[toc]
spark的reduce过程究竟做了什么呢?我们可以看一下:
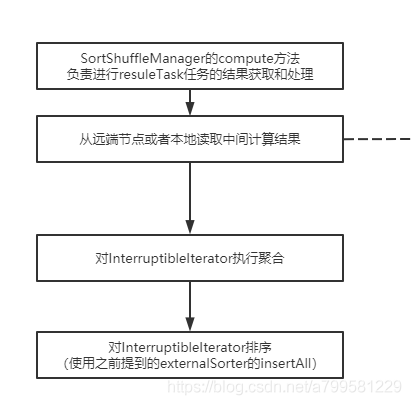
先拉取数据,在聚合,最后会调上一章讲map操作时的insertAll方法即缓存结果的方法。
如何做reduce聚合没啥好说的,我们看下他是怎么读取中间计算结果的
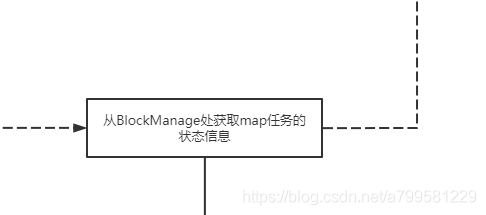
1.从BlockManage处获取map任务的状态信息#
首先会试图获取任务的状态信息,以确认当前从哪里读取数据
我们看下是从具体的获取信息过程:
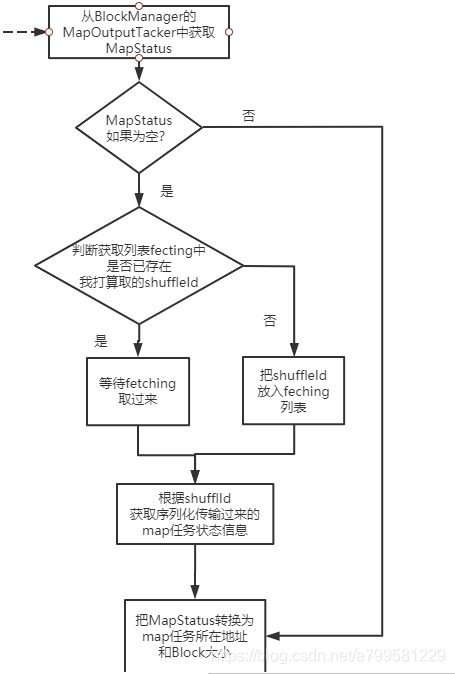
可以看到有以下关键点:
- reduce的上游任务节点状态一开始是不确定的, 如果没有需要自己根据shuffleId去拉取过来。
- 取状态信息时,不是马上就去取,而是放入一个fetching队列里取,避免同时发送过多的零碎状态信息请求。
注意这个时候还没有真正拿到数据,只是获取了数据的情况。
2.使用splitLocalRemoteBlocks方法 ,按照中间结果所在节点划分各个Block#
获取了上游任务节点该map数据的状态,那么接着是划分block,以确认是本地还是远程。 看下是怎么做block划分的:
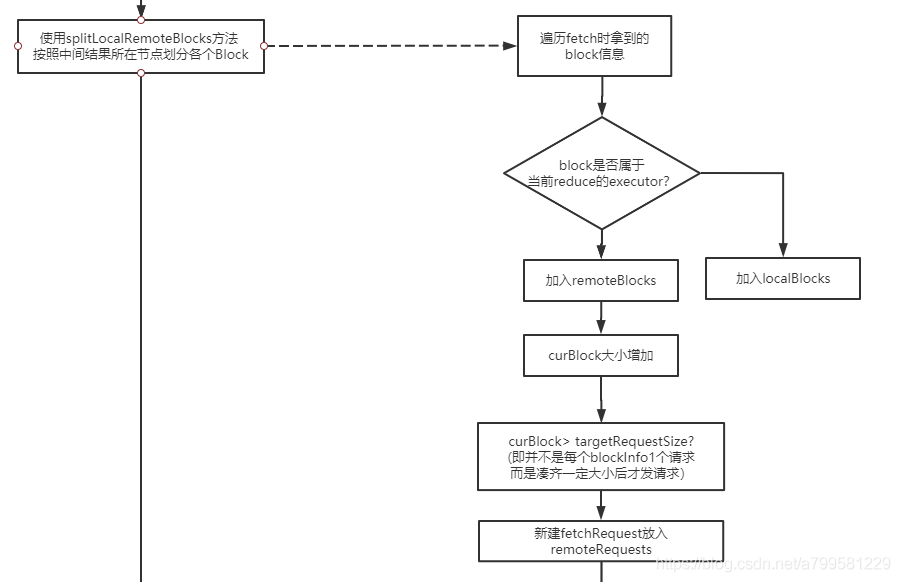
有以下特点:
- 只有非自己当前节点的数据,才需要去远程获取。
- 每次是凑齐了一堆块的数量才去取,而不是频繁地取。
3.创建ShufleBlockFetcherIterator迭代器,从远端节点读取中间计算结果 #
#
接着就是要读取了,看下怎么读的:
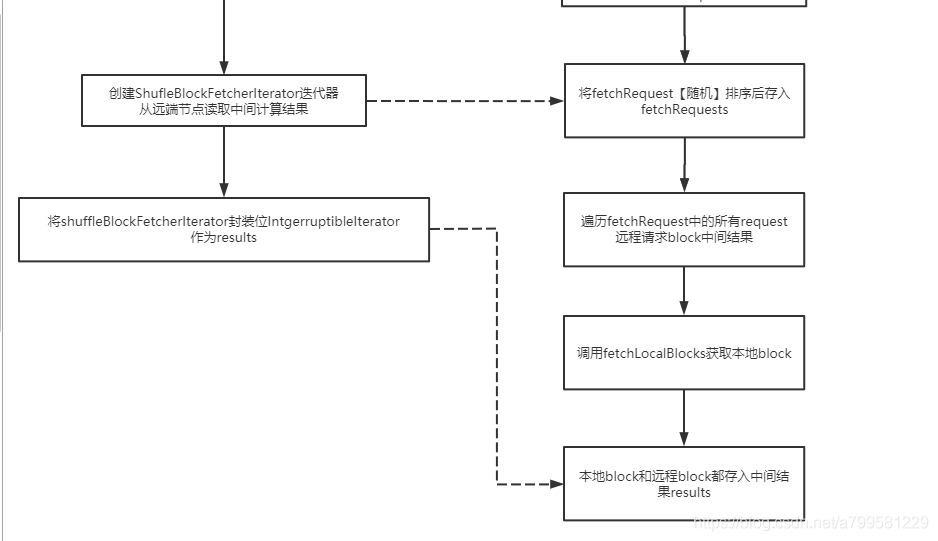
有以下特点:
- 发送fetch请求时, 会做随机排序(因为取的数据可能来自多个节点,为了避免总是只取1个节点的,选择了随机取)
取完数据之后,就是调用之前map操作里也调用过的insertAll放去缓存或者先计算再缓存,提供给下游调用。
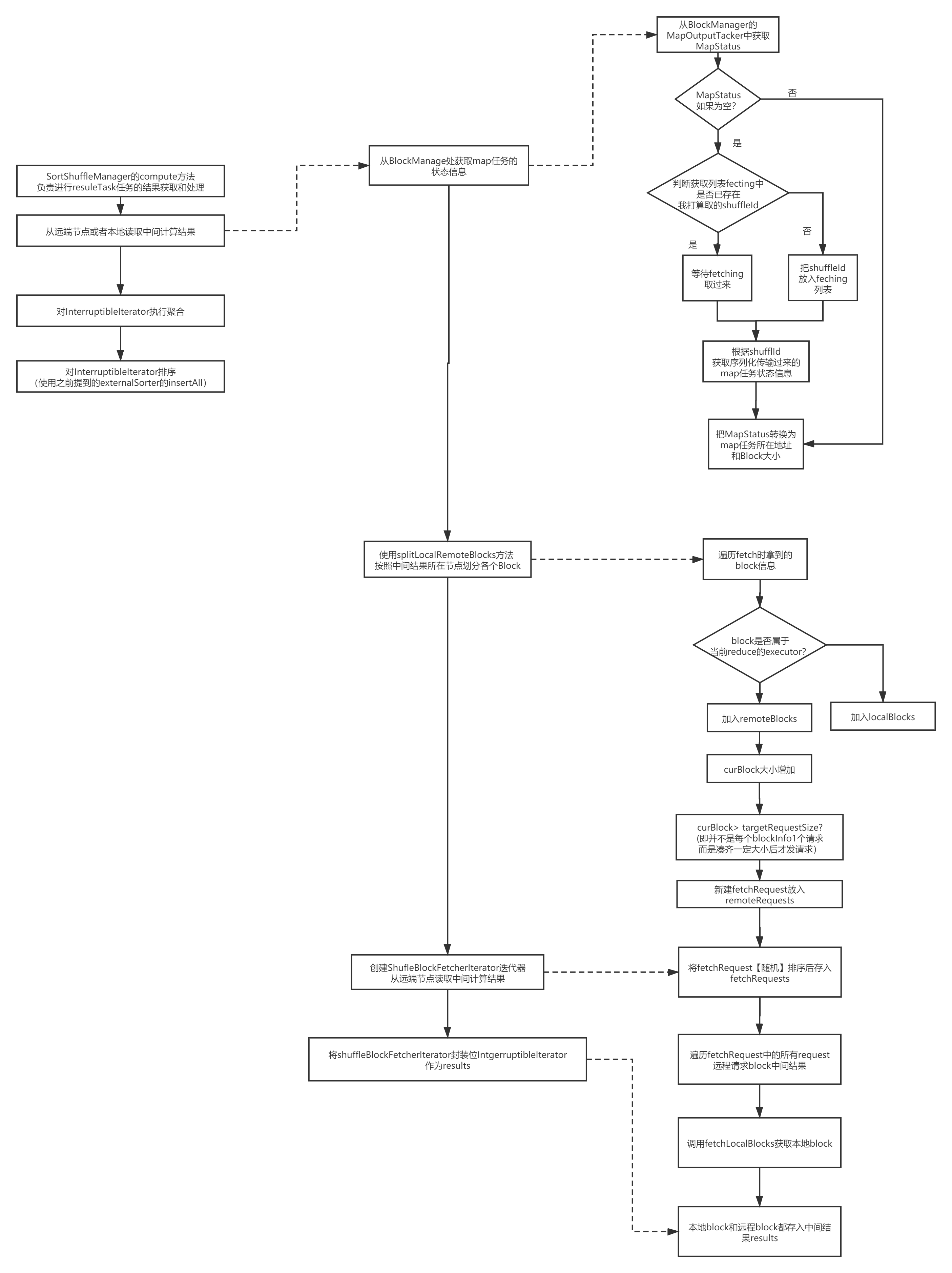
完整流程如下: