[toc]
String字符串#
string 不是简单的字符串的意思
而是key -> value(string)
即value是一个string ,可以用一个key去对应到,key也可以理解成变量名。
-
这个string可以当成数字使用。
set count 1
incr count // count+1
incrby count 100 // count+100
但是当你get count的时候,得到的是string的count

-
也可以是,jpg图片或者序列化的对象。
因此string本质上是二进制安全的,不会因为编码不同发生变化
Q: redis-string的key可以是中文吗?#
A:
key可以是中文,不过redis在存储的时候会将key进行序列化,在redis中存储的是字节码。
不推荐使用中文Key,内耗更大并且出现乱码的可能性也是有的。编码字节存储等都是不一样的占用空间。
Q: 那么redis string的value可以存中文吗?什么样子的?要不要指定编码?#
A:
- 在保存到redis中时以utf8的编码方式保存的,实际上时等价于正常的这种十六进制字符串
- 默认看到的是乱码\xe4\xb8\xaa\xe4\xba\xba\xe8\xb5\x9b
- 启动cli时多加一个参数就行了,redis-cli --raw这种方式,就可以查看中文了
Q: redis-string的用途随便说几个#
A:
- 缓存。把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力
- 计数器,单节点redis的计数是同步的,不用担心并发问题。调用incr等方法即可
- session缓存
Q: string的底层实现有了解吗?和C语言的字符串有什么区别?#
A:
redis的字符串类型是由一种叫做简单动态字符串(SDS)的数据类型来实现
其实就是多了当前长度和剩余容量
1 | struct sdshdr { |
SDC和C语言字符串的区别:
- SDS保存了字符串的长度,而C语言不保存,C语言只能遍历找到第一个\0的结束符才能确定字符串的长度
- 修改SDS,会检查空间是否足够,不足会先扩展空间,防止缓冲区溢出,C字符串不会检查
- SDS的预分配空间机制,可以减少为字符串重新分配空间的次数
备注:重新分配空间方式,小于1M的数据 翻倍+1,例如:13K+13K+1,如果大于1M,每次多分配1M,例如:10M+1M+1,如果字符串变短,并不会立即缩短,而是采用惰性空间释放,有专门的API可以释放多余空间
List列表#
- list的本质就是一个双端链表!
- 用于消息排队、最新消息更新、 消息消费队列
Q: 用redis的list可以实现哪些数据结构?怎么实现?#
A:
- 栈:lpush + lpop (只在一个方向上做push和pop)
- 队列:lpush + rpop(一个方向入, 一个方向出)
- 有限集合:lpush + ltrim(trim是截断,这样可以限制长度)
- 阻塞的消费者消息队列:lpush+brpop(b就是block的意思,没有就阻塞)
Q: 消费者消息队列能设置超时吗?#
A:
可以的
BLPOP key1 [key2 ] timeout
Q: list里的存储结构是什么?#
A:
链表。 链表里存的是string。
Set集合#
- set本质上就是实现了一个哈希表, 以至于不能在这个set成员中放入相同的key
- 除了简单的sadd、smember外,还有很多求交集的关键方法。
**
Q: 为什么标签可以用set来做?而不用list#
A:
因为set允许任意的增删, 而list只能对前后操作。 标签可能会被随时增加删除。
因此被某某某点赞/取消的系统也可以用redis的set做缓存
Hash散列#
- 和set的区别, 就是key-value, 而set里只有key
- 命令都是hset、hget、hxxx等
Q: hash存储有什么限制?#
A:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数量小于512个
Q: redis如何解决哈希冲突的?#
A:
链表法(挂链法),后入的放到最前面
Q: 散列表容量不足怎么办?#
A:
容量不足时的rehash:
键值数据量变动时,为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
- 如果是扩充,新数组的空间大小为 大于2*used的2的n次方,比如:used=5,则去大于10的第一个2的n次方,为16
- 如果是缩小,新数组的空间大小为第一个不大于used的2的n次方,比如:used=5,则新大小为4
即永远2的n次方
Q:
Zset有序集合#
-
zset不是java中的treeMap。
treeMap是根据key进行排序
而zset是根据scope排序, ke是唯一的, key对应的scope不是唯一的。 -
关键命令: 可以用ZRANGE拿到前几个。
Q: zset的原理是什么?#
A:
底层分别使用ziplist(压缩链表)和skiplist(跳表)实现。
当zset满足以下两个条件的时候,使用ziplist:
- 保存的元素少于128个
- 保存的所有元素大小都小于64字节
不满足这两个条件则使用skiplist。
(注意:这两个数值是可以通过redis.conf的zset-max-ziplist-entries 和 zset-max-ziplist-value选项 进行修改。)处。
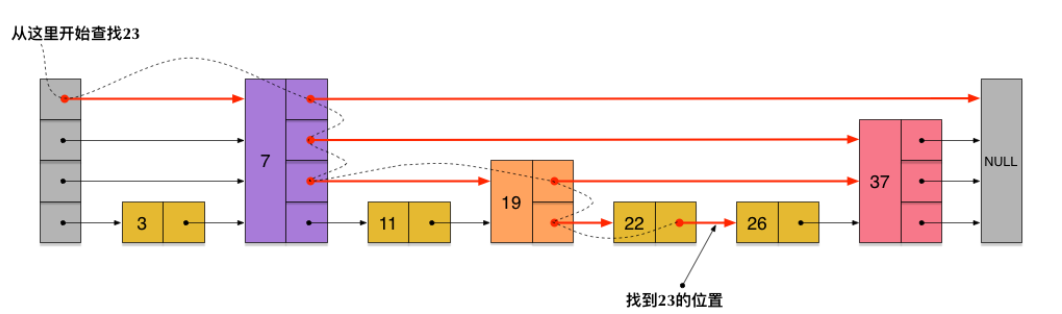
- 跳表:
skiplist实现原理
- 插入时,随机一个层数,然后找到那一层的对应位置插入,并更新前后节点
- get时,先从最高层找,比要找的大时,再去下一层。
- 随机时不是完全随机,会根据当前分布情况,修改概率p,并设置某一层的最大限制,防止比别的层过多。
Q: redis 3.0里zset有什么改变?#
A:
zset的底层实现变成了quicklist。
- quicklist宏观上是一个双向链表,因此,它具有一个双向链表的有点,进行插入或删除操作时非常方便,虽然复杂度为O(n),但是不需要内存的复制,提高了效率,而且访问两端元素复杂度为O(1)。
- quicklist微观上是一片片entry节点,每一片entry节点内存连续且顺序存储,可以通过二分查找以 log2(n)log2(n) 的复杂度进行定位。
快速列表(quicklist)源码解读
HyperLogLogs基数统计#
Q: 基数用来解决什么问题?#
A:
解决海量计数问题, 例如每天访问的ip数量, 如果真的存每个ip,会很大。
而基数利用位运算来统计, 限制死了每个键的内存大小, 虽然有一定误差(即位冲突的情况),但是在海量的情况下不影响粗略统计。
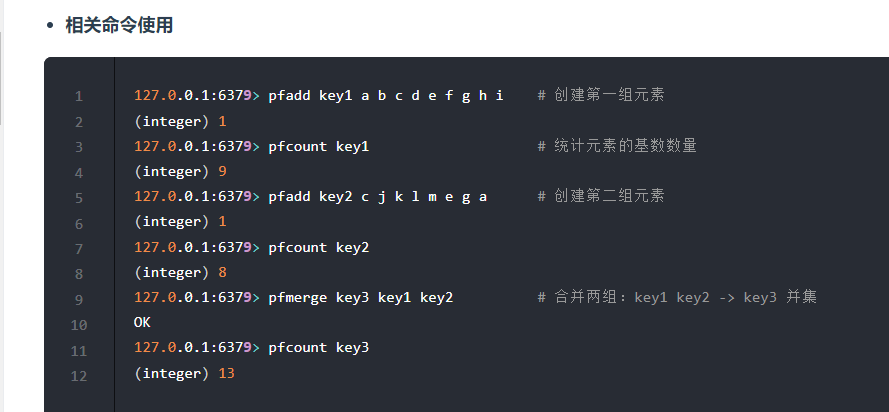
基数每个键占用的内容都是 12K,理论存储近似接近 2^64 个值, 因为位冲突问题可能会偏少。
BitMap 位存储#
用于统计 ”是“或者”否“的 这种一堆人的状态
比如是否在线的缓存, 可以用bitmap。
如果存储一年的打卡状态需要多少内存呢?
365 天 = 365 bit 1字节 = 8bit 46 个字节左右,非常节省内存
geospatial 地理信息#
求解一些经纬度信息的。略
stream#
是一种更可靠的消息队列实现,redis5.0后实现的。
具体见后面的stream详解