[toc]
查询为什么会慢?#
- 查询的生命周期
客户端发送->服务器接收->服务器解析sql->生成执行计划->执行->返回结果
其中最耗时的就是执行了。 - 查询执行时耗费的时间:
- 网络
- CPU计算
- 生成统计信息
- 锁等待
- IO操作
应用逻辑上处理低效查询#
应用层逻辑上,是不是返回了太多会被自己抛弃的数据#
这个主要和 返回的数据有关
- sql里写的是返回所有行, 却在代码里只取resultSet的前10行。
- sql里写的是返回select *, 代码里却只需要特定几列。
- 每次查询肯定是相同的结果,却没有做缓存。
mysql中,是否在扫描额外的记录#
这个主要和查询的过程有关(返回的数据已经优化到最优了)
- 扫描的行数/返回的行数的比值越小越好
- EXPLAIN分析中有几个type,从坏到好分别是
- 全表扫描All
- 索引扫描ref
- 范围扫描
- 唯一索引查询
- 常数引用
EXPLANIN里会显示扫描的行数row, 你可以和返回的行数做对比
- mysql中有3种方式来使用where条件,从好到坏分别是
- 在索引中直接做where判断来过滤,然后返回底层数据,这个需要在存储引擎层完成
- 索引覆盖扫描,直接在索引中返回数据,没有走到底层的数据处,这个在服务器层完成即可,不用走到底层存储引擎
- 先从存储引擎返回数据, 然后再在服务器层做where判断来过滤
- 为了减少扫描的行数,常见优化方式:
- 使用索引覆盖扫描
- 使用汇总表(就是每次做一些操作就会触发更新,不要再去重复查询了)
- 重写复杂查询(联结等)
重构查询语句#
limit切分查询#
- 指的是用limit等分页手段来切分,分多次执行
- 适用于一些可能会锁表的大批量操作。
- 比如删除某10w条数据, 最好先查询+limit 1w,分10次执行,中间间隔一些时间, 避免长时间的锁表。
关联查询(join)分解#
- 如果一个语句中join多次, 看下能不能在应用层分3个select依次执行,每次取前一次select的结果加入自己的条件中
- 好处:
- 分解后条件变简单了,就有可能利用mysql的缓存。
- 也因为条件变简单且是单表,可能会利用上索引
- 减少锁的竞争
- 每个表相当于只查询了一次, 减少了重复访问。
优化In查询#
1 | select * from a where id in (select id from b where b.xx<y) |
注意上面并不是先计算in子表返回的内容,然后作为条件去做检查
而是变成一个关联查询
select * from a where exist(select * from b where b.xx<y and a.id=b.id))
会先对file表做全表扫描,然后再进行条件查询。这这会很慢
- 改进:
- 用inner join改写成内联
- 用GROUP_CONCAT生成一个列表,再提供给IN去使用。
P 224-225
优化UNION加limit#
(select …) UNION ALL (select …) limit 20
这句话本质上会把需要联合的表全部取出,做合并之后,再limit,如果表很大,limit相当于没有他本该的作用。
可以改成 在内部都加上一个limit来减少union时的量
索引合并优化#
等值传递#
IN()列表可能会被复制到关联的各个表中, 列表很大就会导致执行变慢
并行执行?#
mysql都是单线程进行查询
哈希关联#
- mysql不支持哈希关联, 关联都是通过 嵌套循环关联的。
- 除非用之前提过的自定义哈希索引部分(弄一个触发器来生成哈希索引)
松散索引扫描#
指没有用到第一列索引,却需要用第二列索引时,按照下面的方式去查:
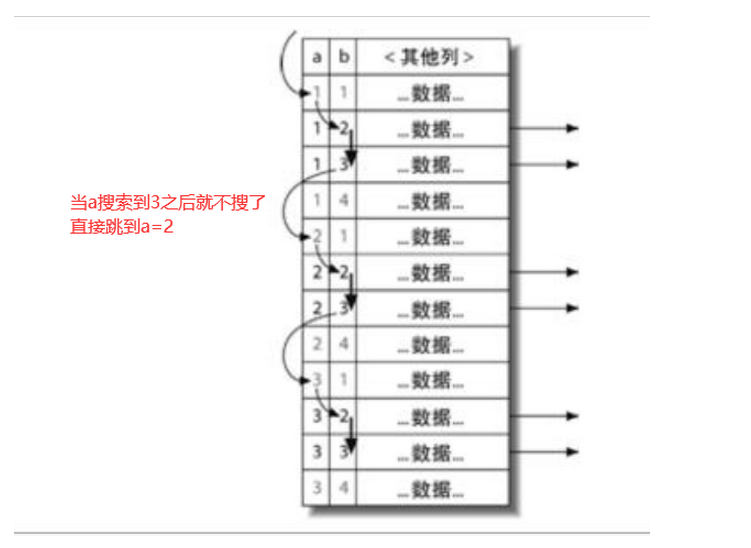
select * from xxx where B = xxx group by A;
添加 group by 字段后,会先根据 A 索引分组后,会在每个 A 的范围内使用索引进行快速查询定位所需要的 B 列,这就叫做松散索引扫描,比新建一个索引的效率会慢 A 的 distinct 倍,但省去了新索引的消耗
最大和最小值优化#
如果你MIN()的是主键,且where中没有用到索引, 那么MYQL就进行全表顺序扫描。
扫描时按理应当满足第一个可行的值时,就是最小值(主键按顺序排列)
但是mysql不支持。
可以用limit 1来优化,不要用MIN或者MAX, 如果你要统计的是主键的值的话。
同表查询和更新#
mysql不允许 在同一张表进行查询和更新

优化Count()#
- count(列或列的表达式) 会过滤掉无值或者null的情况。 而count(*)直接统计所有行数
- count(*)的性能好一点, 因为他不用过滤和比较是否为空,可以直接用存储引擎记录的一些信息直接得到。
- count(*) 不带where非常快, 如果带了where,就要遍历。
- 一种优化: 如果统计where id>5, 而id>5很多,<5却很少,可以反向求接,改成
select (select count() from city) - count() from t where id < 5。
毕竟不带where的是很快的。 - 如果对计数要求不是那么精确, 可以用汇总表去处理总和的问题,每隔一段时间更新一次。
- 注意这种用法
select count(color=‘blue’ OR NULL) AS bule, count(color=‘red’ OR NULL) as red from items;
可以求红色和蓝色的个数并展示在同一行中,无需分组。
关联查询优化#
- 确保ON或者USING的列上有索引
- 如果B join A, 那么A上有索引足够了。因为联结是是遍历B的每一行,拿B的joinKey 去A里面搜索,所以真正用到的是A的索引(除非执行计划做了优化)
- 优化GROUP BY 或者DISTINCT
Group by优化#
- 分组时,要么利用文件要么利用内存做临时表,你可以用优化器的提示去控制用内存还是文件
- join后再分组, 分组里的列尽量用join的key, 比如你虽然是要按名字分组并栈式的,但名字和id是一一对应的,所以按id分组并展示名字是ok的
- 不要用分组去展示非分组列(即不是聚合结果也不是分组列)
- 分组时,会自动对分组后的结果按分组列排序,消耗一定时间。 如果不希望排序,可以加一个ORDER BY NULL
优化LIMIT分页#
- 对于“LIMIT 100000,10” 里面存在100000的偏移,而偏移本质上得扫描掉前面的100020条记录。
- 有3种优化方式:
- 构造一个联结临时表,临时表里做索引覆盖查询+limit(即select的只有limit列),然后再拿得到的id做联结,获取你需要的列。
- 如果确定是某个limit的范围,且为索引,则用where 索引范围来代替
- 或者where xx<100020 ORDER BY XX DESC LIMIT 20来反向求。
如何知道是否有下一页?分多少页?#
- LIMIT的时候加上SQL_CALC_FOUND_ROWS。这样会返回除去LIMIT之外的其他行数,相当于剩下还需要的行数。
- 每次LIMIT X+1, 应用层只拿X行, 如果有多一行,说明还有下一页
- 每次LIMIT 10X, 然后10X作为缓存,应用层每次取X作为一页展示。
优化UNION#
- UNION的本质是创建并填充临时表
- 用UNION ALL, 否则会默认加上DISTINCT关键字进行唯一性检查,消耗性能
使用自定义变量优化#
见6.4自定义变量
用特殊关键字控制执行计划#
- High_Priority/low_priority
多个语句同时操作一个表时, 可以用这个来控制语句的优先级。 - Delayed
对插入和更新操作而言, 他会直接返回响应给客户端,然后把数据缓存下来,等服务器空闲了再去插 - Straight_join
可以用这个关键字控制 join顺序,而不是用优化器的join顺序 - SQL_small_result
告诉优化器 结果集很小,你可以搞个内存临时表做排序 - SQL_big_result
告诉优化器 结果集很大, 可以提早准备磁盘排序而不是等发现不够了采用磁盘。 - SQL_CACHE
结果集是否应该缓存。 - SQL_CALC_FOUND_ROWS
让返回的结果集包含更多信息(例如limit 10,结果集里却有个总数信息) - For update / Lock in share ode
提示优化器加行锁 - Use/ignore/force Index
- 告诉优化器要不要用索引,如果是force,即使where里没有索引,也会去用索引。 如果是ignore,则就是不用,傲娇
- optimizer_search_depth
dfs搜索计划时的最大深度 - optimizer_prune_level
根据扫描的行数来决定是否跳过执行计划? - optimizer_switch
选择是否关闭某些优化器特性