[toc]
流量治理#
1 服务容错#
1.1 容错策略#
文章中介绍了故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用、广播调用等几种容错策略,我用表格的形式直观呈现一下这几种策略的区别,方便理解和选型:
| 容错策略 | 介绍 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 故障转移Fail-over | 服务出现故障时,自动切换到其他服务副本获取结果 | 系统自动处理,调用者不感知第一次失败 | 会增加调用时间,在有超时时间的限制下即使第二次调用成功也会造成超时。 | 调用幂等服务(可支持多次调用),对调用时间不敏感 |
| 快速失败Fail-fast | 出错的话就直接报错抛异常给调用者自行处理。 | 调用者对失败的处理完全自主可控。 | 调用者必须处理增加了开发成本,不可以随意外抛。 | 调用非幂等的服务,超时阈值比较低(因此不允许失败后做其他的处理)的情况 |
| 安全失败fail-safe | 不抛异常,只记录日志 | 不影响主链路逻辑 | 只适合旁路调用。 | 调用链中的旁路服务 |
| 沉默失败fail-slient | 失败后暂停一段时间服务,避免引起服务间雪崩 | 控制错误避免影响全局 | 出错的地方可能会在一段时间内不可用 | 容易引发频繁超时的服务 |
| 故障恢复 fail-back | 调用失败后,把错误放入一个异步队列,延迟恢复。 | 自动重试且不会容易引发超时,也不影响主路逻辑 | 重试任务如果短时间内堆积过多,也会造成重试失败或者超时 | 调用链中的旁路服务,对实时性要求不高的主路服务。 |
| 并行调用forking | 一开始就对多个服务副本发起调用,只有有任何一个返回成功,就宣告成功。会额外消耗资源可能大部分都是无用调用,适合资源充足且对失败容忍度低的高敏感场景 | 能够快速获得响应,提高系统的吞吐量 | 可能会浪费大量的资源 | 适合资源充足且对失败容忍度低的高敏感场景 |
| 广播调用broadcast | 一开始就对多个服务副本发起调用,必须所有都返回成功才宣告成功,常用语刷新分布式缓存。只适合批量操作的场景,失败概率高。 | 能够同时快速更新多个副本的状态,提高系统的数据更新速度 | 失败概率高 | 只适合批量操作的场景,例如刷新分布式缓存等 |
1.2 容错设计模式#
1.断路器模式#
即服务中发请求的地方都通过一个断路器模块来转发发送
当10秒内请求数量达到20,且失败阈值达到50%以上(这些参数都可以调整), 则认为出现问题, 于是主动进行服务熔断, 断路器收到的请求自动返回错误,不再去调用远程服务, 这样可避免请求线程各种阻塞,能及时返回报错。
中间会保持有间隔的重试直到恢复后,关闭断路。
2.舱壁隔离模式#
如果一个服务中,可能要同时调用A\B\C三个服务,但是却共用一个线程池。
如果调用C服务超时,而调用C的请求源源不断打来,会造成C服务的请求线程全在阻塞,直接把整体线程池给占满了,影响了对A\B服务的调用。
一种隔离措施是对每个调用服务分别维护一个线程池。缺点是额外增加了排队、调度、上下文切换的开销,据说Hystrix线程池如果开启了服务隔离,会增加3~10ms的延迟。
另一种隔离措施是直接自己定义三个服务的计数器,当服务线程数量到达阈值,自动对这个服务调用做限流。
3.重试模式#
故障转移和故障恢复这2个策略一般都是借助重试模式来处理的,进行重复调用。
重试模式应该满足以下条件才能使用:
- 仅在主路核心逻辑的关键服务上进行同步的重试, 而非关键的服务
- 只对瞬时故障进行重试,对于业务故障不进行重试
- 只对幂等型的服务进行重试
重试模式应该有明确的终止条件,例如:
- 超时终止
- 次数终止
重试一定要谨慎开启, 有时候在网关、负载均衡器里也会配置一些默认的重试, 一旦链路很长且都有重试,那么系统中重试的次数将会大大增加。
2 流量控制#
流量控制需要解决以下3个问题
- 依据什么指标来限流
- 如何限流
- 超额流量如何处理
2.1 流量统计指标(依据什么指标来限流)#
- 每秒事务数TPS: 事务是业务逻辑上具有原子操作的业务操作,对于对买书接口而言, 买书就是一个事务, 背后的其他请求是不感知的。
- 每秒请求数HPS: 就是系统每秒处理的请求数, 如果1事务中只有1个请求, 那么TPS=HPS, 否则HPS>TPS
- 每秒查询书QPS: 是一台服务器能够响应的查询次数。 对于单节点系统而言,QPS=HPS,对于一个分布式系统而言HPS>TPS
通过限制最大TPS来限流的话,不能够准确反映出系统的压力, 因此主流系统倾向使用HPS作为首选的限流指标。
2.2 限流设计模式(如何限流)#
流量计数器模式#
统计每秒内的请求数是否大于阈值
缺点:
- 每秒是基于1.0s-2.0这样的区间统计, 但如果是0.5-1.5 和1.5-2.5分别超出阈值,但是1.0-2.0没有超过阈值,则会出现问题。
- 每秒的请求超过阈值,也不代表系统就真的承受不住,导致五杀
滑动时间窗模式#
滑动时间窗专门解决了流量计数器模式的缺点。
准备一个长度为10的数组,每秒触发1次的定时器
①将数组最后一位的元素丢弃,并把所有元素都后移一位,然后在数组的第一位插入一个新的空元素
②将计数器中所有的统计信息写入第一位的空元素
③对数组中所有元素做统计,清空计数器数据
可以保证在任意时间片段内,只通过简单的调用计数比较, 控制请求次数不超过阈值
缺点在于只能用于否决式限流, 必须强制失败或者降级,无法进行阻塞等待的处理。
漏桶模式#
漏桶和令牌桶可以适用于阻塞等待的限流。
漏桶就是一个以请求对象作为元素的先入先出队, 队列程度等于漏桶大小,当队列已满拒绝信的请求进入。
比较困难的原因在于很难确定通的大小和水的流出速度,调参难度很大。
令牌桶模式#
每隔一定时间,往桶里放入令牌,最多可以放X个
每次请求消耗掉一个。
可以不依赖定时器实现令牌的放入,而是根据时间戳,在取令牌的时候当发现时间戳满足条件则在那个时候放入令牌即可
2.3 分布式限流#
前面的4个限流模式都只是单机限流,经常放在网关入口处,不适用于整个服务集群的复杂情况,例如有的服务消耗多有的服务消耗少,都放在入口处限流情况其实很多。
可以基于令牌桶的基础上,在入口网关处给不同服务加不同的消耗令牌权重,达到分布式集群限流的目的
总结#
流量治理技术对云原生场景的重要性#
以上主要介绍了服务容错和容错设计模式,涉及到不同的容错策略和容错设计模式,如故障转移、快速失败、安全失败、沉默失败、故障恢复、并行调用和广播调用。
这2个设计可以保证系统的稳定性和健壮性。这篇文章涉及的话题与云原生服务息息相关,因为云原生应用程序之间会频繁通过进行请求和交互,需要通过容错和弹性来保证高可用性。
因此,对于那些希望使用华为云的云原生服务的人来说,这篇文章提供了很好的指导,让他们了解如何通过容错来保证他们的服务的可用性和稳定性。
华为云如何在流量治理中体现作用#
如果能通过将服务API注册到华为云提供的APIG网关上,似乎能够很方便地达成上述2个设计。
比如APIG支持断路器策略,是API网关在后端服务出现性能问题时保护系统的内置机制。当API的后端服务出现连续N次超时或者时延较高的情况下,会触发断路器的降级机制,向API调用方返回固定错误或者将请求转发到指定的降级后端。当后端服务恢复正常后,断路器关闭,请求恢复正常。APIG-断路器策略
同时APIG还提供了流量控制策略,支持从用户、凭据和时间段等不同的维度限制对API的调用次数,保护后端服务。支持按分/按秒粒度级别的流量控制,阅读了上文中提到的几个流量策略,再去看APIG里配置的流量策略值,则会很容易理解。APIG-流量控制策略
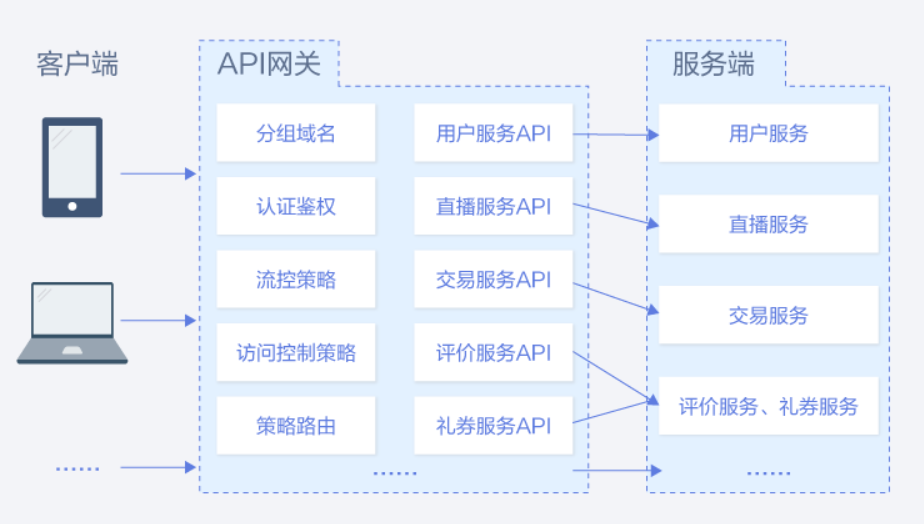
可以看到对于这些常见的经典服务设计策略,无需再重复造轮子,使用已有云服务,可以很快地实现相关功能,提升产品的上线速度和迭代效率。