- Q: redis的主从复制主要是解决什么问题的?
- Q: 全量复制的全过程?
- Q: 全量复制后,就不再复制了,对嘛?
- Q: 那redis的增量复制又是解决什么问题的?
- Q: 主节点怎么实现的增量复制?
- Q: 主节点不做持久化的话,会有什么问题?
- Q: 为什么全量复制时,要用RDB而不是AOF?
- Q: 如果我的redis磁盘性能比较差,做主从全量复制时,每次从磁盘加载RDB的开销很大怎么办?
- Q: 从库太多了, 主库复制的压力很大怎么办?
- Q: redis主库和从库继续读操作时,数据可能会不一致, 但我的服务对一致性要求很高,不允许被人同时看到2个不一样的数据,怎么办?
- Q: 全量复制时,从节点读取到了过期的数据怎么办?
[toc]
Q: redis的主从复制主要是解决什么问题的?#
A:
-
故障恢复(主节点挂了, 启动从节点作为主节点)
-
负载均衡(读写分离, 主库写+读, 从库读)
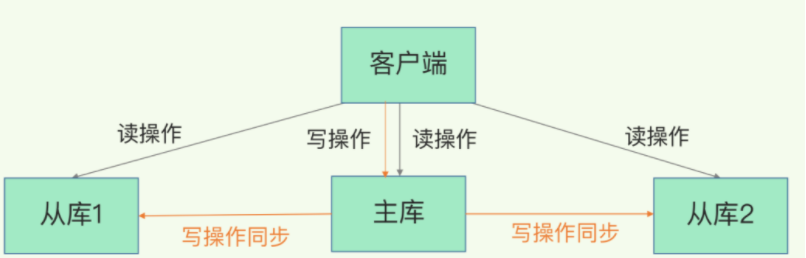
-
高可用(哨兵和集群都依赖主从复制)
redis的主从复制 包含全量复制和增量复制
Q: 全量复制的全过程?#
A:
- 阶段1:连接建立
-
从库调用"replicaof/slaveof ip port"命令,将对应节点设置为自己的主节点。(即调用这个命令的是从库)
-
从库给主库发送 psync 请求
psync请求中包含runId(redis唯一id)和复制进度offset
当第一次复制,offset设置为-1.
-
主库收到 psync 命令后,如果是第一次复制,则会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset。
fullResync告知对方我会给你全量的数据。
- 阶段2:数据复制
- 主库调用bgsave命令,生成RDB文件, 然后把RDB文件发给从库。
- 从库收到RDB文件后,会先清空自己库内的所有数据,然后再根据RDB进行加载。
- 阶段3:持续同步
-
第4步主库生成完RDB文件后, 会生成一个 replication buffer,专门记录这之后收到的所有写命令。
-
当RDB文件发送完成后, 主库会把replication buffer中的写命令转发给备redis。

Q: 全量复制后,就不再复制了,对嘛?#
A: 错, 阶段3会持续同步, 一直存在的一个过程。
注意, 这个阶段3的过程不叫“增量复制”!
Q: 那redis的增量复制又是解决什么问题的?#
A:
专门用于解决刚才阶段3中的持续同步时,发生网络短时间断开,以至于主从不一致的问题。
当网络重新建立后, 从节点不希望全量复制,因此会借助增量复制机制,让主节点把特定offset后的写数据发给自己。(之前的psync中的offset就是用在这里的)
Q: 主节点怎么实现的增量复制?#
A:
主节点自身有一个repl_backlog_buffer, 写命令都会缓存到这里,每个命令都有个offset。
这个buffer是一个环形链表,因此有长度限制,过于老的写命令会被清理掉。
当从节点重新用psync连上,并告知自己的offset时, 主节点会检查一下,看看offset在repl_backlog_buffer中是否存在
- 如果存在,说明来得及,于是从offset处发送写命令给从节点。
- 如果offset不存在,说明时间太久了,offset到现在的数据之间已经有很多丢失了,需要重新全量复制了
Q: 主节点不做持久化的话,会有什么问题?#
A:
当主节点重启时,从节点正好继续增量复制,然后都继续了空的全量复制,并清空了原先的数据。
Q: 为什么全量复制时,要用RDB而不是AOF?#
A:
1、RDB文件内容是经过压缩的二进制数据(不同数据类型数据做了针对性优化),文件很小。而AOF文件记录的是每一次写操作的命令,写操作越多文件会变得很大。
\2. RDB文件直接加载key, 而AOF需要处理写命令。
\3. RDB只有在需要定时备份和主从全量复制数据时才会触发生成一次快照。而在很多丢失数据不敏感的业务场景,其实是不需要开启AOF的。
Q: 如果我的redis磁盘性能比较差,做主从全量复制时,每次从磁盘加载RDB的开销很大怎么办?#
A:
使用repl-diskless-sync配置开启无磁盘复制
master创建一个新进程直接dump RDB到slave的socket,不经过主进程,不经过硬盘。适用于disk较慢,并且网络较快的时候。
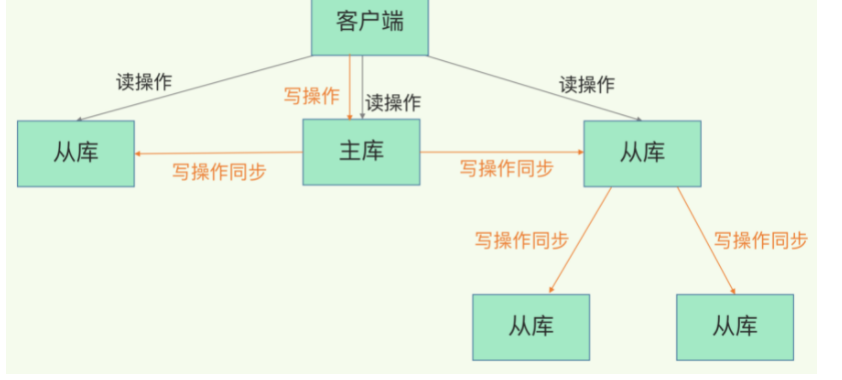
Q: 从库太多了, 主库复制的压力很大怎么办?#
A: 改成主——从——从的模式。
即从库2把从库1认做主库, 从库3把从库2认作主库。
Q: redis主库和从库继续读操作时,数据可能会不一致, 但我的服务对一致性要求很高,不允许被人同时看到2个不一样的数据,怎么办?#
A:
(1)业务可以接受,系统不优化
(2)强制读主,高可用主库,用缓存提高读性能
(3)在cache里记录哪些记录发生过写请求,来路由读主还是读从
- 优化主从节点之间的网络环境, 将延时控制在不可感知的时间范围内
- 监控主从的当前offset或者网络延时,如果发现误差过大,则停止从从节点读,使用延时更低的集群扩展进行读写负载扩容。
- 从节点数据正在做同步时,不允许响应客户端命令,避免不一致。
Q: 全量复制时,从节点读取到了过期的数据怎么办?#
A:
Redis 3.2中,从节点在读取数据时,增加了对数据是否过期的判断:如果该数据已过期,则不返回给客户端;将Redis升级到3.2可以解决数据过期问题。