[toc]
参考资料:
https://www.gameres.com/883796.html
https://zhuanlan.zhihu.com/p/101366898
https://blog.csdn.net/anghiking20140716/article/details/101312055
presto高可用原理图#
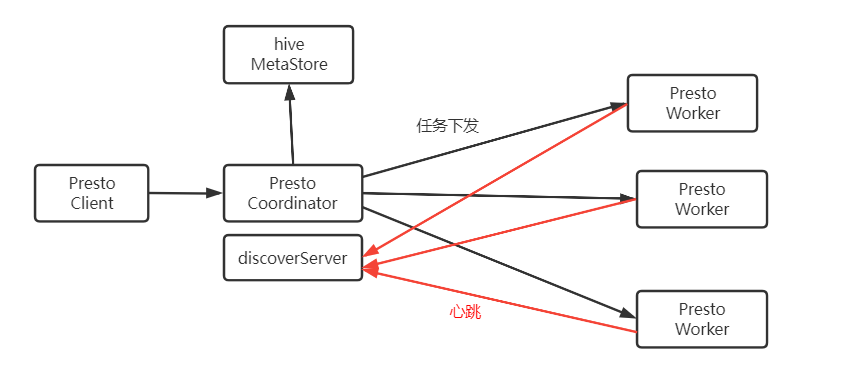
presto高可用配置#
在worker的配置中,可以选择配置:
-
discovery的ip:port。
-
一个http地址,内容是service inventory,包含discovery地址。
-
一个本地文件地址
2和3的原理是基于service inventory, worker 会动态监听这个文件,如果有变化,load出最新的配置,指向最新的discovery节点。
在设计上,discovery和coordinator都是单节点。如果有多个coordinator同时存活,worker 会随机的向其中一个汇报进程和task状态,导致脑裂。调度query时有可能会发生死锁。
discovery和coordinator可用性设计:
由于service inventory的使用,监控程序可以在发现discovery挂掉后,修改service inventory中的内容,指向备机的discovery,无缝的完成切换。
coordiantor的配置必须要在进程启动时指定,同一个集群中无法存活多个coordinator。因此最好的办法是和discovery配置到一台机器。 secondary机器部署备用的discovery和coordinator。在平时,secondary机器是一个只包含一台机器的集群,在primary宕机时,worker的心跳瞬间切换到secondary。
presto高可用解决方案选型#
Presto的高可用主要解决的是Coordinator/Discovery Server的单点问题。
Presto高可用的解决有很多种方案,比如用HAProxy+Keepalived或者云服务商提供的lb这样的外部组件,但问题是这样就需要用VRRP这类虚拟IP来解决单点问题,而我们尽量要做到集群内部组件不依赖外部组件,这样从架构上来说,系统复杂度最低,也最容易维护。
综上,我们需要修改Presto底层源码来解决。
Presto的discovery其实就是airlift discovery,通过阅读源码,发现其内部是支持HA的,只是Presto的官方文档上没有展示出来。
presto on yarn#
presto on yarn是一种动态的运行策略,在yarn上面,哪个节点运行presto的coordinator和worker是不确定的,这会给外部调用presto的程序带来困扰
外部的程序和presto的交流一般是通过presto提供的客户端来调用,而它的客户端需要事先知道presto的coordinator地址,在presto on yarn的情况下,coordinator的地址是不确定的,有可能会发生变化。
这种情况下的处理方案是:将presto的服务发现方案外置,将presto的服务发现服务独立于presto的coordinator运行,将presto的coordinator和worker中的discovery.uri配置成外部独立的发现服务地址,在外部提供具有HA的服务发现,提供稳定的发现服务。
Presto的服务发现是基于airlift的服务发现做的实现,airlift的服务发现可以在这里查看实现和源码,不过它基本是处于无文档的状态,所以理解要多花些功夫。
airlift的服务发现的总体思路是基于http提供一个提供服务发现的HA集群,集群之间通过http通信,通过数据同步方式,提供最终一致性的保证。