[toc]
资源调度#
1 k8s资源模型#
Node是资源的提供者,Pod是资源的使用者。
Node能提供三方面资源:
- 计算资源(CPU\GPU\内存)
- 存储资源(磁盘、其他介质)
- 网络资源(贷款、网咯地址)
CPU是可压缩资源,资源不足时pod只会变慢
内存是不可压缩资源,资源不足时pod会被杀死。
1Core = 1MillCores, 因此0.5核有时也写成500m
2 服务质量和优先级#
对于资源,k8s中给出了request和limit两个设置下。
request是供调度器使用,k8s选择节点部署pod时,根据request决定
limit是给cgroups使用,k8s向cgroups传递资源配额时,按limit设置
设计理念是 用户提交工作负载设置的资源配额,并不是容器调度必须严格遵守的之,往往实际使用的都远小于所请求的。
但为了避免总是按最大申请, 引入了pod驱逐机制。
如果有多个pod要驱逐掉其中1个, 则需要服务质量等级和优先级。
- 服务质量等级:Guaranteed(数据库等重要应用)、Burstable、BestEffort。
- 优先级:管理员自行决定(priorityClass), 多个pod被调度时,高优先级的pod会优先被调度。如果是杀死pod时,从低优先级开始杀
3 驱逐机制#
有两种pod的驱逐机制:
- 软驱逐:例如低于可用内存20%时,先观察一段时间,如果能恢复说明只是抖动,如果持续低则会进行pod优雅退出(先清理、落盘再结束pod)
- 硬驱逐:例如低于可用内存10%,则立刻结束pod且不会优雅退出
为了避免重复调度到刚才资源不足的节点上,还会有一个k8s参数用来约束调度器,多久内不能把pod调度到刚才的节点上。
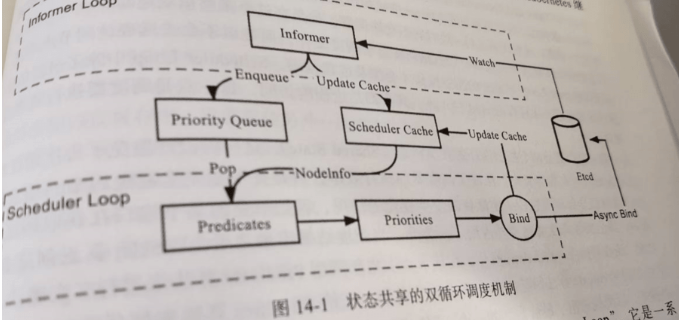
4 调度器原理#
- informer loop:持续循环监控etcd中关于pod和node的资源变化情况,将资源变化封装后发送给调度队列和调度缓存。
- scheduler Loop: 不断循环从上面的队列中取数据,并使用过滤代码进行过滤,可根据cpu、磁盘卷、节点状态进行过滤,然后再根据排序策略决定最终可以用哪些节点用来调度最新pod。