[toc]
书中以经典的wordCount为例子
wordCount就是计算文本中a-z字母的个数,利用分布式计算的能力
mapreduce做wordCount#
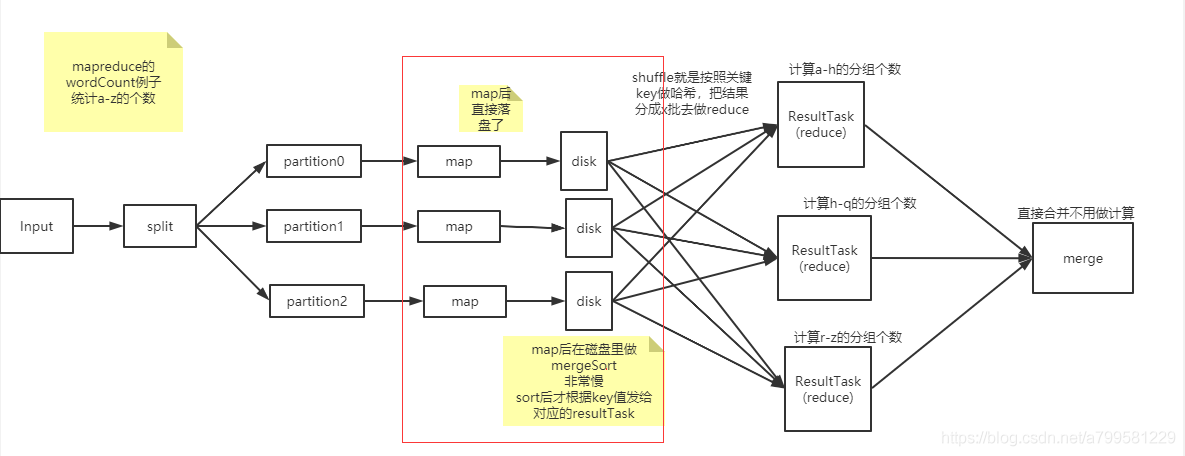
标红的地方就是关键点, mapreducer做map后直接落盘了, 落盘后进行排序,排序完取出相同键的组发送,到resultTask做聚合计算。
其实不太懂mapreduce早期为什么这么做,是因为那时候还不知道怎么在内存和磁盘间切换吗?
早期spark的wordCount计算#
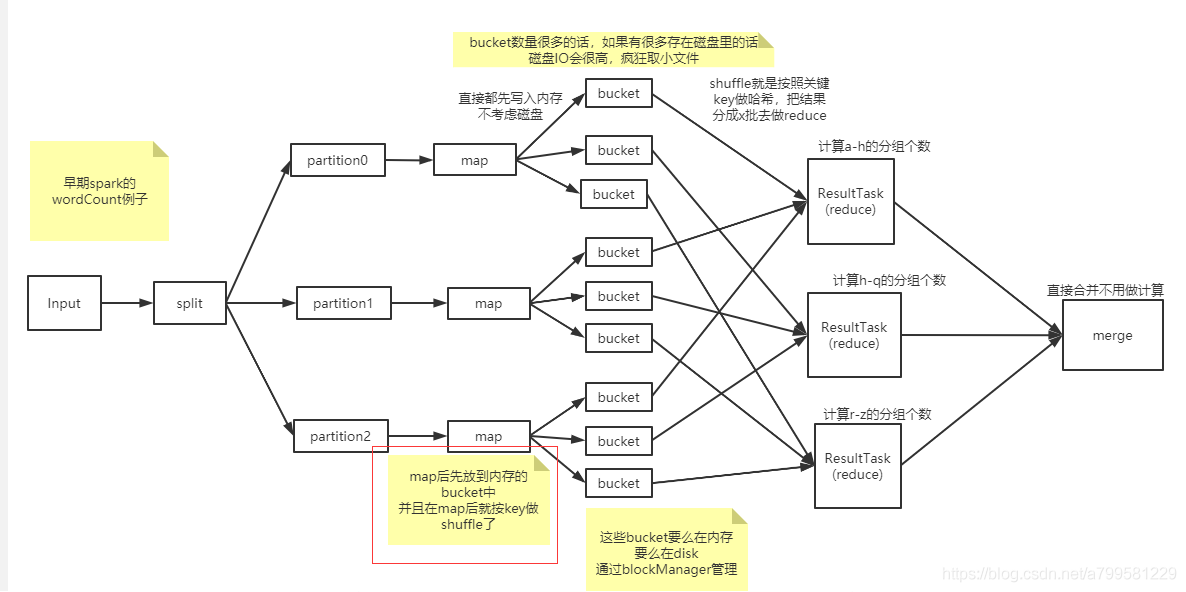
标红的地方是一个关键点。
map后优先根据key存到内存中, 并拆成1个个bucket, bucket就是之前提过的blockManager来管理。
要点#
- 做聚合计算(例如分组计数)前,需要先根据键值哈希,再进行shuffle。
- 先放内存进行分组哈希,如果实在放不下再放磁盘,需要引入BlockManager