- Q: 处理微服务治理时,为什么大多采用rpc而非restful做服务间调用?
- Q: 服务A 调用服务B时, 如果超时了, 应该怎么处理?
- Q: 服务发现有哪两种模式?
- Q: zookeeper作为注册中心有什么缺点?
- Q: 有什么办法解决上面的问题?
- Q: 服务调用的互相、循环依赖问题如何解决? 即A服务启动依赖B服务某接口, B服务启动A服务某接口的时候
- Q: 做一个服务调用链的话, 一次请求需要包含哪些信息?
- Q: 调用链跟踪有哪些时间信息需要统计?
- Q: 怎么在接收和发出时, 能用到同一个traceId?
- Q: 所有调用链信息直接写入数据库吗?
- Q: 有哪些实现方式(代码如何实现),对于微服务而言?
- Q: 如何实现一个全局服务的定时任务管理?如何设计? 即如果你们希望做定时任务的话,会怎么做?
[toc]
Q: 处理微服务治理时,为什么大多采用rpc而非restful做服务间调用?#
A:
- restful大多基于json做序列化, 相比于直接做二进制序列化,性能较差。 而服务间调用频率往往非常高,必须做到低时延。
- 常见的rpc框架往往能封装好底层网络通信协议、寻址、序列化问题, 通过一个proto文件即可生成 客户端代码和服务端代码, 大大简化开发工作。
Q: 服务A 调用服务B时, 如果超时了, 应该怎么处理?#
A:
要分情况。
- 如果是读服务,可以做failover重试, 重试3次才报失败。
- 如果是写服务, 考虑到幂等性,不应该做重试,直接报错。
- 如果是耗时较长的接口, 如果超时时间设的太短,则可能因为重试引发雪崩(大量该接口调用都发生连锁超时), 因此不应该采用重试。
常见的超时处理操作和情况:
- 重试——读操作
- 失败就立刻报错——非幂等的读操作
- 出现异常直接忽略——用于审计日志写入和读取等不重要的操作
- 失败自动恢复,定时重发——用于重要消息通知等操作
Q: 服务发现有哪两种模式?#
A:
-
服务端服务发现模式
提供路由服务route, 由路由服务帮客户端做服务发现和负载均衡调用, 路由服务和注册中心相连接
缺点: 代理中心额外要引入容错性和伸缩性,成本比较大。 且性能上服务也较差。 -
客户端服务发现模式,
客户端和注册中心相连接, 获取发现服务地址,自己处理多地址的负载均衡等策略。
Q: zookeeper作为注册中心有什么缺点?#
A:
- 服务扩容时, 应用启动缓慢
- 冗余的服务配置项会增加存储压力, 扩大网络开销
原因:
ZK是一个典型的CP系统, 基于ZAB原子广播的强一致性中间件, 写操作存在单点问题,无法通过水平扩容来解决。 当客户端发送写请求时, 集群中的其他节点会优先转发给leader节点, leader节点来做具体的写操作。 只有N/2+1个以上的节点都同步成功, 写才算完成。
服务扩容的时候, tps越高, 服务注册写入效率月底, 导致上游大量请求排队, 服务启动和配置下载变得缓慢。
Q: 有什么办法解决上面的问题?#
A:
- 增加zk的observer节点。 因为observer节点不会增加写入开销,但可以分担带宽压力。
- 注册项精简, 只写入关键配置, 其他配置放到另外的元数据中心,实现配置垂直分离。
- 去除zk的强一致性, 自研一个最终一致、增量数据返回、去中心化的分布式注册中心。
Q: 服务调用的互相、循环依赖问题如何解决? 即A服务启动依赖B服务某接口, B服务启动A服务某接口的时候#
A:
尽量避免循环依赖, 调用流上要设计成单项依赖
如果确实存在, 要避免开启强制的check服务开关, 不去校验依赖服务是否通,而是启动后定时轮询。
Q: 做一个服务调用链的话, 一次请求需要包含哪些信息?#
A:
traceId, 表示这是哪一次请求的完整跟踪
spanId, 中间某次服务调用的请求/响应过程
parentSpanId, 上一次调用的id, 用于确定请求依赖关系
xxxConetext: 包含更多详细的信息, 例如是否是服务调用/提供方, host、port、接口名,被调用的服务方法名。
Q: 调用链跟踪有哪些时间信息需要统计?#
A:
以一次span为例, 需要记录
Client SendTime 客户端刚发出的时间CS
Server ReciveTime 服务接收请求时间SR
Server Send Time 服务发送响应时间SS
Client Receive Time 客户端接收响应时间CR
- 服务调用耗时= CR - CS
- 服务处理耗时= SS - SR
- 网络开销总耗时= 服务调用耗时 - 服务处理耗时
- 前置网络耗时 =SR-CS
- 后置网络耗时 = CR - SS
Q: 怎么在接收和发出时, 能用到同一个traceId?#
A:
使用threadLocal即可, 从该线程中拿到这个traceId变量值,用完销毁。
Q: 所有调用链信息直接写入数据库吗?#
A:
不可以, 容易对数据库造成较大压力, 应该放入消息队列进行消费, 实现削峰的效果
Q: 有哪些实现方式(代码如何实现),对于微服务而言?#
A:
一种看框架本身是否支持相关的filter,继续配置, 例如dubb的filter
或者自己写动态AOP, 例如利用-javaagent 实现动态的jvm增强需求。 实质上利用了jdk1.5引入的Instrumentation接口
Q: 如何实现一个全局服务的定时任务管理?如何设计? 即如果你们希望做定时任务的话,会怎么做?#
A:
- 方案一:
可以借助注册中心实现定时任务管理。
- 服务自身维护需要的定时任务接口、定时触发条件。 可以自定义注解设置在接口上。
- 然后通过注册动作将接口以及接口上的注解发布给注册中心。
- 注册中心将定时类接口呈现给 注册中心服务的定时任务管理页。
- 当到达时间, 注册中心调用定时任务接口,触发动作。 如果需要关闭,在管理页直接关闭即可。
- 当服务的定时任务接口返回了已卸载或者不存在的接口时, 注册中心要删除这个定时任务,不再呈现在页面上。
一个简单的定时任务调度中心设计方案
当时我自己服务里没有这种功能的注册中心, 实现起来的接口开发量还是比较大的。
- 方案二:基于数据库锁quartz
当多个server的定时任务到时间时, 先去抢锁表里该任务的悲观锁,如果抢到了就执行, 如果抢不到就等待。当重新拿到锁后,发现该定时任务已经被设置成“完成”,时间也对的上,于是就不再执行了。
缺点: 集群特性对于高CPU使用率的任务效果很好,但是对于大量的短任务,各个节点都会抢占数据库锁,这样就出现大量的线程等待资源。这种情况随着节点的增加会越来越严重。
另外,quartz的分布式只是解决了高可用的问题,并没有解决任务分片的问题,还是会有单机处理的极限,即某台机器执行过多的定时任务导致负载暴涨,而其他的机器一直凑巧没抢到。
- 方案三: 引入支持任务分片的分布式任务调度框架
- elastic-job (当当)
- TBSchedule(淘宝)
- Saturn(唯品会)
默认的分片策略,作业数能被服务器数整除情况下均匀分配:
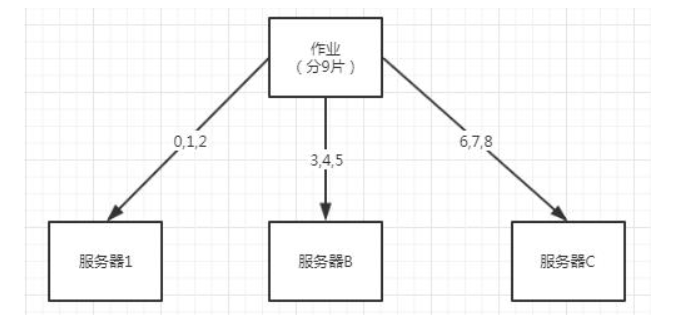
根据哈希的分片策略:
根据作业名的哈希值奇偶数决定采用IP升/降序算法实现分片,作业名的哈希值为奇数则IP升序,作业名的哈希值为偶数则IP降序,通过这种方式用于将不同的作业分片负载均衡至不同的服务器。
如作业名哈希值为偶数,则采用IP降序算法实现分片,这样就避免了采用平均分配算法时IP地址靠后的服务器空闲的问题。
Q: 有哪些负载均衡算法?
A:
-
ActiveWeight / LeastActive :低并发度优先, 统计某时刻的被调用 call 数越小优先级越高。即根据短时间内被调用数获取。需要统计的成本,实现难度比较高,存在耦合。
-
Random :随机,按权重设置随机概率。在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。节点少的时候,随机有可能出现连续都随机到一个节点上,导致负载不均衡。
-
RoundRobin :轮循,按公约后的权重设置轮循比率。
存在慢的提供者累积请求问题,比如:第二台机器性能很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。 -
LocalFirst :本地服务优先获取策略。
-
Consistent :一致性 Hash ,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
Q: 负载均衡时,请求失败怎么办?
A:
-
Failover :失败自动切换,当出现失败,重试其它服务器。
通常用于读操作,但重试会带来更长延迟。 -
Failfast :快速失败,只发起一次调用,失败立即报错。
通常用于非幂等性的写操作,比如新增记录。 -
Failsafe :失败安全,出现异常时,直接忽略。
通常用于写入审计日志等操作。 -
Failback :失败自动恢复,后台记录失败请求,定时重发。
通常用于消息通知操作。 -
Forking :并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。
-
Broadcast :广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。