[toc]
当spark中做完一次map操作,准备发给下游时,究竟会做什么事呢?我按照一些问题来逐步分析。
首先有个问题:map操作之后,数据是直接缓存到内存或者磁盘,等待下游client来拉取吗?
spark是批处理,假设正好map处理完一批数据,会调用insertAll方法去做缓存,然而缓存并不是那么简单的存储,而是如下:
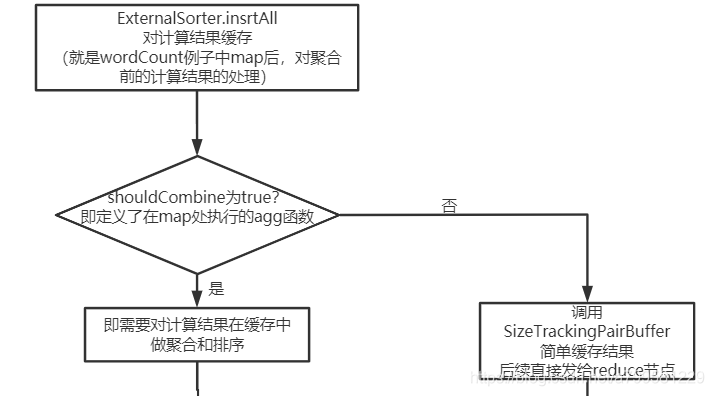
可以看到,spark会判断这个map操作之后,是否会接一个聚合的操作,如果有,那么会在缓存并准备发给下游时时,提前做好聚合操作, 否则就是简单缓存。
我们先看下简单缓存的分支:
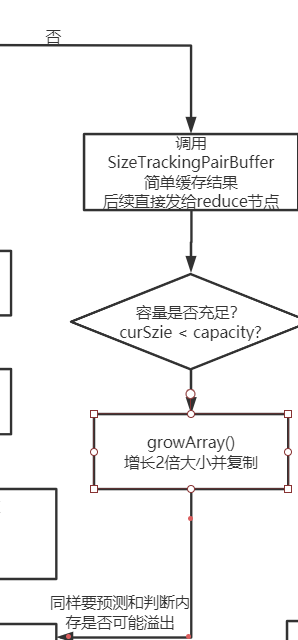
可以看到在这里地方会做容量判断,如果发现容量不足了,则会试图扩容,看下调用growArray会发生什么:
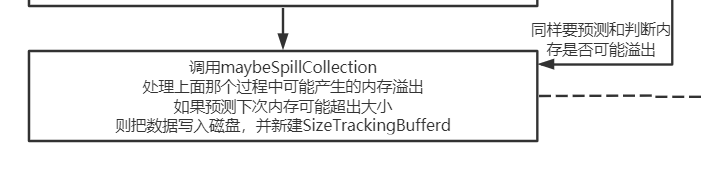
注意这里有个关键词是预测, spark为了防止出现omm,都是基于预测机制进行内存管理的。看下maybeSpillCollection具体在做什么
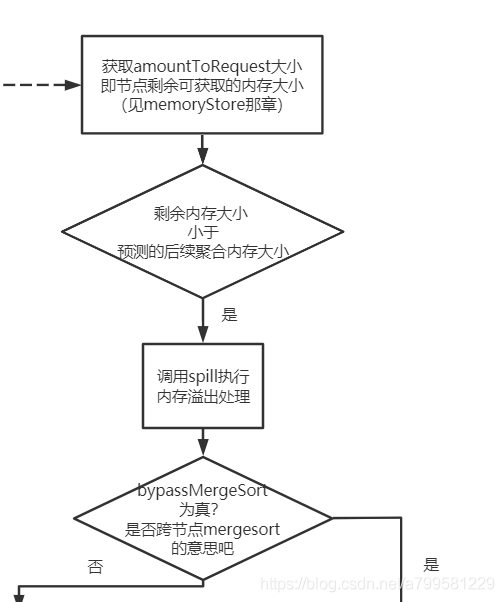
当发现内存大小可能不足,就会试图把内存数据放到磁盘。
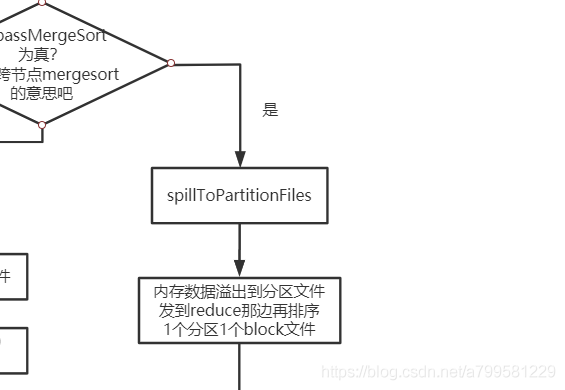
然而放到磁盘也不是那么简单地去放,他判断了一个叫byPassMergeSort,这个是什么呢?
可以理解为是否需要提前为下游做好分区的磁盘排序。
每次存盘都会排序吗?
不是的,为了避免不必要的排序,他用bypassMergeThold这个阈值来确认,如果分区数量大于阈值,此时不做合并的话,可能导致频繁的磁盘IO取数据! 所以他做了如下操作:
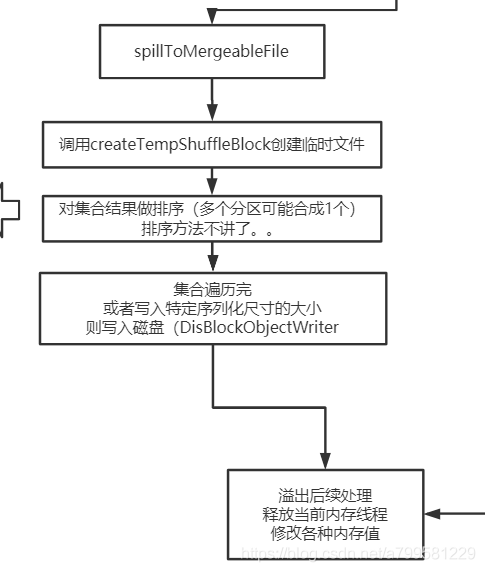
临时文件做排序的图解如下:
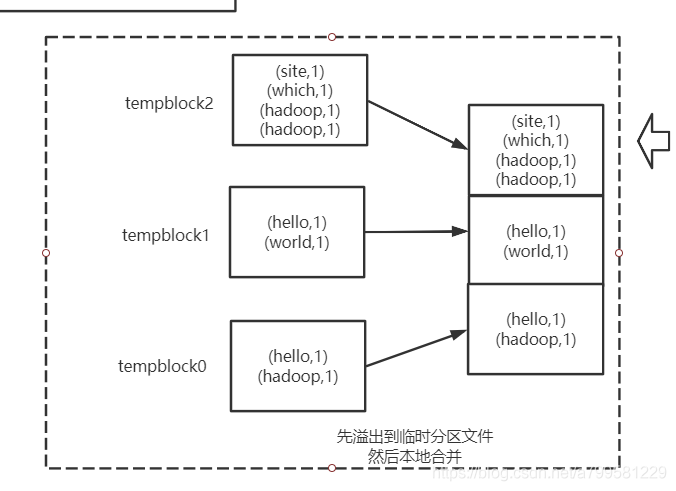
如果上图不好理解,可以看下面这个图,更详细地解释了如果用做临时文件加合并的:
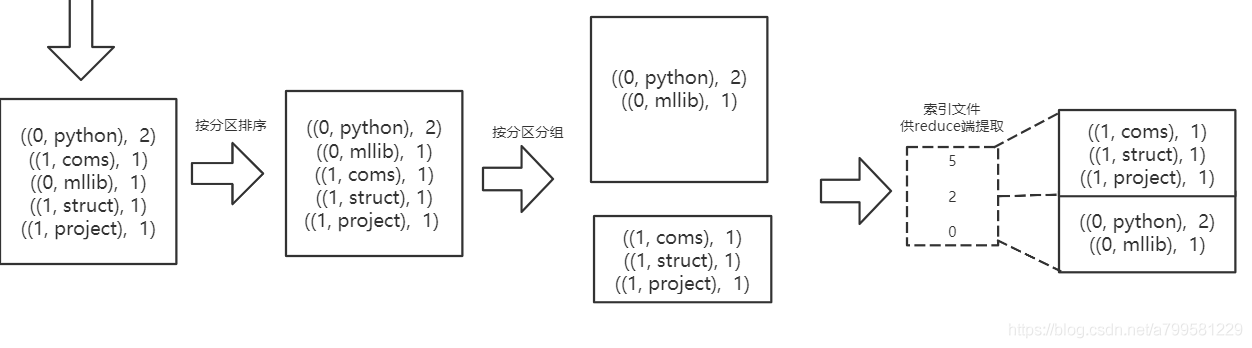
如果分区文件比较少,就不做排序+合并了,直接落盘让下游过来取
接着看需要在map后做聚合的情况:
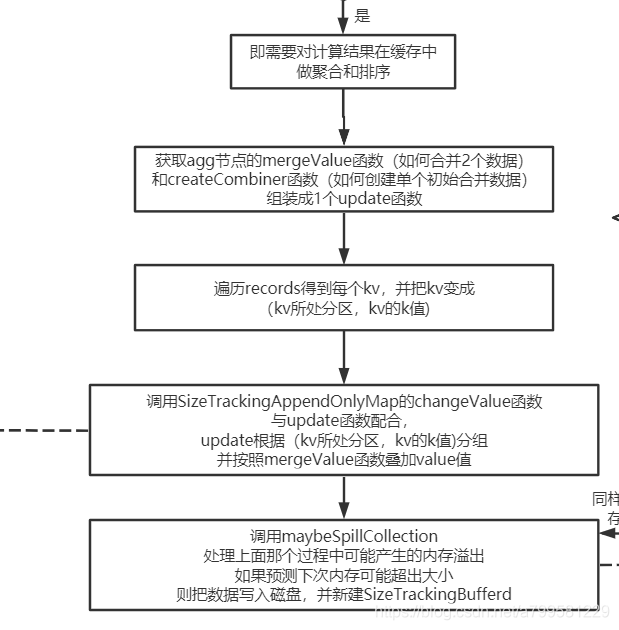
可以看到所谓的聚合,必定会经历分组+ 聚合2个操作。看下是如何做mergeValue的:
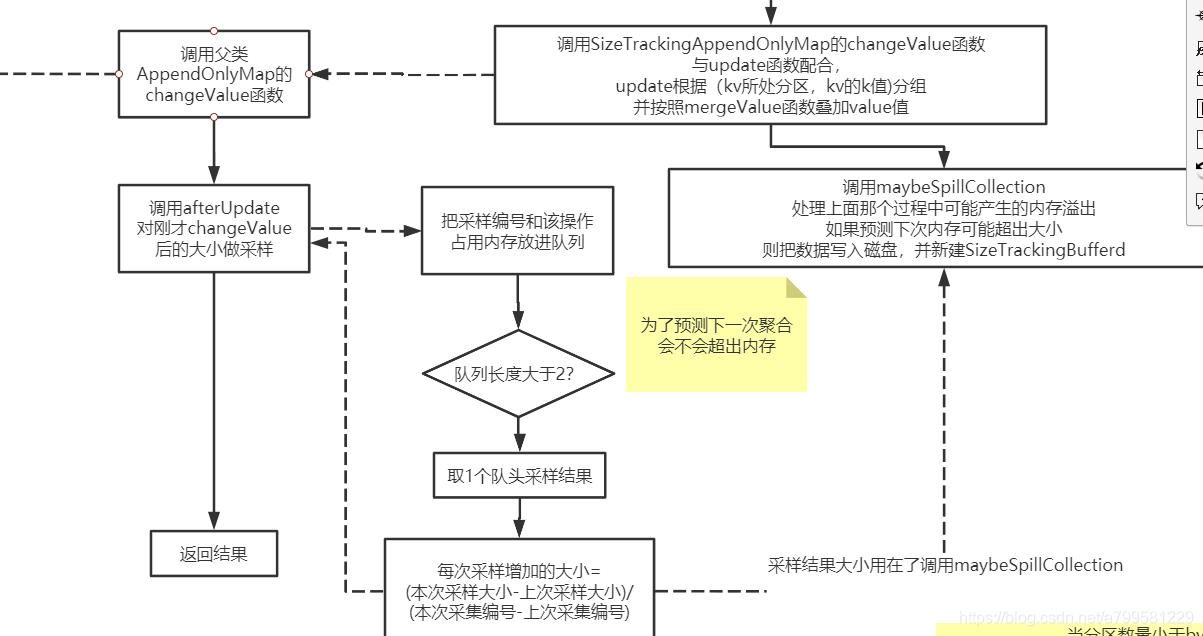
Q:这里为什么要做采样来判断内存是否会超呢?
A:因为当前聚合操作都是在内存中进行的,而map的数据是一块块计算出来的,如果这个聚合的key取的有问题,导致分组聚合后的数据总大小几乎没变化,就可能导致内存里分组后的那堆数据越积越大。
Q:为什么要用采样队列来预测聚合过程的大小?
A:书里没讲原因,个人理解,如果map的块数比较多,这种采样预测的方式是比较简单且消耗计算少的, 根据这个采样大小,后面会用于做内存预估。
接着继续看下怎么做mergeValue的细节:
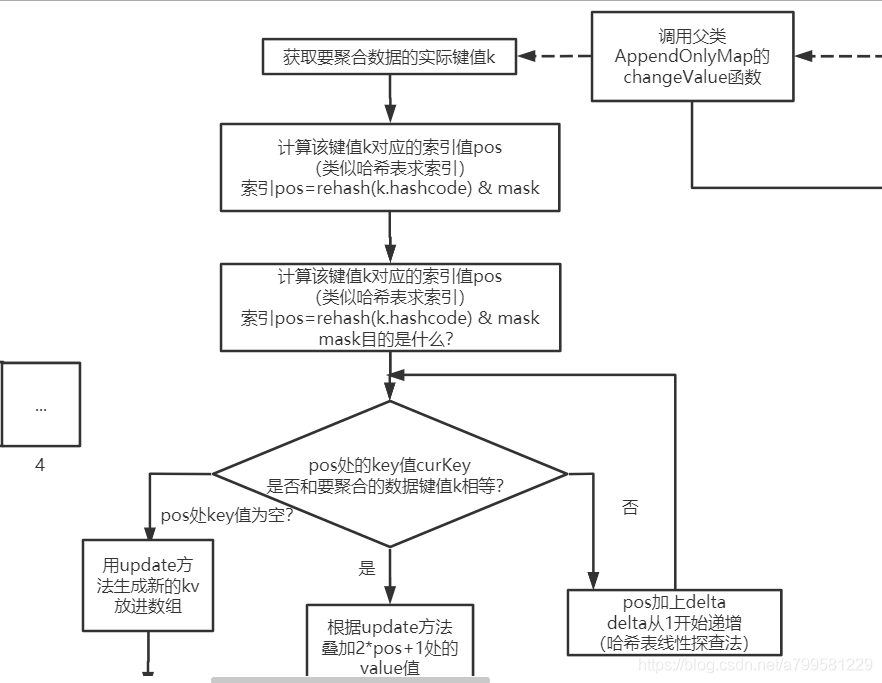
其实就是非常常见的一个哈希表计算的过程。
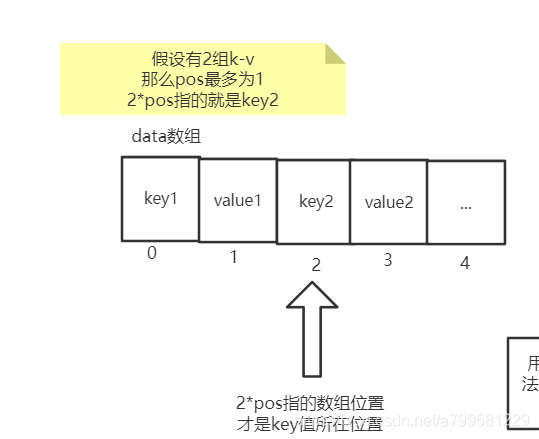
为什么中间那个分支里, 要叠加2pos+1的value值呢?
这是因为为了节省空间,把key和value两两放在一起,如图所示:
另外每次新增key的时候,会需要扩容,看下扩容怎么实现的:
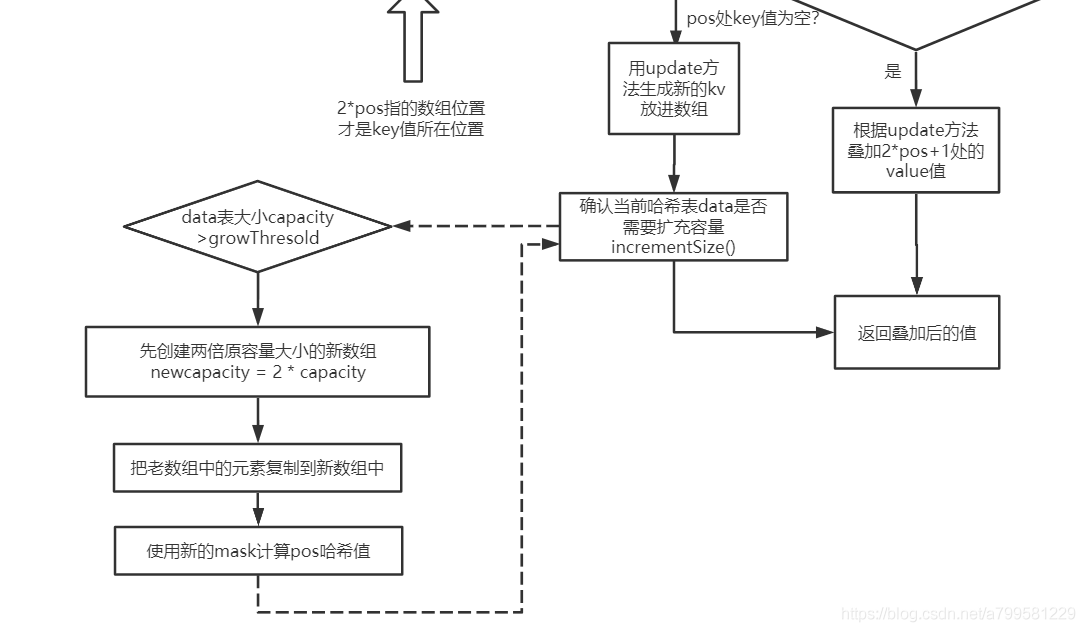
可以看到非常简单的一种 每次2后,复制扩容的过程。
spark做map过程时的计算缓存结果完整图解如下:
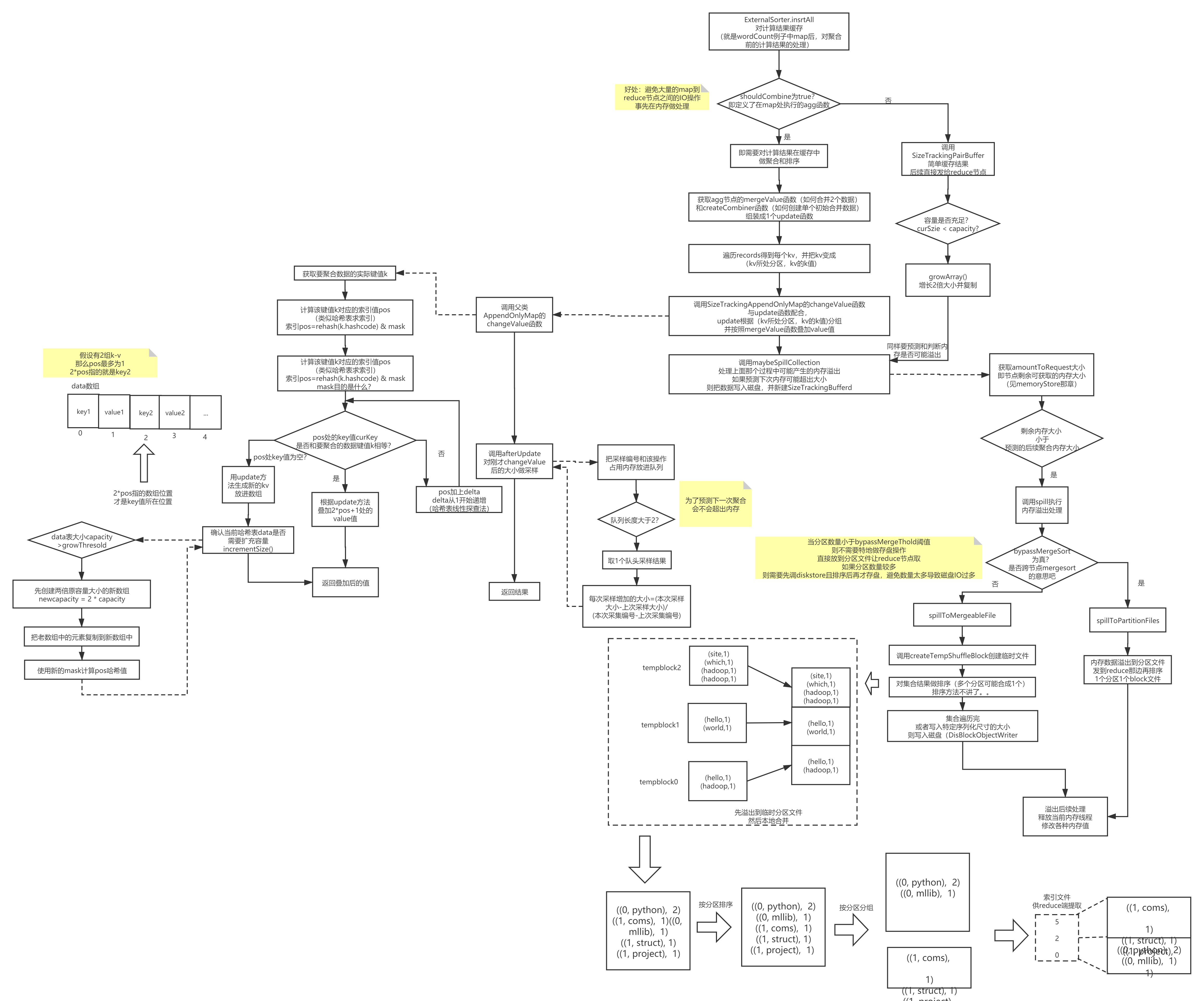
小结一下map后做缓存处理的要点:
- 如果map后发给下游时是需要做聚合的操作,则提前做一下聚合处理。
聚合处理时有以下特点:
①每次聚合计算后,都会采样内存变化大小,方便预测内存情况
②使用哈希表做聚合计算
③哈希表支持扩容,容量每次为*2 - 如果map后不需要做聚合,则会缓存结果(注意聚合后同样也是会缓存,只是结果变成聚合后的了), 但如果发现预测的内存不够了,则会把数据存盘, 存盘时的注意点如下:
①分区数比较少,则直接落盘
②分区数较多,1个分区1个文件的话太多了,磁盘IO消耗大,因此会把分区排序并合并