[toc]
RDD缓存管理cacheManager#
当需要计算RDD时,需要避免重复计算的RDD。
- 什么时候RDD可能会被重复计算?一般是宽依赖RDD, 即RDD的下游可能有多个, 但是另一个下游的拉去可能较慢, 那么此时需要做缓存。
cacheManager只是对RDD的管理, 真正的缓存以及获取是通过blockManager,然后根据内存情况选择存内存还是存磁盘。
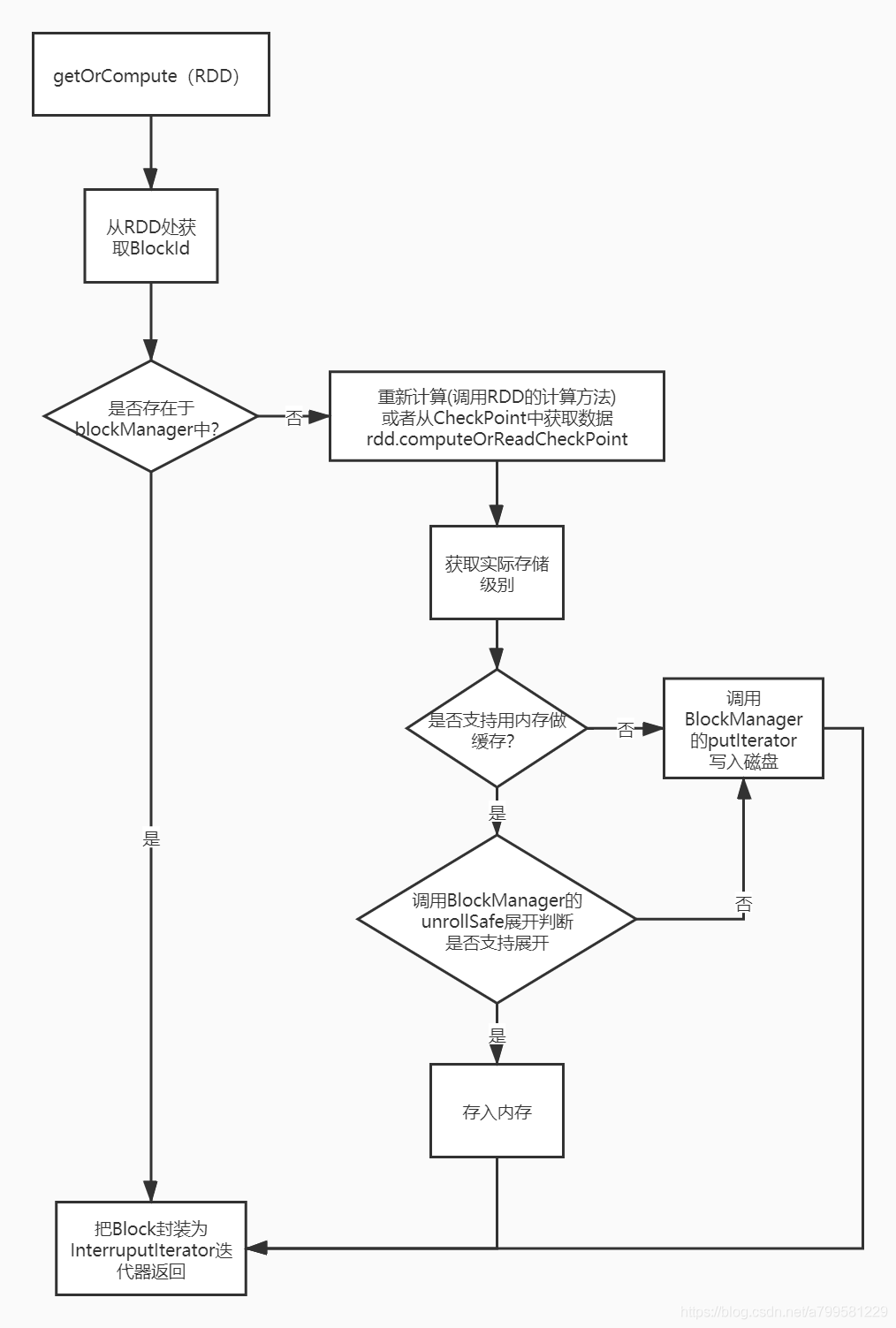
- RDD不是一定会做缓存,这取决于存储级别的设定。
- RDD没缓存时, 不一定要重新计算, 也可能从CheckPoint中拿
- checkPoint概念:
checkpoint在spark中主要有两块应用:一块是在spark core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;另外一块是应用在spark streaming中,使用checkpoint用来保存DStreamGraph以及相关配置信息,以便在Driver崩溃重启的时候能够接着之前进度继续进行处理(如之前waiting batch的job会在重启后继续处理)。
如果需要存入内存,直接使用memoryStore即可,memoryStore的存储过程见上一篇博文。
如果要写入磁盘,需要调用diskStore提供的put方法把RDD对应的block块写入磁盘
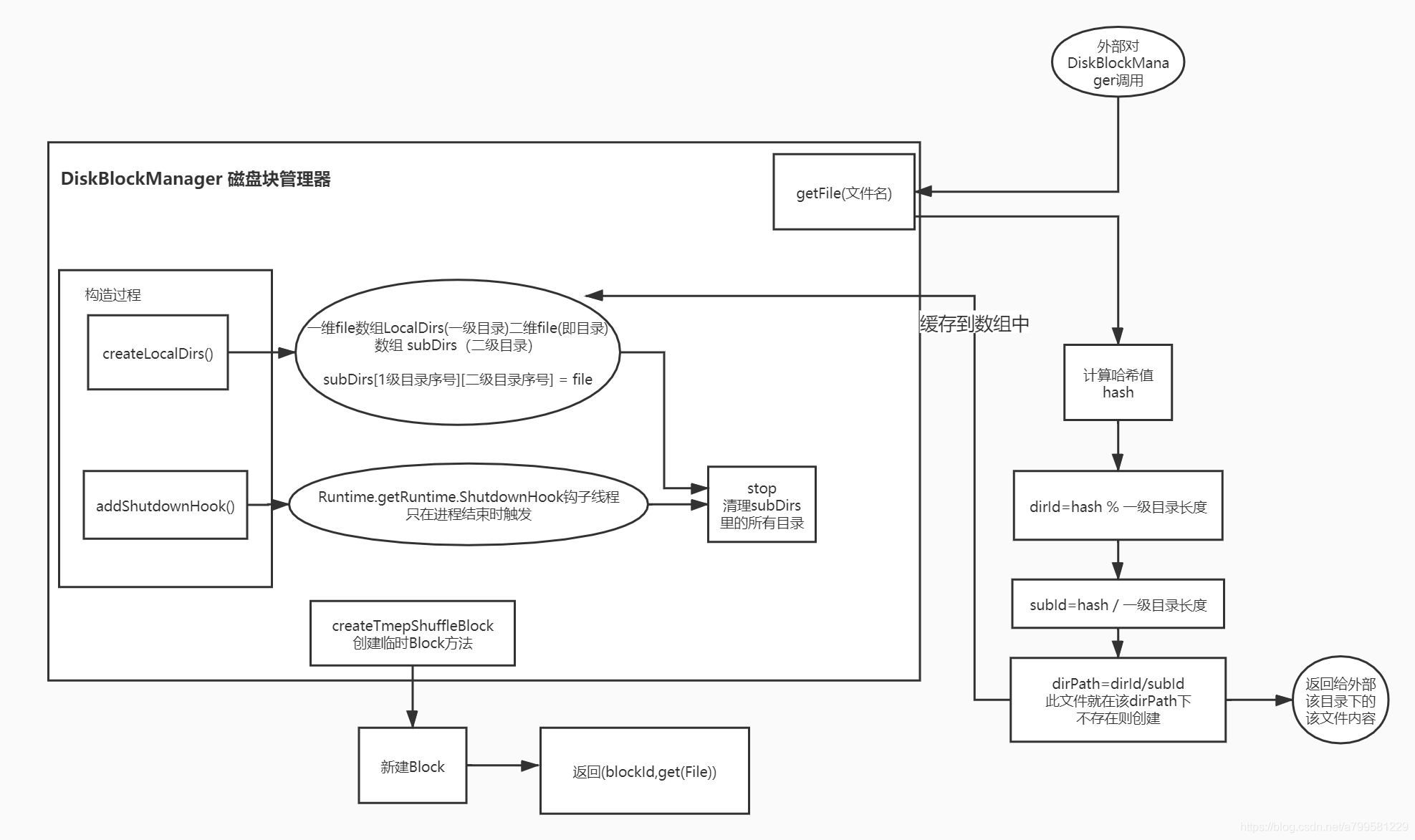
diskStore和diskBlockManager有什么关系?#
diskStore里要写入数据时,负责打开某个文件, 然后往文件里写入。
取出数据时,也是找到对应的文件,然后取出数据。
而这个磁盘文件的管理并没有放到diskStore里实现,而是独立了一个diskBlockManager模块。
以DiskStore的putArray方法为例,从下图可看出关系:
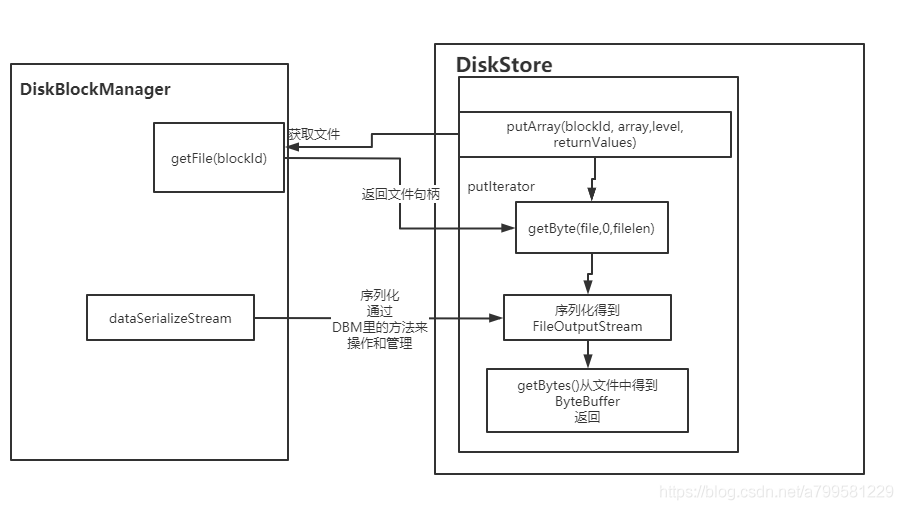
即文件相关、序列化相关,都让diskBlockManager来搞了。
diskBlockManager的getFile过程#
上图里有个getFile的操作,即从DBM中拿到文件对象做写入。
那么这个文件创建时,怎么选路径,怎么命名?
首先,文件的路径和文件名, 使用2次哈希得到
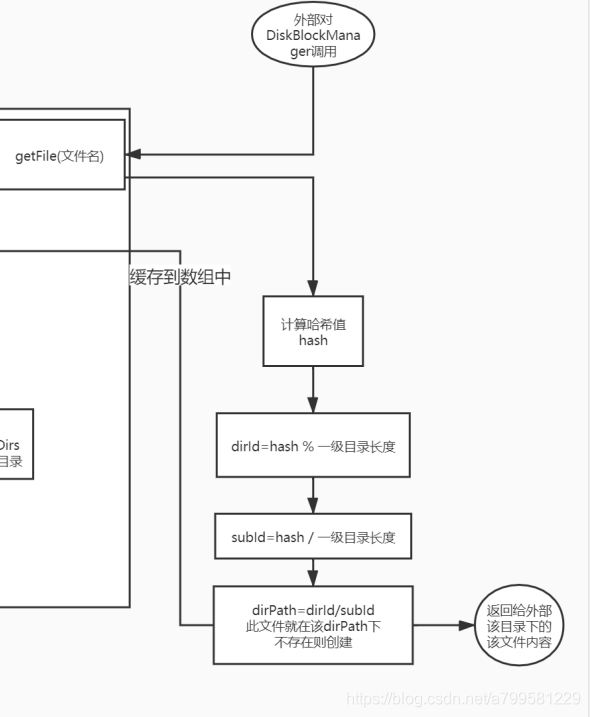
使用2级哈希做路径的目的,是因为一级目录有多个,需要用哈希选择放到哪个一级目录。
每次创建文件的话,会把该文件放到DBM里的一个数组中,并加上钩子做管理,如果程序中止或者结束,需要主动清理临时文件。
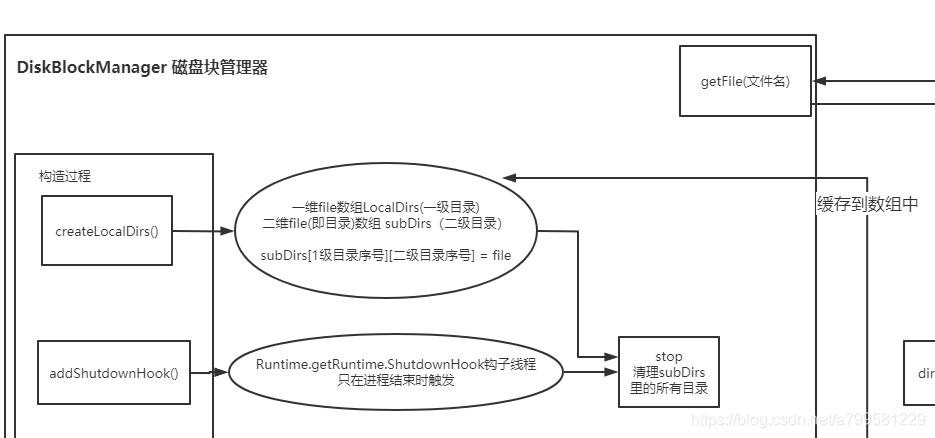
DiskBlockManager全图: