[toc]
它最初是由LinkedIn公司开发的,之后成为Apache项目的一部分
主要用于处理流式数据。
Q: kafka中有哪些关键角色?#
A:
- Kafka对消息保存时根据Topic进行归类,Topic可以理解为一个队列
- 发送消息者称为Producer
- 消息接受者称为Consumer
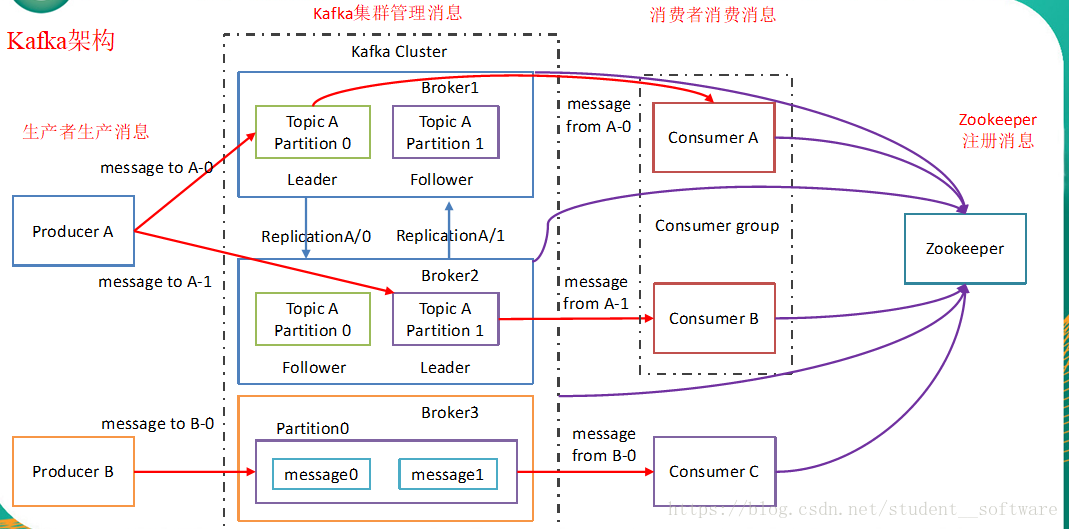
- 此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
- 无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
- Partition:一个topic可以分为多个partition,每个partition是一个有序的队列
- Offset:kafka的存储文件都是按照offset.kafka来命名。你想找位于2049的位置,只要找到2048.kafka的文件即可
- ISR:In-Sync Replicas 副本同步队列
- AR:Assigned Replicas 所有副本
Q: 详细解释下broker?#
A:
Producers(生产者程序)往Brokers里面的指定Topic中写消息
Consumers(消费者程序)从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
Q: zk在kafka中的作用?#
早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值
zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
Zookeeper保存kafka的集群状态信息的,包括每个broker,为什么?
因为zk和broker建立监听,一旦有一个broker宕机了,另一个备份就可以变为领导,第二,zk保存消费者的消费信息,为什么要保存?就是为了消费者下一次再次消费可以得知offset这个偏移量,consumer信息高版本在本地维护
1
Q: kafka中consumer group 是什么概念#
A:
对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费
worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)
- 同一个消费者组里面不能是同时消费者消费消息,只能有一个消费者去消费
- 同一个消费者组里面是不会重复消费消息的
- 同一个消费者组的一个消费者不是以一条一条数据为单元的,是以分区为单元,就相当于消费者和分区建立某种socket,进行传输数据,所以,一旦建立这个关系,这个分区的内容只能是由这个消费者消费
Q: 怎么实现消费者消费不同的数据?#
A: 将消费者放在同一组取数据
Q: 生产环境一般要求消费者消费的数据一样且多个,比如一个写到hdfs,一个放到spark计算,怎么做#
A:
这样就得要求相同数据拷贝,放到不同的消费者组里, 各消费者在不同的消费组里进行消费。
Q: 为什么说kafka是分布式的?#
A:
- 同一个topic又拥有不同的分区,不同的分区可以分布在不同的borker上也就是不同的机子上
- 消费者组里的消费者可以在不同的机器上,有什么好处?消费的方式可以是存储可以是计算,如果是放在一台机子上,Io等压力很大
- kafka上面的所有想到的角色都是分布式的,不管是消费者还是生产者还是分区,他们之间沟通的唯一桥梁就是zookeeper
Q: 项目选型kafka的理由?#
A:
kafka:适合数据下游消费众多的情况;适合数据安全性要求较高的操作,支持replication。为什么适合数据下游消费众多?因为有就算有多个消费者,kafka里面存的数据是一样的,不会再增加副本。
在实际生产应用中,一般会使用kafka做为消息传输的数据管道
rabbitmq做为交易数据做为数据传输管道
主要的取舍因素则是是否存在丢数据的可能;
rabbitmq在金融场景中常用,具备较高的严谨性,数据丢失的可能性更小,同事具有更高的实时性;
而kafka优点主要体如今吞吐量上,虽然能够经过策略实现数据不丢失,但从严谨性角度来说,大不如rabbitmq;并且因为kafka保证每条消息最少送达一次,有较小的几率会出现数据重复发送的状况;
- 吞吐量较低:Kafka和RabbitMQ都可以。:
- 吞吐量高:Kafka。
flume 适合多个生产者;适合下游数据消费者不多的情况
Q: kafka一般的应用场景?#
A:
线上数据 --> flume --> kafka --> HDFS:所以一般情况下,企业用flume收集日志数据,然后下游sink选择kafka
架构图如下: