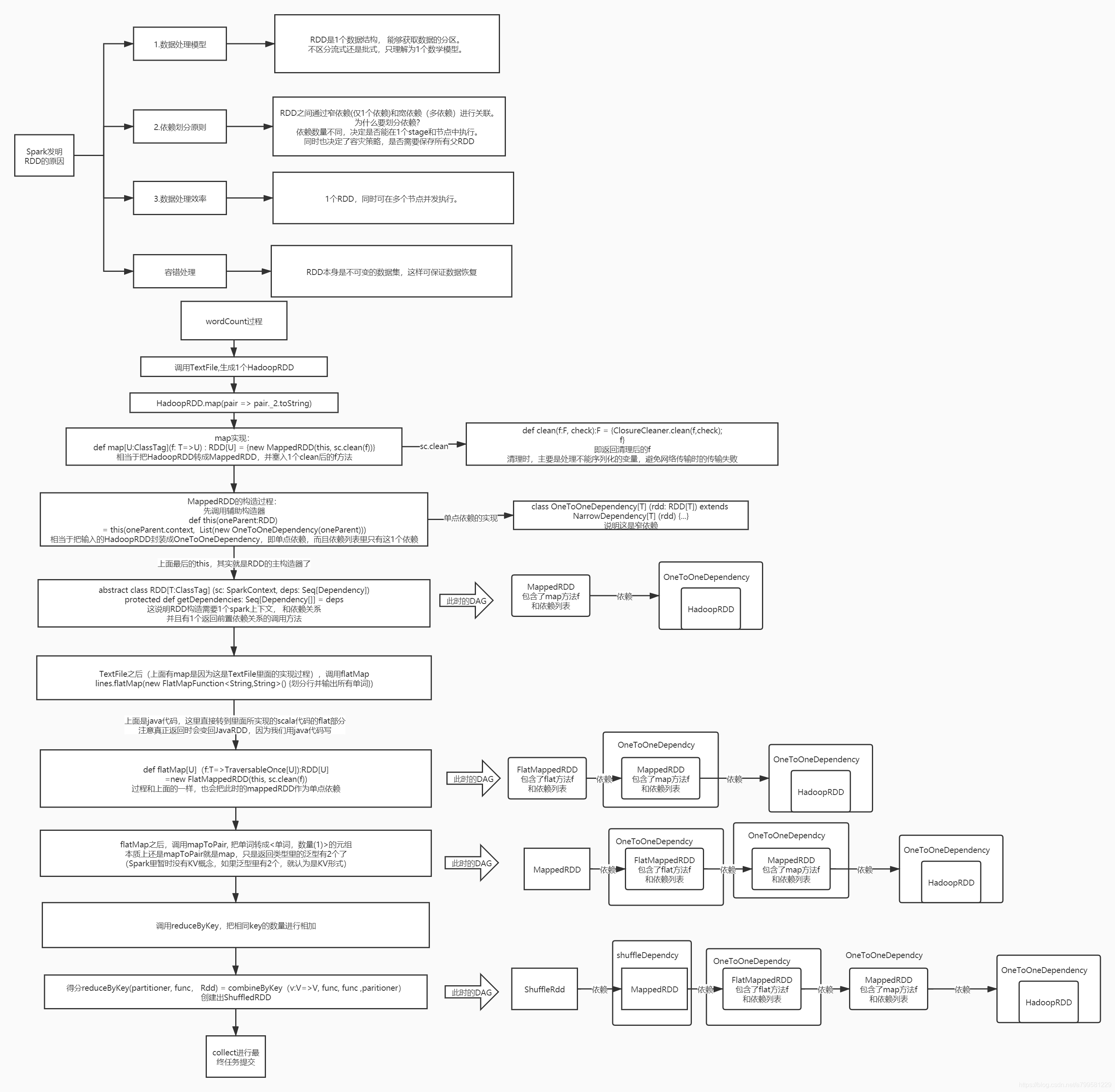
先是在写spark代码的时候,背后做一些RDD的转换,写完后构建DAG,划分stage, 然后提交到资源管理器分配计算资源, 并在worker上执行。
首先写spark代码时离不开对RDD的调用,那么:
为什么需要RDD#
-
数据处理模型统一:
RDD是1个数据结构, 能够获取数据的分区。
不区分流式还是批式,只理解为1个数学模型。 -
依赖划分原则:
RDD之间通过窄依赖(仅1个依赖)和宽依赖(多依赖)进行关联。
为什么要划分依赖?
依赖数量不同,决定是否能在1个stage和节点中执行。
同时也决定了容灾策略,是否需要保存所有父RDD -
数据处理效率:
1个RDD,同时可在多个节点并发执行。 -
容错处理:
RDD本身是不可变的数据集,这样可保证数据恢复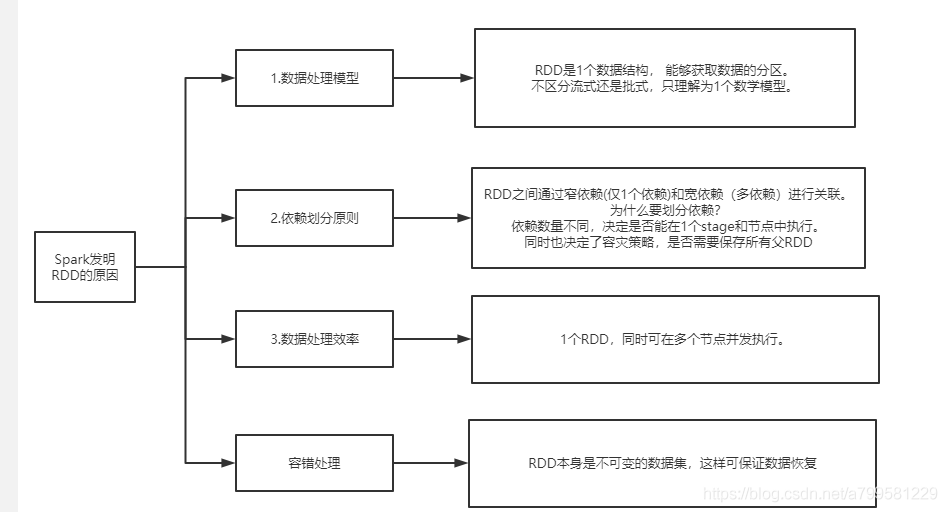
wordCount代码的背后#
以wordCount代码为例
textFile#
第一步是读文件数据。
1 | JavaSparkContext ctx = new JavaSparkContext(sparkConf); |
这一步会生成HadoopRDD
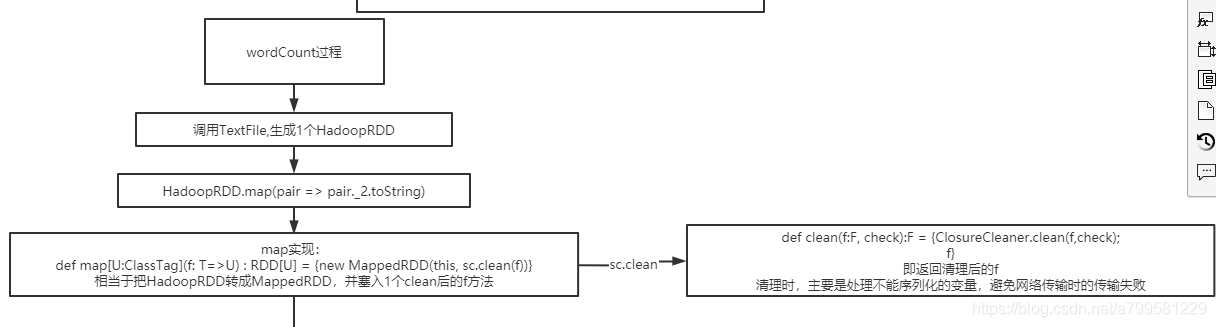
这里注意下, 里面有一个清理序列化的操作, 分布式传输数据时,序列化很重要,而序列化时有些成员是无法被序列化的,在java中的关键字是transien.
MappedRDD是什么?
如下:
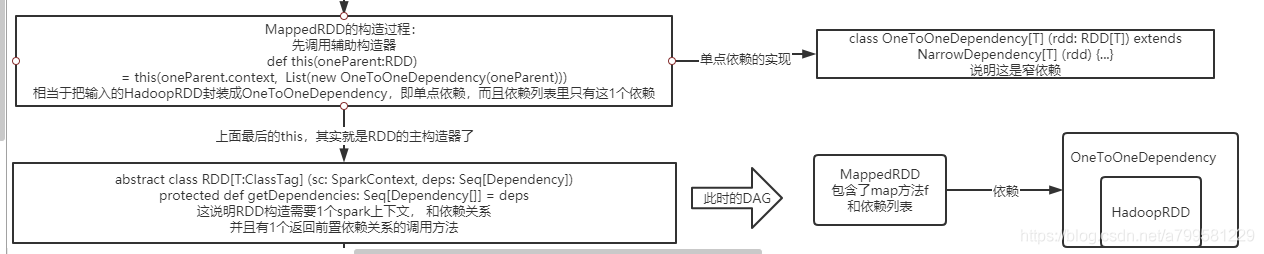
即我们的RDD,会被包装到一个单点依赖的对象里,并指明这是单点依赖。
并且textFile这个过程, 其实是生成了2个RDD, 1个是HadoopRDD,还有一个是读取数据转成字符串的mapRDD。 他们各自被塞进dependecy对象中,并通过依赖建立连接。
- 注意,一般分布式计算设计DAG图时, 都是只有input指针(即用输入对象做连接), 利用input来确定DAG关系。 在spark里就是依赖dependency的概念
第二步做FlatMap#
接着我们调用flatMap
1 | JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){ |
背后的RDD和依赖i情况变成如下:

第三步mapToPair#
懒得敲了,这里省略java代码。

看一下dag。
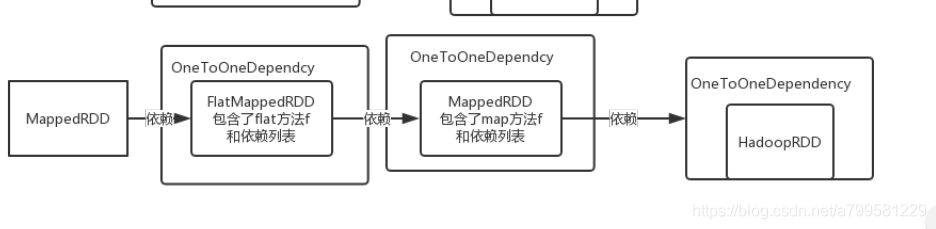
第四步聚合#
需要分组,然后进行合并相同的单词数量
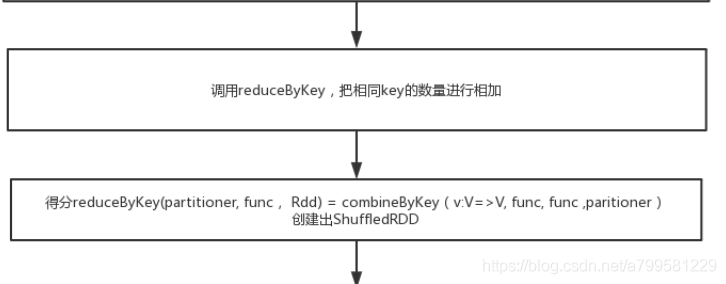
此时dag如下:
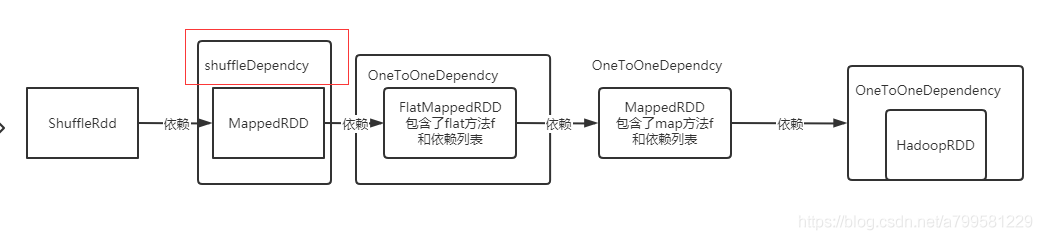
- 注意, 并不是shuffle这个RDD被包装进了shuffle依赖, 而是它的前置RDD被包进了shuffle依赖。
- 即dependency确实是只包装依赖的, 你如果是属于某个shuffle过程的依赖,那么就会被包装成shuffleDepnecy。
最后一步collect#
当写完后,执行collet,进行计算执行和提交。
完整流程如下:
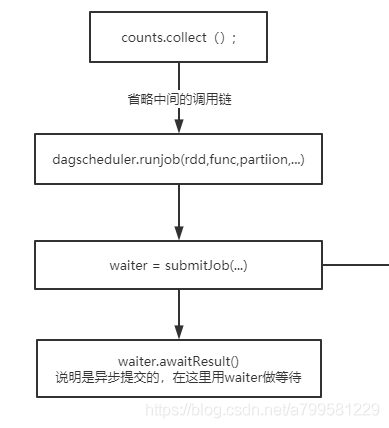
Collect的时候发生了什么#
collect后, 会通过dagScheduler进行runJob, submitJob的时候会返回一个waiter,在client端主程序中就会进行等待。
即client端提交任务时其实是异步的,会返回一个waiter进行等待,
看一下submitJob的时候发生了什么
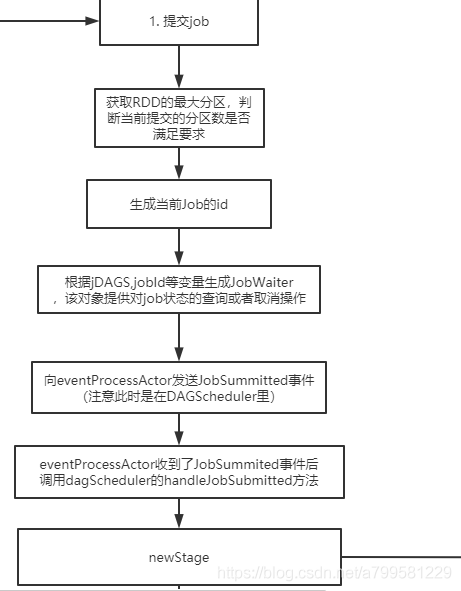
前面看起来都是一些业务处理, 关键在handleJobSumitted的时候,会做一个newStage的操作,正好可以看一下spark里的stage是怎么确定和生成的。
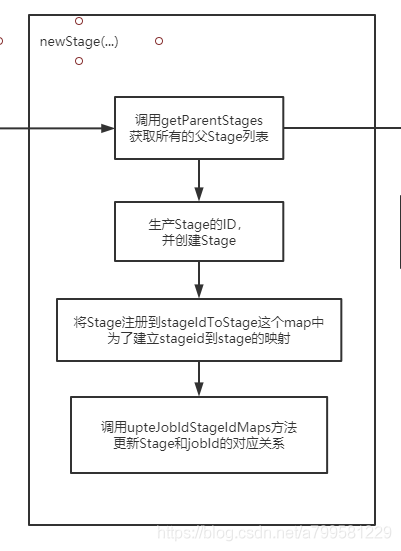
父(依赖)stage列表是怎么获取的?

上图里的关键信息在于, 当遇到shuffle的时候,就会隔离出一个stage。
可以看一下之前提到的RDD拼成的DAG图,如下:

newStage后,有如下情况:
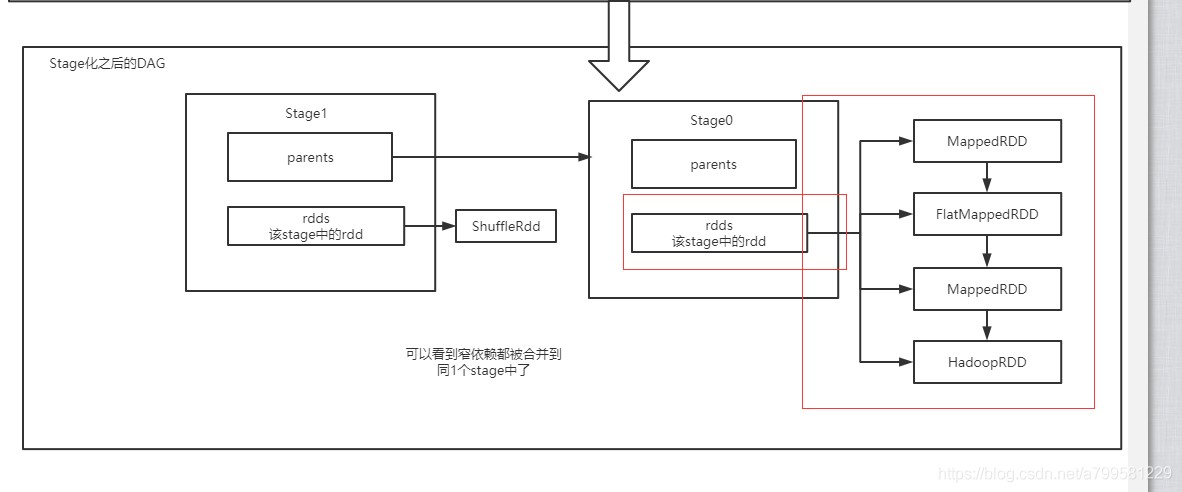
可以看到又给stage里有一个rdds的数组, 里面放了该stage的所有RDD, 并建立了依赖关系。
然后每个stage又通过parent去确定依赖关系。
stage提交#
newStage之后,会进行stage的提交
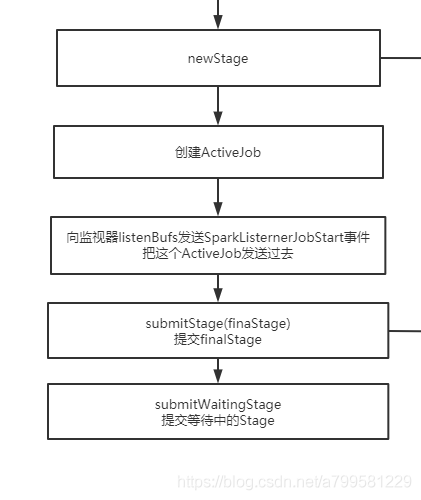
看一下submitStage的时候做了什么,注意此时是先从finalStage开始提交的。
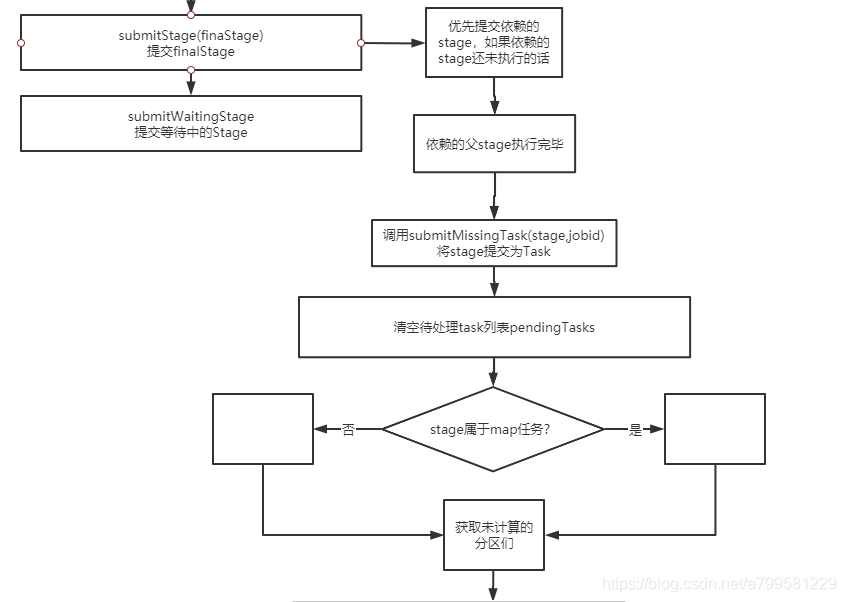
这里可以看到, 虽然我们做了finalStage的提交, 但是会优先提交它所依赖的前置stage, 一直等待stage 完成了再真正提交自己这个stage。
这里看一下 stage是怎么发送的
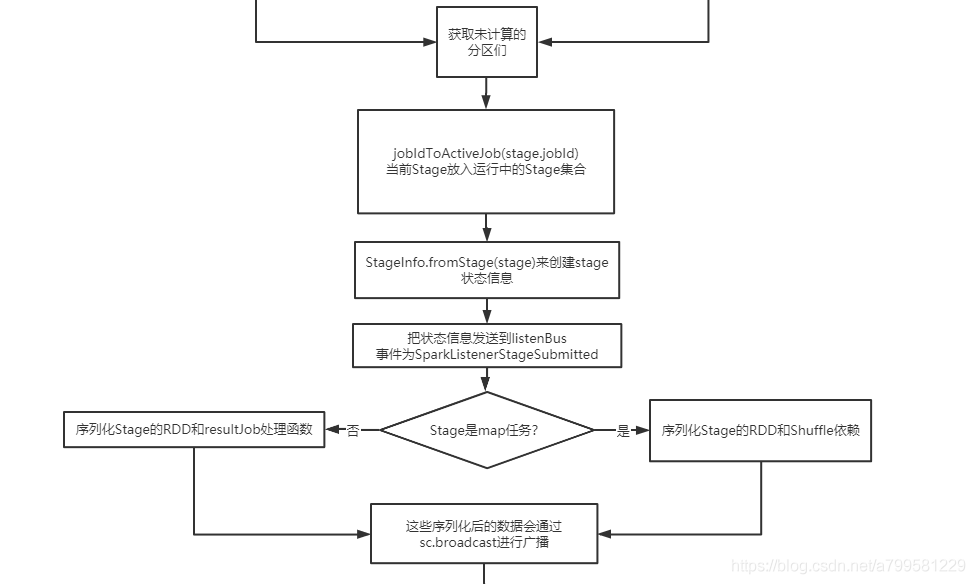
上图可以看到stae座位task时,也是区分shuffle类型和map类型。
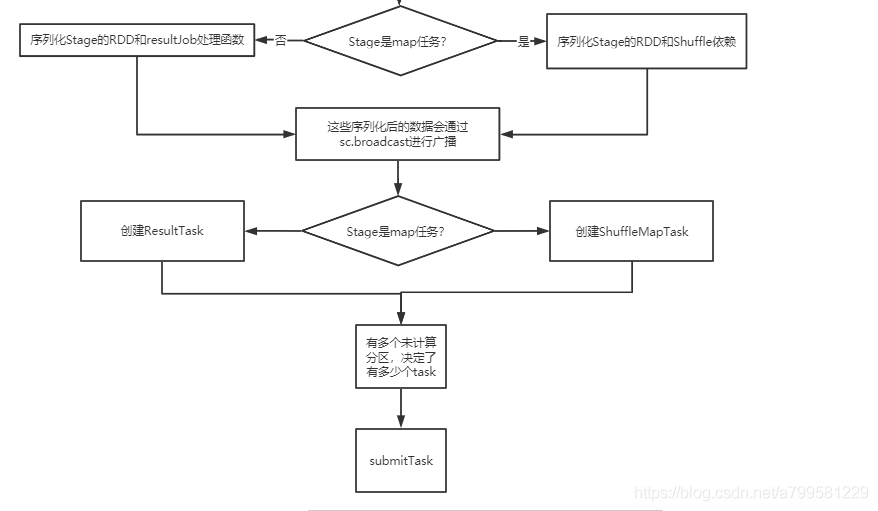
- 这句话重点: 有多少个未计算的分区,决定了有多少个task, 即stage中的分区和task一一对应
完成的stage创建和提交流程图如下: