- Q: 什么是partition的预写式日志?
- Q: kafka如何实现故障自动转移?
- Q: leader和flower如何同步数据?
- Q: HW和LEO是什么?
- Q: 如果某个follower拉取同步太慢, 远远落后leader,会怎么样?
- Q: 为什么同步可能会慢?
- Q: 怎么确定多慢要剔除?
- Q: 详细描述一下当producer生产消息至broker后,ISR以及HW和LEO的流转过程
- Q: leader怎么知道其他follower的同步进度?
- Q: ISR怎么反馈和存储?
- Q:这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,会怎么样?
- Q: 从leader的磁盘数据同步到follower,借助了什么机制加快了传输效率?
- Q: 生产者向broker发数据, ack的返回值有什么含义?
- Q: 为什么选择主写读写, 而不是读写分离?
[toc]
Q: 什么是partition的预写式日志?#
A:
Kafka中主题的每个Partition有一个预写式日志文件
每个Partition都由一系列有序的、不可变的消息组成
这些消息被连续的追加到Partition中,Partition中的每个消息都有一个连续的序列号叫做offset, 确定它在分区日志中唯一的位置。
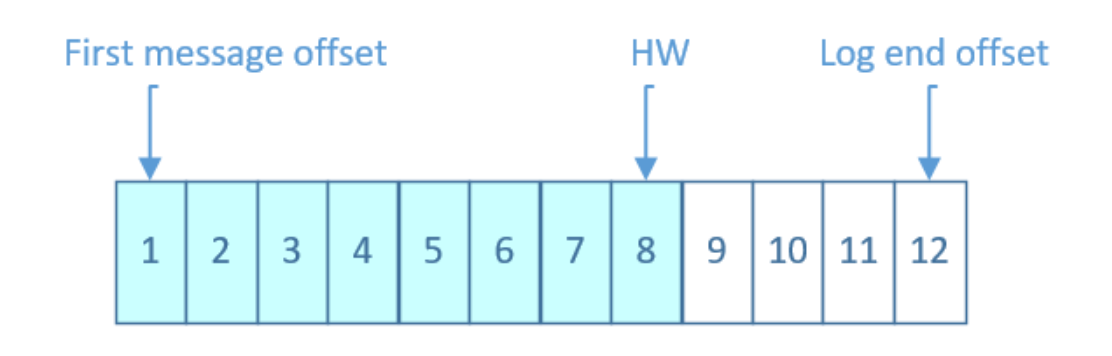
Kafka每个topic的partition有N个副本,其中N是topic的复制因子
如下图
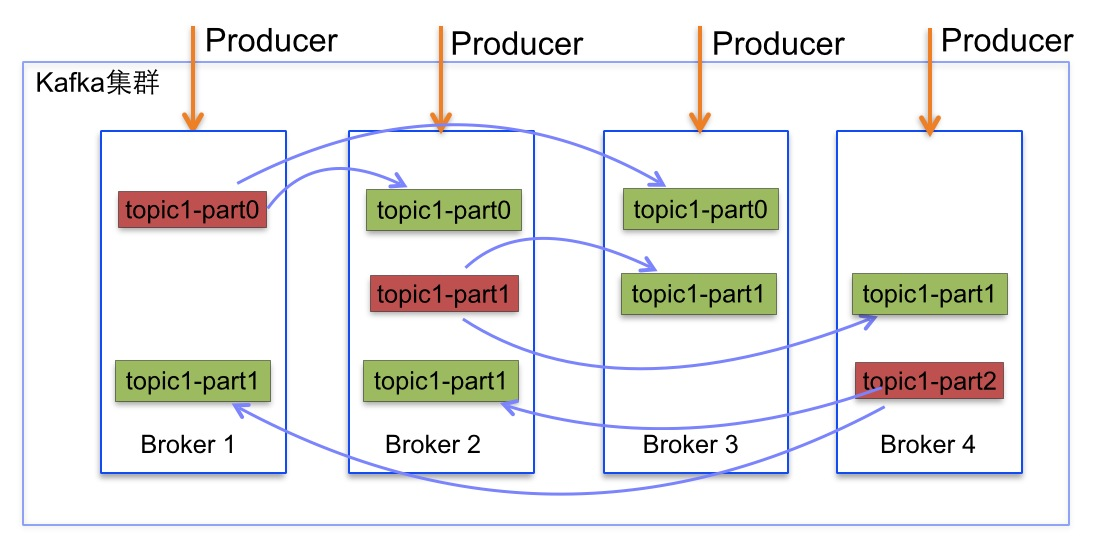
Q: kafka如何实现故障自动转移?#
A:
如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。
Kafka确保从同步副本列表中选举一个副本为leader。消费者去新的leader进行数据读取。
Q: leader和flower如何同步数据?#
A:
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。
事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率(写入的响应)。
而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入预写log就被认为已经commit,写请求可以返回。 然后让follower异步、被动、定期地去复制leader上的数据
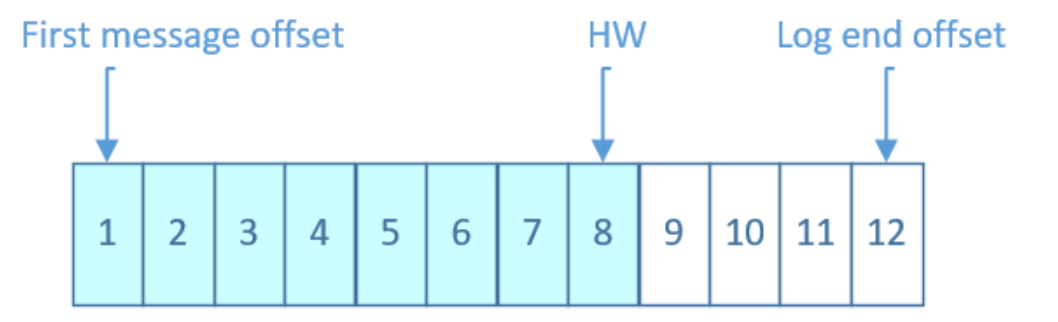
Q: HW和LEO是什么?#
A:
LEO是log end offset, 预写日志最后的偏移
HW是HighWatermark,所有副本的水位线,是leader来确定的。
取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置
Q: 如果某个follower拉取同步太慢, 远远落后leader,会怎么样?#
A:
follower从leader同步数据有一些延迟。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
AR=ISR+OSR。
所有的副本(replicas)统称为Assigned Replicas,即AR
ISR:In-Sync Replicas 副本同步队列
Q: 为什么同步可能会慢?#
A:
- 慢副本:在一定周期时间内follower不能追赶上leader。最常见的原因之一是I / O瓶颈导致follower追加复制消息速度慢于从leader拉取速度。
- 卡住副本:在一定周期时间内follower停止从leader拉取请求。follower replica卡住了是由于GC暂停或follower失效或死亡。
- 新启动副本:当用户给主题增加副本因子时,新的follower不在同步副本列表中,直到他们完全赶上了leader日志
Q: 怎么确定多慢要剔除?#
A:
replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度,
当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR
Q: 详细描述一下当producer生产消息至broker后,ISR以及HW和LEO的流转过程#
A:
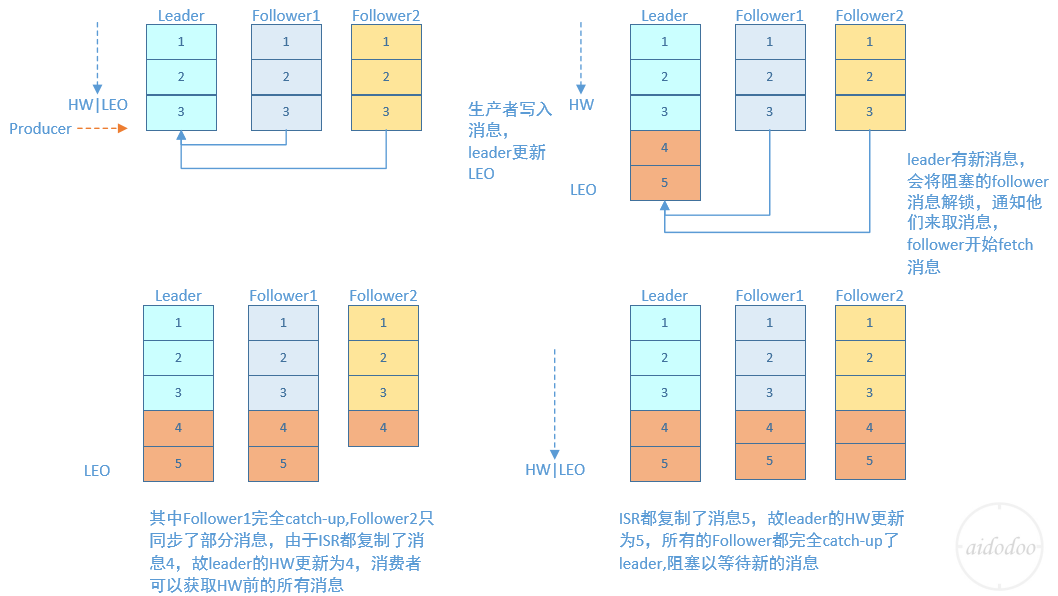
Q: leader怎么知道其他follower的同步进度?#
A:
可以定时检测, follower来拉取时,要携带自己的同步进度偏移的。
Q: ISR怎么反馈和存储?#
A:
Kafka的ISR的管理最终都会反馈到Zookeeper节点上。具体位置为:/brokers/topics/[topic]/partitions/[partition]/state。目前有两个地方会对这个Zookeeper的节点进行维护:
- Controller来维护:Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配partition之类的管理任务。在符合某些特定条件下,Controller下的LeaderSelector会选举新的leader,ISR和新的leader_epoch及controller_epoch写入Zookeeper的相关节点中。同时发起LeaderAndIsrRequest通知所有的replicas。
- leader来维护:leader有单独的线程定期检测ISR中follower是否脱离ISR, 如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
Q:这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,会怎么样?#
A:
两者之间的HW同步有一个间隙,B在同步A中的消息之后需要再一轮的FetchRequest/FetchResponse才能更新自身的HW为5。
-
如果在更新HW之前,B宕机了,那么B在重启之后会根据之前HW位置进行日志截断,这样便会将4这条消息截断,然后再向A发送请求拉取消息。
-
此时若A再宕机,那么B就会被选举为新的leader。
B恢复之后会成为follower,由于follower副本的HW不能比leader副本的HW高,所以还会做一次日志截断,以此将HW调整为4。这样一来4这条数据就丢失了(就算A不能恢复,这条数据也同样丢失了)。
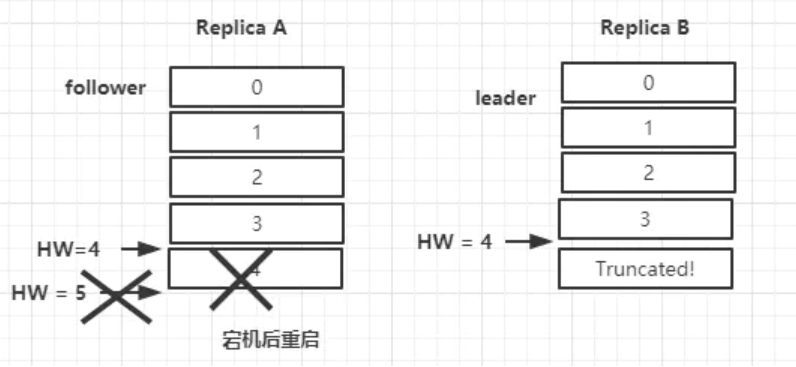
会丢失一部分数据,但概率比较低, 一般一定有最近的一个follower同步过去。
Q: 从leader的磁盘数据同步到follower,借助了什么机制加快了传输效率?#
A:
充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能
直接从磁盘到网络,避免中间buffer。
Q: 生产者向broker发数据, ack的返回值有什么含义?#
A:
- 1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
- 0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
Q: 为什么选择主写读写, 而不是读写分离?#
A:
- 数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
- 延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
参考链接:
https://www.cnblogs.com/aidodoo/p/8873163.html
https://blog.csdn.net/kwame211/article/details/107402104