[toc]
Q: 吞吐量(TPS)是什么#
A:
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。
TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
- 对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数
- 对于并发系统而言,有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n×t小很多(因为并发执行,很多资源是交叉使用的)
- 吞吐量是一个比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致
Q: QPS是什么#
A:
(Query Per Second)
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 (看来是类似于TPS,只是应用于特定场景的吞吐量)
Q: QPS和TPS的区别?#
A:
QPS是最大吞吐能力。
TPS是针对单个请求的简单事务处理能力判断。更多是针对单个接口而言。
Q: TP是什么?#
A:
响应时间是指系统对请求作出响应的时间。是用户感知的时间,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。
Q: 接口访问量过大会发生什么?#
A:
服务器可能会崩溃。
服务器对于请求都是排队的,负载不大的时候感觉不到,因为都是1秒内处理了。
当请求数量上去后,就开始有感觉了。继续增大的话,队列会占满了,服务器开始丢弃部分请求
继续增大网络请求,操作系统的TCP协议栈也开始丢弃请求,对外表现为服务器网络也连不上了。
继续增大的话,网卡硬件部分开始满速运行,然后就看操作系统驱动和硬件质量了。
另一种说法:
当访问量大的时候,后端发送给数据库的请求多,数据库并发读取或写入,受系统io影响,服务器磁盘io是固定的,一般受硬盘硬件读写影响,读写越多,io越高,到达上线就会等待,出现io等待,CPU就会等待,内存也会占用不释放,然后越来越多的请求阻塞,恶性循环,系统资源耗尽,系统崩溃,这也是为什么要提高性能,各种做缓存,从cdn到业务层缓存,代码编译缓存,数据库缓存
Q: 应对高并发、大流量有哪些常见手段?#
A:
- 扩容——提升集群并行处理能力
- 静态化——静态数据由cdn返回
- 限流
- 缓存
- 队列——当上下游处理能力存在差距时,通过队列形成漏斗,等下游有处理能力时自己来消费。
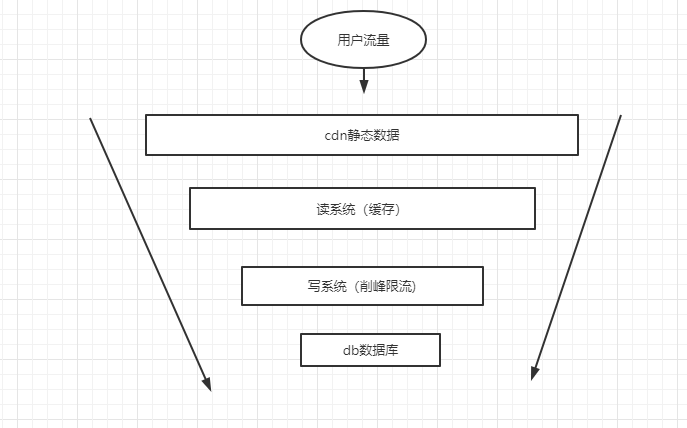
Q: 什么是流量的漏斗模型?#
A:
即流量要经过的系统如同漏斗一样, 访问db应当是最少也最后才到达的地方
Q: 如何做接口限流?#
A:
- 对客户端、前端限速,复杂业务操作例如验证码等,或者短时间内限制频繁操作次数上限。
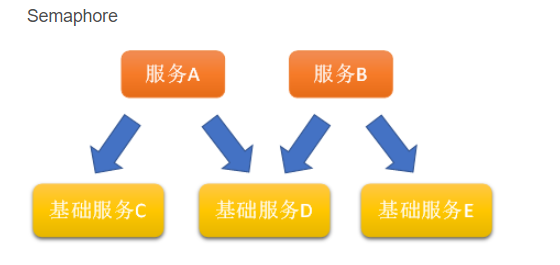
- 如果自己这个接口是基础接口,被内部调用, 则也要限制内部服务的并发,单纯增加服务A和B的数量,基础服务没跟上,会造成雪崩效应。
- 使用漏桶算法
- 不管服务调用多么不稳定,我们只固定进行服务输出,比如每10毫秒接受一次服务调用。既然是一个桶,那就肯定有容量,由于调用的消费速率已经固定,那么当桶的容量堆满了,则只能丢弃了
- 实现方面,可以先准备一个队列,当做桶的容量,另外通过一个计划线程池(ScheduledExecutorService)来定期从队列中获取并执行请求调用,当然,我们没有限定一次性只能从队里中拿取一个请求,比如可以一次性拿100个请求,然后并发执行
- 缺点:严格限制的吞吐量,无法响应瞬发性的高峰流量。
-
使用令牌桶算法
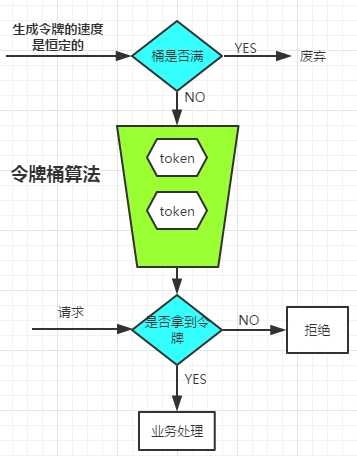
生成令牌的速度是恒定的,而请求去拿令牌是没有速度限制的。这意味,面对瞬时大流量,该算法可以在短时间内请求拿到大量令牌,而且拿令牌的过程并不是消耗很大的事情。
令牌桶源码解读 -
计数器算法
在单位时间内, 有一个专门的计数器进行计数, 每请求一次计数器就+1,。 单位时间内如果到达阈值,则后续请求进行限流处理。 只有时间临界点到达后,才会重置,新的请求才能访问。
单位时间计数器可以用redis的setnx实现
要在 10 秒内限定 20 个请求,那么可以在 setnx 的时候设置过期时间 10,当请求的 setnx 数量达到 20 的时候即达到了限流效果。
Redis Setnx(SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
也可以用redis的zset实现
将请求打造成一个zset数组,当每一次请求进来的时候,value保持唯一,可以用UUID生成,而score可以用当前时间戳表示,因为score我们可以用来计算当前时间戳之内有多少的请求数量。而zset数据结构也提供了range方法让我们可以很轻易的获取到2个时间戳内有多少请求
Q: 如何设计一个限时抢购的功能#
例如每个商品都有特定的可抢购次数例如10w, 但是如果同时打进来可能直接导致数据库出现较大的负载压力。
A:
应用层代码里用简单的时间片算法, 某一时间内阈值是1000, 时间到了后就拒绝后面用户的抢购,时间点到了后再允许接收。
同时开发一个接口, 支持动态修改其中的各个参数。
另外如果商品数量过多,每个商品都有阈值, 可能总量会超出, 所以要根据商品总量动态调整每个商品的阈值上限。
Q: 如何在 产品设计上进行削峰?#
A:
- 高流量活动分时段进行, 例如抢购5000个商品,分5个时间段,每个时间段开放1000个。
- 答题验证,验证码
Q: 如何避免高并发写的场景下的数据库超卖问题#
A:
在Innodb中使用乐观锁来实现写入。
每次写入前先查出商品剩余量和version
调用update的时候加上where version条件, 如果version发生变化,自然就会update失败,于是进行重试。
虽然还是会占行锁, 但是不会造成请求线程阻塞。
Q: 如果库存充足, 无论多少的写请求都一次性打给数据库吗?(和限时抢购不同,不考虑写失败)#
A:
可以使用redis缓存做库存扣减。
- 客户端调用WATCH + (商品id) 这个命令
- 调用MULTI命令标记事务块的开始
- 输入写命令。
- 调用EXEC进行事务提交
如果商品的缓存值在WATCH后被修改了, 则EXEC会失败, redis之后再重试即可。
Q: WATCH的原理是什么?#
A:
redis服务端会 维持一个监听key的客户端链表
当key发生变化之后, 这个key对应的客户端会被标记成REDIS_DIRTY_CAS状态
当接收到后面这个客户端的EXEC请求时,就返回执行失败。
Q: redis写成功,那什么时候同步到数据库呢?#
A:
将写成功的消息写入雕铣队列, 通过消息队列来实现削峰,确保写入数据库时的流量可控。
秒杀系统设计题#
秒杀系统,库存只有一份,所有人会在集中的时间读和写这些数据,多个人读一个数据
Q: 设计一个秒杀系统大概要在哪些层面设计?#
A:
首先考虑重要优化点:
- 将请求尽可能拦截在上游。 因为实际上写操作不会有那么多。
- 充分利用缓存。因为大部分失败的人都是读操作。
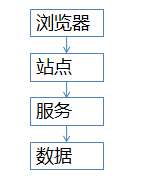
那么基于这2点,设计下面的架构: - 浏览器端,最上层,会执行到一些JS代码
- 站点层,这一层会访问后端数据,拼html页面返回给浏览器(即和浏览器直接交互的)
- 服务层,向上游屏蔽底层数据细节,提供数据访问(即直接提供数据查询的服务,这里数据实际读取和返回前台响应分成了2个服务)
- 数据层,最终的库存是存在这里的,mysql是一个典型(当然还有会缓存)
各部分优化措施如下:
- 浏览器和APP:做限速
- 站点层:按照uid做限速,做页面缓存
- 服务层:按照业务做写请求队列控制流量,做数据缓存
- 数据层:闲庭信步
Q: 浏览器层可以怎么拦截?#
A:
验证码、 短时间内访问次数限制。 分段销售
Q: 站点层怎么防护?#
A:
站点层根据用户id做请求计数, uid只能5秒通过一次。这样可以避免恶意用户频繁用一个uid绕过客户端限制去下单。
同时补充页面缓存。
Q: 10w个不同的uid同时打入,站点层缓存拦不住了,到服务层了,怎么办?#
A:
服务层设计一个请求队列,每次只透有限的写请求去数据层
读请求怎么办? 用数据缓存。cache缓存动态扩容。 热点发现
Q: 写队列满了怎么办?#
A:
最坏的情况下,缓存了若干请求之后,后续请求都直接返回“无票”(队列里已经有100w请求了,都等着,再接受请求也没有意义了)
Q: 秒杀后未支付,怎么办?#
A:
数据库里一个状态,未支付。如果超过时间,例如45分钟,库存会重新会恢复(大家熟知的“回仓”)
Q: 系统做了主从读写分离时, 怎么保证写之后能马上读到新数据?#
A:
用切面的方式做注解
通过注解判断哪些请求走主库,哪些请求走从库
例如有些场景写之后马上就读的概率很高,那就走主库
如果有些场景对读的实时性要求不高,那就从走从库
或者用一些mycat中间件。