[toc]
Q: 消息队列的作用是什么?#
A:
-
解耦:
通过一个MQ,发布和订阅模型(Pub/Sub模型),系统A就和其它系统彻底解耦。
需要考虑一下负责的系统中,是否有类似的场景,就是一个系统或者一个模块,调用了多个系统,互相之间的调用很复杂,维护起来很麻烦。(新增、删除接口都是要两边互相适配)
但是其实这个调用是不需要同步调用接口的(不需要等待返回),如果用MQ给他异步化解耦,也是可以的,这个时候可以考虑在自己的项目中,是不是可以运用这个MQ来进行系统的解耦。 -
异步:
加快接口的返回。 -
削峰
就是大量的请求过来,然后MQ将其消化掉了,然后通过其它系统从MQ中取消息,在逐步进行消费,保证系统的有序运行。一般高峰期不会持续太长,在一段时间后,就会被下游系统消化掉。
Q: 消息队列都有什么缺点?#
A:
- 系统可用性降低: MQ挂掉的话很危险
- 系统复杂性提高:要考虑消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性
- 一致性问题:存在关联的消息,被不同消费者消费,如果另一个消费者执行失败,如何感知和回退?
Q: Kafka、activeMQ、RibbitMQ、RocketMQ都有什么优缺点?#
A:
列出一个表格
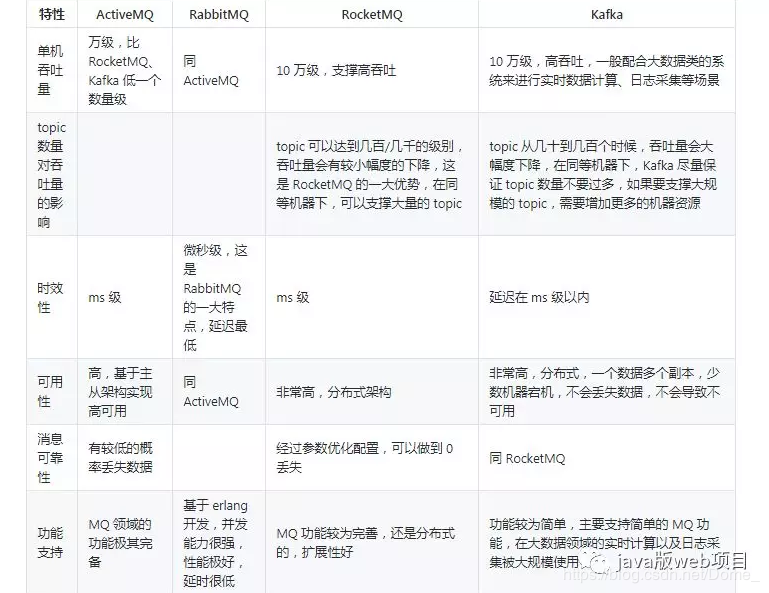
简单记忆rabitMq和kafka的区别
- kafka高吞吐,适合大数据量的实时计算、日志采集。 但rabitMq的时延更小。
- rabitMq基于主从, kafka则支持分布式(多副本)
- rabitQq基于erlang开发, kafka用scala开发。
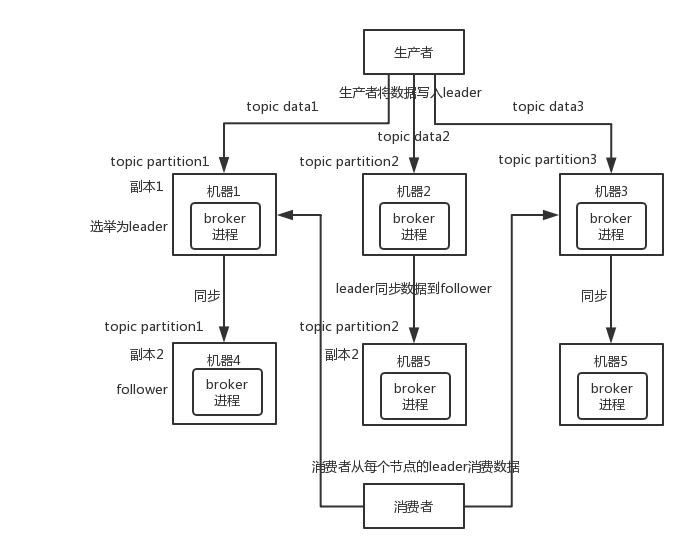
Q: 如何保证消息队列的高可用?不会因为1台消息队列服务挂掉导致服务失灵?#
A:
只讲一下kafka的
每个partition属于多台机器。
有一个是leader节点
leader会把数据同步到另外2台机器。
如果leader挂了,则消费者选择读取 这个partition的另外2台机器
假设其中的一个leader宕机了,但是因为每个leader下还有多个follower,并且每个follower都进行了数据的备份,因此kafka会自动感知leader已经宕机,同时将其它的follower给选举出来,作为新的leader,并向外提供服务支持。
Q: 怎么知道leader掉线?#
A:
对于Kafka而言,定义一个Broker是否“活着”包含两个条件:
一是它必须维护与ZooKeeper的session(这个通过ZooKeeper的Heartbeat机制来实现)。
二是Follower必须能够及时将Leader的消息复制过来,不能“落后太多”。
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica)。如果一个Follower宕机,或者落后太多,Leader将把它从ISR中移除
更详细的解释,包括如何感知掉线(ack、zk-session)、如何选举
Kafka学习之路 (三)Kafka的高可用
Q: 如何保证消息不会被重复消费?#
A: 需要消息消费者保证幂等性, 同样的消息,消费2次,结果是一样的。
幂等性是什么?通俗点说:幂等性就是一个数据,或者一个请求,以相同的内容和方式给你执行多次,得保证对应的数据不会改变,并且不能出错,这就是幂等性。(这样才能做到发送者搞重试或者多发问题)
Q: 是如何保证消息消费时一定是幂等的?#
A:
需要应用服务器消费消息时是幂等的, 注意消息队列不保证幂等。
消费中如果是insert相关,且只会insert1次的,通过主键判断,避免重插(消费端)
消费端业可以加一个redis, 以缓存消费过的记录, 重复消费可以通过redis识别,并且redis是临时缓存,不会占用太多资源。
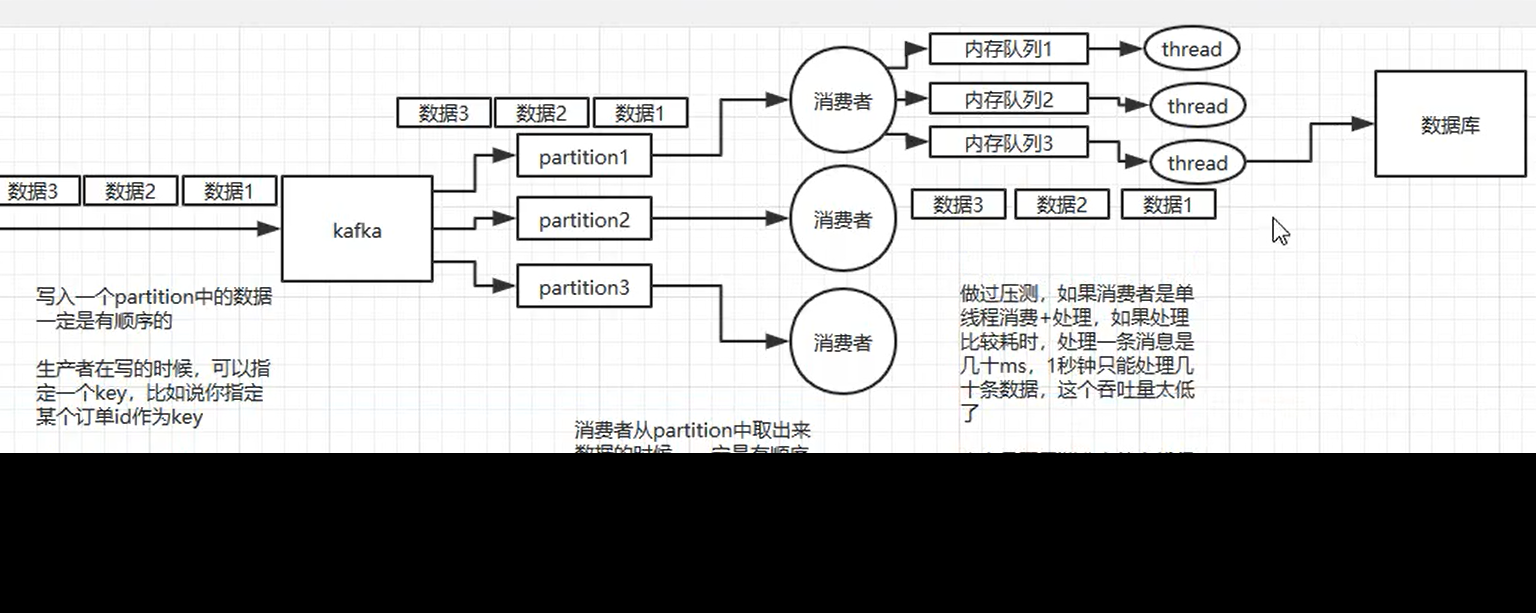
Q: 消息队列 mq 怎么保证顺序消费?#
A:
abbitmq 中, 每个消费者对应一个队列
kafka中, 每个消费者对应一个 partition。 partion中是有序的。
即kafka能保证塞入partion时是有序的
因此你要求有序的那堆请求,要有相同的key映射到同一个partion
同时消费者处理的时候,也要按照核心key在内存中分配给不同的线程(内存线程使用加锁队列去获取消息), 避免多线程处理的时候出现混乱
Q: 如何保证消息的可靠性传输,不会丢失?#
A:
生产者发送到 MQ的时候丢了: 生产者使用ack机制,如果超时没收到,就回调nack接口做重发
MQ没发给消费者: 消息持久化,如果MQ挂了,还可以从磁盘中恢复重发。(ack应该在存盘后再发给生产者)
消费端没收到数据或者消费者挂了:
关闭MQ的自动ack, 在消费者的代码逻辑里自己实现ack机制,保证是自己处理完成后才发ack,而不是收到了就发ack。
对于kafka来说, 消费者的ack其实就是offset。 offset不能自动发,要自己实现。
Q:消息队列满了, 发生阻塞积压怎么办?例如突然流量峰值, 几百万消息持续积压?#
A:
运维根据告警信息, 对queue资源和consumer资源都临时进行紧急进行人工扩容。
Q: 如果让你写一个消息队列,该如何进行架构设计,说一下你的思路?#
A:
-
首先MQ得支持可伸缩性
那就需要快速扩容,就可以增加吞吐量和容量,可以设计一个分布式的系统,参考kafka的设计理念,broker - > topic -> partition,每个partition放一台机器,那就存一部分数据,如果现在资源不够了,可以给topic增加partition,然后做数据迁移,增加机器,不就可以存放更多的数据,提高更高的吞吐量 -
其次得考虑一下这个MQ的数据要不要落地磁盘?也就是需不需要保证消息持久化,因为这样可以保证数据的不丢失,那落地盘的时候怎么落?顺序写,这样没有磁盘随机读写的寻址开销,磁盘顺序读的性能是很高的,这就是kafka的思路。
-
其次需要考虑MQ的可用性?这个可以具体到我们上面提到的消息队列保证高可用,提出了多副本 ,leader 和follower模式,当一个leader宕机的时候,马上选取一个follower作为新的leader对外提供服务。
-
需不需要支持数据0丢失?可以参考kafka零丢失方案