[toc]
https://cloud.tencent.com/developer/article/1656529
在 Presto 中,我们需要了解一些非常重要的数据结构,例如,Slice,Block 以及 Page,下面将介绍这些数据结构。
数据模型#
presto采取三层表结构:
- catalog 对应某一类数据源,例如hive的数据,或mysql的数据
- schema 对应mysql中的数据库
- table 对应mysql中的表
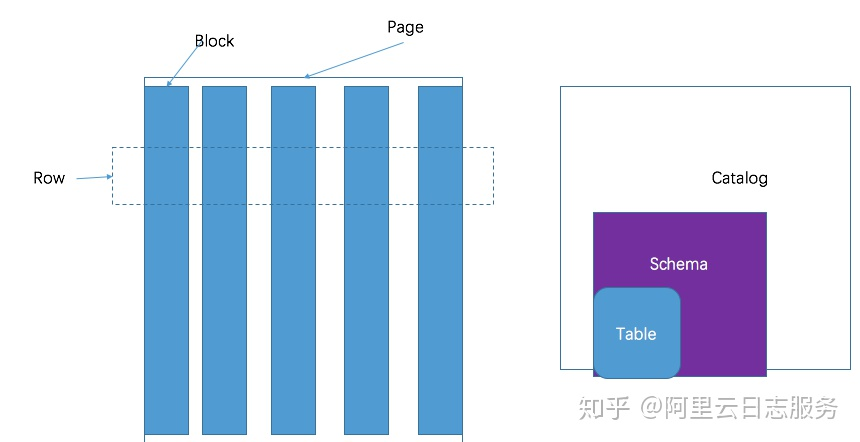
presto的存储单元:#
- Page: 多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
不同类型的block:#
-
array类型block,应用于固定宽度的类型,例如int,long,double。block由两部分组成
boolean valueIsNull[]表示每一行是否有值。
T values[] 每一行的具体值。
-
可变宽度的block,应用于string类数据,由三部分信息组成
- Slice : 所有行的数据拼接起来的字符串。
- int offsets[] :每一行数据的起始便宜位置。每一行的长度等于下一行的起始便宜减去当前行的起始便宜。
- boolean valueIsNull[] 表示某一行是否有值。如果有某一行无值,那么这一行的便宜量等于上一行的偏移量。
- 固定宽度的string类型的block,所有行的数据拼接成一长串Slice,每一行的长度固定。
- 字典block:对于某些列,distinct值较少,适合使用字典保存。主要有两部分组成:
- 字典,可以是任意一种类型的block(甚至可以嵌套一个字典block),block中的每一行按照顺序排序编号。
- int ids[] 表示每一行数据对应的value在字典中的编号。在查找时,首先找到某一行的id,然后到字典中获取真实的值。
Slice#
从用户的角度来看,Slice 是一个对开发人员更友好的虚拟内存,它定义了一组 getter 和 setter 方法,因此我们可以像使用结构化数据一样使用内
Slice 常用来表示一个字符串:
// use it as utf8 encoded string
Slice slice = Slices.utf8Slice(“hello”);
Slice subSlice = SliceUtf8.substring(slice, 1, 2);
我们可以像使用字符串一样使用 Slice,Presto 为什么选择 Slice 而不是 String:
字符串创建代价昂贵(字符串拼接,StringBuilder等)。
Slice 是可变的,而 String 是不可变的,因此当我们需要进行字符串计算时,效率更高。
字符串在内存中编码为 UTF16,而 Slice 使用 UTF8,这样可以提高内存效率。UTF16 最少使用两个字节来表示一个字符,而 UTF8 最少使用一个字节,因此,如果 String 内容主要是 ASCII 字符,则 UTF8 可以节省大量内存。
Slice(在 Presto 中)的另一种用法是表示原始字节(SQL中的 VARBINARY 类型):
// use it as raw bytes
block.getSlice().getBytes()
Block#
由于 Page 由 Block 组成,因此我们首先介绍 Block。Block 可以认为是同一类数据(int,long,Slice等)的数组。每个数据项都有一个 position,总位置个数代表 Block 中数据的总行数(Block 仅保存这些行中的一列)
Block 定义了好几套 API,其中一个是 getXXX 方法,让我们以 getInt 为例:
/**
* Gets a little endian int at {@code offset} in the value at {@code position}.
*/
default int getInt(int position, int offset) {
throw new UnsupportedOperationException(getClass().getName());
}
通常,一个 Block 仅支持一种 getXxx 方法,因为一个 Block 中的数据都来自同一列,并且具有相同的类型。
Block 定义的另一个方法是 copyPositions,来代替从 Block 中获取某个值,通过返回一个新的 Block 来从指定的位置列表获取一组值:
1 | /** |
- Presto 还定义了 BlockEncoding,定义了如何对 Block 进行序列化和反序列化:
1 | public interface BlockEncoding { |
1 | /** |
}
我们以最简单的 BlockEncoding:IntArrayBlockEncoding 为例,其 readBlock 如下所示:
1 | int positionCount = block.getPositionCount(); |
Page#
Page 由不同的 Block 组成:
1 | public class Page { |
除 Block 外,Page 还有另一个称为 Channel 的概念:每个 Block 都是该 Page 的 Channel,Block 的总数就是 Channel 数。因此,让我们在这里总结一下数据是如何结构化的,当要发送一些行时,Presto 将:
将每一列放入单独的 Block 中。
将这些 Block 放入一个 Page 中。
发送 Page。
Page 是保存数据并在 Presto 物理执行算子之间传输的数据结构:上游算子通过 getOutput() 产生输出:
1 | /** |
- 就像 Block 一样,Page 也需要序列化和反序列化,序列化发生在工作进程之间传输数据时。Page 进行序列化时,首先使用相应的 BlockEncoding 对 Block 进行编码。如果有压缩器,将尝试对编码的块数据进行压缩,如果压缩效果良好(编码率低于0.8),将使用压缩数据,否则使用未压缩的数据。编码后的块数据将与一些统计信息(压缩前后页面的字节大小)一起放入名为 SerializedPage 的类中。