[toc]
Q: kafka为什么那么快?底层原理是什么?#
A:
- Cache Filesystem Cache PageCache缓存
- 顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
- Zero-copy 零拷技术减少拷贝次数
- Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
- Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
Q: kafka的message格式是什么样的?#
A:
一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成
-
header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。
-
当magic的值为1的时候,会在magic和crc32之间多一个字节的数据:attributes(保存一些相关属性,
-
比如是否压缩、压缩格式等等);如果magic的值为0,那么不存在attributes属性
-
body是由N个字节构成的一个消息体,包含了具体的key/value消息
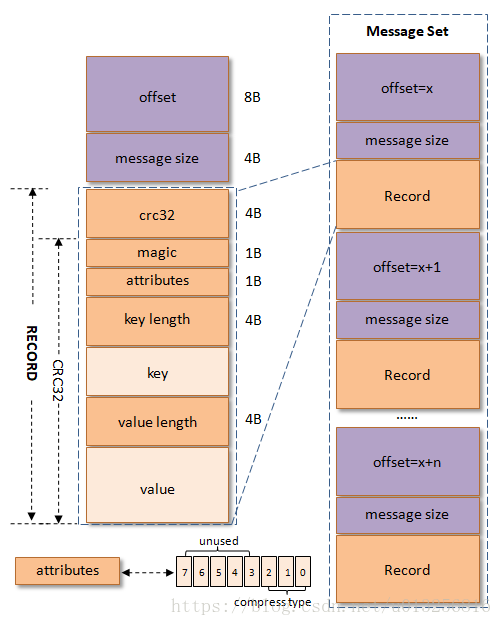
kafka的消息格式其实具有演变:一文看懂Kafka消息格式的演变
Q: kafka如何实现延迟队列?#
A:
Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)。JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(nlog(n)),并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。时间轮的应用并非Kafka独有,其应用场景还有很多,在Netty、Akka、Quartz、Zookeeper等组件中都存在时间轮的踪影。
https://blog.csdn.net/u013256816/article/details/80697456