[toc]
本地缓存#
Q: 什么是本地缓存?#
A:
即在客户端、应用端进行本地缓存, 或在jvm中缓存或在程序的堆外缓存。中间没有跨网络的开销
Q: 有哪些本地缓存产品?#
A:
- Ehcache(Hibernate的二级缓存就用的这个)
- GuavaCache(轻量,易用,有丰富的被动更新机制)
- MapDb(支持堆外内存)
Q: 本地缓存有什么缺点?#
A:
- 本地缓存会占用jvm有限的内存资源
- 高潮gc次数过快可能会导致贤者时间(stopworld)的延长。
- 只在本地缓存, 容易引发数据不同步。
Q: 本地缓存有哪些更新方式?#
A:
- 被动更新
通过自己设置的超时时间, 超期后就自动进行更新,更新就是去重新发请求获取。。 - 主动更新
数据发生变更,主动通过消息队列的方式同步给订阅的应用(适用于内部服务配置订阅),应用进行更新。
Q: 被动更新本地缓存有什么要注意的地方?#
A:
如果同时失效的缓存很多, 需要控制更新时的线程必须只有1个, 如果支持同时触发多个线程进行请求更新,可能导致大量请求打到分布式缓存上引发雪崩。
两种方式:
- expireAfterWrite, 各超期的缓存起线程准备发请求时,需要先抢到锁,抢到了才能发,否则就阻塞(对性能要求不高可以选这个)
- refreshAfterWrite, 也是抢锁,区别是如果抢不到,就返回旧值,等下次超期再抢。 ( 数据实时性要求不高的情况下可以选择这个)
Q: 什么是off-heap技术?有什么好处#
A:
堆外内存技术, 将数据存在jvm外的操作系统内存上,避免和原jvm进程互相干扰,因此也不会参与垃圾收集器gc。
好处:
- 减少gc次数
- 扩展和使用更大的内存空间
- 省去了物理内存和heap进程内存之间的数据复制步骤,类似于零拷贝了。
Q: 怎么使用off-heap?#
A:
- NIO有个ByteBuffer.allocateDirect(int capacity)方法, 可以生成一个DirectByteBuffer实例
- 根据参数capacity的值,它会在物理内存中分配一块固定大小的直接字节缓冲区。
- 本质上是调用sum.misc.unsafe里实现的native方法进行内存分配操作。
- 可用-XX:MaxDirectMemorySize限制总的最大堆外申请大小,避免申请过多。
Q: directByteBuffer的内存什么时候会被释放? 需要自己写C++代码释放吗?#
A:
不需要。 directByteBuffer在jvm中仍然是段引用,只不过buffer数据存到堆外了。 当这个buffer引用被回收了, 那么buffer背后的堆外内存也会被回收。
分布式缓存#
Q: 一致性哈希是做什么的?#
A:
https://blog.csdn.net/qq_42046105/article/details/92802476
普通的哈希表算法一般都是计算出哈希值后,通过取余操作将 key 值映射到不同的服务器上
但是当服务器数量发生变化时,取余操作的除数发生变化,所有 key 所映射的服务器几乎都会改变,这对分布式缓存系统来说是不可以接收的。
一致性哈希算法能尽可能减少了服务器数量变化所导致的缓存迁移。
以分布式缓存场景为例,分析一下一致性哈希算法环的原理。
首先将缓存服务器( ip + 端口号)进行哈希,映射成环上的一个节点,计算出缓存数据 key 值的 hash key,同样映射到环上,并顺时针选取最近的一个服务器节点作为该缓存应该存储的服务器。具体实现见后续的章节。
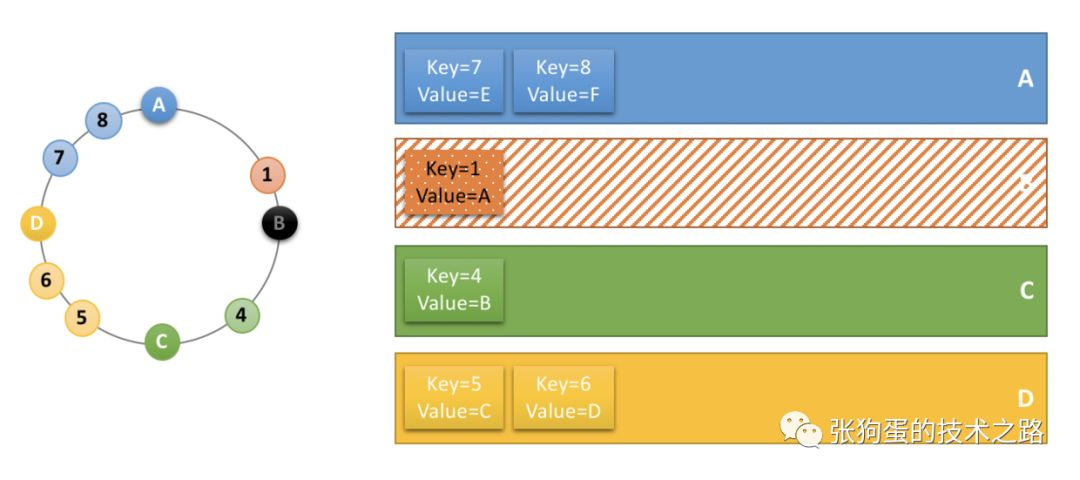
服务器 B 宕机下线,服务器 B 中存储的缓存数据要进行迁移,但由于一致性哈希环的存在,只需要迁移key 值为1的数据,其他的数据的存储服务器不会发生变化。这也是一致性哈希算法比取余映射算法出色的地方。
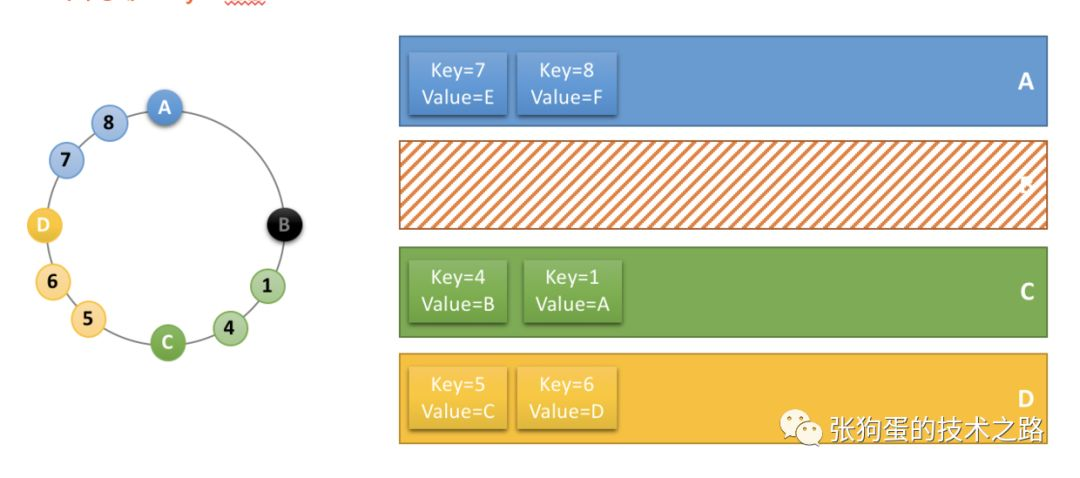
现实情况下,服务器在一致性哈希环上的位置不可能分布的这么均匀,导致了每个节点实际占据环上的区间大小不一。
这种情况下,可以增加虚节点来解决。通过增加虚节点(即A节点实际对应好几个虚节点),使得每个节点在环上所“管辖”的区域更加均匀。
这样就既保证了在节点变化时,尽可能小的影响数据分布的变化,而同时又保证了数据分布的均匀。
Q: 分槽算法是什么?#
A:
在redis官方给出的集群方案中,数据的分配是按照槽位来进行分配的,每一个数据的键被哈希函数映射到一个槽位,redis-3.0.0规定一共有16384个槽位,当然这个可以根据用户的喜好进行配置。当用户put或者是get一个数据的时候,首先会查找这个数据对应的槽位是多少,然后查找对应的节点,然后才把数据放入这个节点。这样就做到了把数据均匀的分配到集群中的每一个节点上,从而做到了每一个节点的负载均衡,充分发挥了集群的威力。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了;
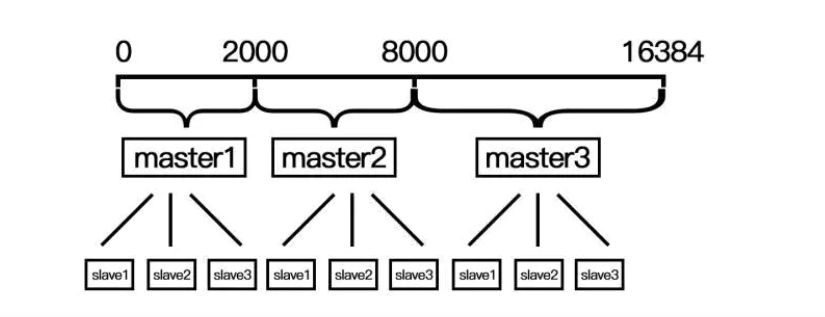
一致性哈希和分槽算法
Q: 缓存穿透是什么?解决方式是?#
A:
大量不存在的请求攻入,反复去查询数据库
对于不存在的数据,可以用布隆过滤器(对1个值做多个不同的哈希,放入不同的位图位置里, 后面计算的时候,看下是否有1个位置没满足,没满足就一定不存在)
Q: 缓存中的布隆过滤器是什么?
A:
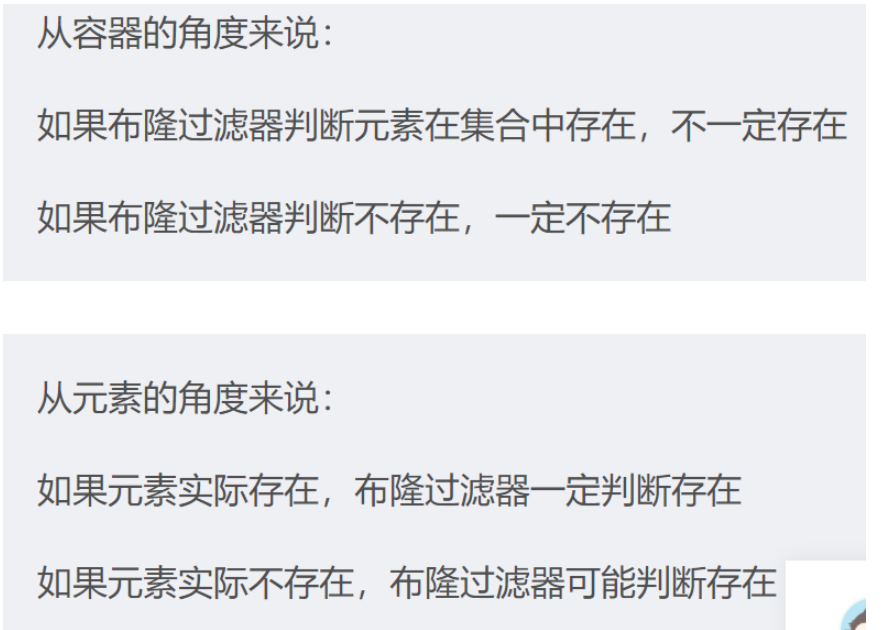
Q: 要是分布式缓存发生雪崩了怎么办,要怎么防止发生#
A:
缓存雪崩可能是因为数据未加载到缓存中,或者一大堆缓存在同一时间大面积的失效过期,从而导致所有请求都去查数据库,导致数据库CPU和内存负载过高,甚至宕机。
解决方式:
-
缓存失效可以通过加锁或队列来控制读取数据库的访问的线程数量,比如对某个key值运行一个线程访问数据库,其他线程等待
-
不同的key,设置不同的过期时间,让失效的时间点尽量均匀或者随机,避免一下子大面积失效。
-
做二级缓存,a1失效时候,访问a2,a1失效的时间设置为短期,a2为长期
Q: 几十万的用户同时访问某个数据,但这个数据正好缓存里没有,导致十几万的请求打到数据库上,这种情况叫做什么?怎么解决?#
A:
这种情况叫做 ”缓存击穿“。
- 延长热点数据的缓存超期时间。 提前预置热点缓存。
- 接口限流、降级、队列。
Q: 缓存过多时,如何进行筛选和淘汰?#
A:
没啥人用的数据占用了很多内存,叫缓存污染
Redis共支持八种淘汰策略。
- 第一类: 不淘汰
- noeviction
如果满了,新的写请求就报错
- 第二类:淘汰部分过期数据
当缓存满却收到新的写请求时,从会过期数据中选一个淘汰。
- volatile-random 随机删除过期数据中的某一个
- volatile-ttl: 越早过期的数据,越优先被删除
- volatile-lru:局部最近最少使用(即过期数据中一直没被用过的,优先删)。
特点是会从集合中随机选N个,从N个里选一个LRU最小的删除。
好处:Redis不用维护一个巨大的链表,也不用操作链表,进而提升性能 - volatile-lfu:
增加了访问次数
先在过期集合中判断访问次数,再判断LRU时间、
- 第三类:全部数据可能都被淘汰
- allkeys-lru
- allkeys-random
- allkeys-lfu
和volatile的处理一样,区别是 ”所有缓存“ 而非”部分过期缓存“
缓存热点#
Q: 什么是热点Key问题?#
A:
热点问题产生的原因大致有以下两种:
用户消费的数据远大于生产的数据(热卖商品、热点新闻、热点评论、明星直播)。
在日常工作生活中一些突发的的事件,被大量刊发、浏览的热点新闻、热点评论、明星直播等,这些典型的读多写少的场景会产生热点问题。
危害:
- 请求分片集中,超过单Server的性能极限。
- 在服务端读数据进行访问时,往往会对数据进行分片切分,此过程中会在某一主机Server上对相应的Key进行访问,当访问超过Server极限时,就会导致热点Key问题的产生。
- 流量集中,达到物理网卡上限。
- 请求过多,缓存分片服务被打垮。
- DB击穿,引起业务雪崩。
Q: 如何发现热点?#
- 最简单的方式,是提前配置热点key,需要运营人员提供相关数据。
- 或者搭建有自身业务特点的热点自动发现平台, 通过分析日志得到热点key,及时更新热点保护。
- client->Proxy->redis的proxy层做收集上报,其实类似于上面的自动发现收集。
发现动态热点数据
秒杀系统之发现动态热点数据 - redis自身有个monitor命令, 可以抓取收到的命令,收集上报热点key。
Q: 如何解决热点问题?#
识别到热点后就是处理策略了。
- 升级为本地缓存,也就是redis前置服务增加jvm内部缓存,只针对部分热点key。
- 紧急扩容redis缓存(但是扩容需要过程,还涉及预热同步主节点数据问题)
- 拆分key分散到更多其它缓存节点避免单节点瓶颈**(redis单节点一般10w qps)**, 即单独对这个热点key添加新的分片算法,分到其他本不属于的redis上。
换句话说, 根本解决方式就是及时进行缓存的扩容。 有种办法是重写redis的访问机制,将slave节点也用上,实现读写分离。
redis有个客户端lettuce,可以开启cluster模式下的读写分离, 水平扩容slave节点来无限延申系统容量。
热点Key问题的发现与解决
Q: 如何删除热点?#
A:
然后就是删除的问题,,保证最终一致性即可,如果是本地缓存可以用MQ广播消息+超时过期的策略,当然还有些极端情况的不一致可以考虑延迟双删和binlog异步刷新
Q: 如何利用redis 实现秒杀系统?#
数据一致性#
Q: 当需要删除数据时, 如果我先删缓存,再删数据库,可能会有什么问题?#
A:
删完缓存,业务代码准备去删数据库时, 另一个请求打到redis这,发现不存在,于是另一个处理线程去数据库中取出了数据,并加载到了缓存中。
这导致了缓存删除了个寂寞。
核心原因是因为业务代码的 删库和读-加载操作是支持并发执行的。
- 因此应该先删数据库, 再删缓存, 这样能确保不会把脏数据重新加载到内存中
Q: 网络通信正常、命令正常的情况下, 先删库 ,再删缓存, 还是有可能造成脏数据, 知道为什么么?#
A:
这种情况一般是”读缓存过期“导致的。
即正好某个key的读缓存过期,被删除。
然后查询请求过来, 决定查库并加载到缓存中。
此时又正好发来一个删除请求, 删库+删缓存, 然后又被上面的请求给重新加载了。
但是一般不考虑, 因为 正好过期+ 正好删除请求 + ”先删库->查询缓存->删缓存->加载缓存的顺序“ 这种概率是非常低的。
Q: 如果删了库之后, 再删缓存的途中,网络临时不通怎么办?那缓存也有可能一直脏着了。#
A:
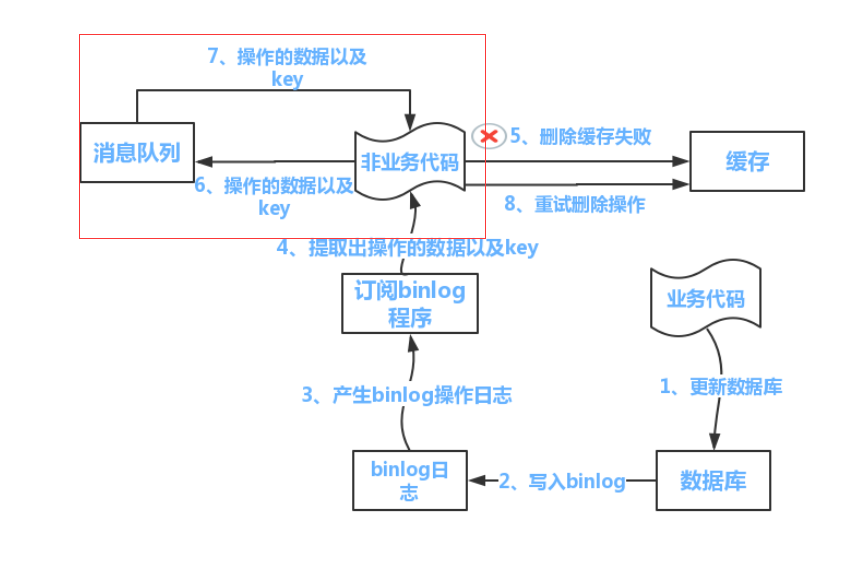
失败的话,放入一个消息队列。 搞一个定时线程定期取消息队列中的消息进行处理。
为了减少业务代码耦合, 弄一个独立的缓存更新程序, 专门从binlog中拿更新消息进行同步。