[toc]
索引的基本概念#
索引的优点#
- 大大减少服务器需要扫描的数据量(本来O(n)的扫描,在B-Tree或者哈希索引的帮助下, 变成O(logn)或者O(1))
- 避免了不必要的排序或者临时表(order by和排序需要先弄一个临时存储的表)
- 把随机IO改成为了顺序IO,IO速度加快
索引类型#
- 支持的类型
- 全值匹配——key中所有索引列全部匹配中,单个的
- 匹配最左索引——匹配key中的第一个索引值
- 匹配列前缀——可以只匹配某个索引的前缀(适用于字符串的情况)
- 可以匹配最左索引+列前缀——可以只匹配 索引1、索引2加上索引3的前缀。
- 注意上面的匹配,都是从左往右的匹配, 因此不支持只匹配中间那个索引的情况。
- 如果有一列索引用了范围, 那么后面的列都不能再用来匹配了。
- B-Tree也可用于排序或者group by key,会加快速度,毕竟默认都是排好序的了。
哈希索引#
- 指的是把 索引列计算出一个哈希值, 存到一个哈希表中, key是哈希值,val是行指针。
- 只有Memory引擎支持(key using hash(索引值) ), inndb不支持。
- 因为不是按照顺序存的, 所以不可用于优化排序, 只能优化查询。
- 不支持部分索引匹配, 因为哈希值是根据全索引计算的。
- 也不支持范围。
- 如果有哈希冲突,且很多,就可能造成性能变慢,
自定义哈希索引#
- 可以利用B-tree弄一个自定义的哈希索引
- 例如想哈希的列是url, 于是我弄了一个hash_url的列, 里面的值是url经过CRC32(url)后的值, 然后把hash_url这一列作为索引。
- 然后select语句的时候, where url = ‘xx’ and hash_url=CRC32(‘xx’) ,即可 快速定位。
- hash_url的值可以通过insert触发器,每次插入url的时候进行更新
- 查询时必须带上哈希前原本的值(就是上面的url = ‘xxx’),否则可能会因为哈希冲突返回多行。
- 不可用SHA1和MDK做哈希函数。
空间数据索引(R-Tree)#
- 只有MyISAM才支持
- 从所有维度来索引数据,用于地理信息存储之类的
全文索引#
- 查找文本中的关键词
- 可以同时创建全文索引和基于值的B-Tree索引
三星索引的评价#
- 一星:需要拿的记录都放到同一行(即不用再关联其他表)
- 二星:索引数据顺序和查找顺序一致
- 三星: 索引的列包含了查询中需要的全部的列(即不用去返回行中所有顺序,直接返回key就好了)
索引原理#
B+ tree实现#
- 如果没有指明类型,基本上都是用的B+ tree索引
- B+ tree结构
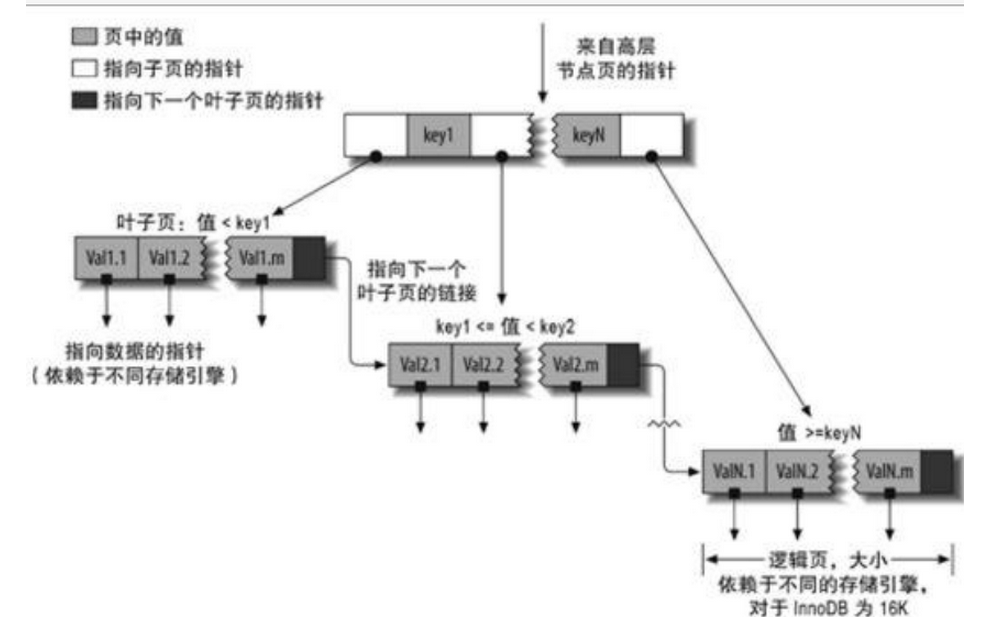
里面的key就是 你选定的索引值
然后按照范围,指向后面其他的范围,直到定位到具体的叶子节点即行所对应的值。
同时因为最后叶子都是按照顺序连起来的,所以也很适合按照范围返回数据。
- B+tree里的key可以包含多个列的值, 并且这些列匹配时有顺序关系,按照定义key时的优先级来排序。(就是说可以多个key组成一个节点,里面自定义了对应的判定顺序)
Q: 为什么不选择使用B树, 而是使用B+树?#
A:
数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题
正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历
在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作,或者说效率太低。
另外B树的索引节点上也存了数据,导致搜索过程种读了很多不必要的数据,加大了磁盘IO时间
Q: 那为什么不选用红黑树?#
A:
红黑树往往出现由于树的深度过大。
磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写
Q: 那为什么不用哈希表?#
A:
哈希表没法做范围查询以及前缀索引匹配查询。
高性能的索引策略#
独立的列的问题#
- 索引列不可以作为表达式的一部分, 必须是独立的
例如 where id+1=5 或者 where Func(id) < 5 都是错误的
应该改成
where id = 5-1 或者 where id < uFunc(5)
前缀索引优化#
- 索引列如果是text之类特别长的,必须使用前缀索引, 不可以用完整长度去做索引,mysql不支持。
前缀索引的创建#
… KEY(city(7)), 那么你按照city去where时,就会用city的前缀去索引了。
确定前缀长度#
- 前缀索引的选择性 = 不重复的个数/记录总数
- 如何确定较优的前缀长度?
全列选择性:
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
某一长度前缀的选择性:
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;
当你不断调整prefix_length,让前缀的选择性越接近全列选择性的时候,索引效果越好。如果发现继续增加prefi_length,变动幅度不大了,则选取那个值
- 也要注意前缀最大值, 例如该长度n下,平均选择性不高,但是有1-2个前缀数量特别大,也不行。
如何做后缀索引?#
存储的时候把字符串 翻转 存进表里,然后再做前缀索引
多列索引#
- 多列索引指的是 多个独立的索引。就是给表定义了Key(a), key(b) , 而不是Key(a,b)
- 如果在多列索引的情况下,要where a=1 or b= 2, 且要性能好, 需要改成 union(a,b) 即查询union的形式。 mysql5.0之后都会优化成union, 简称 索引合并
- 上述默认优化的缺点: 联合操作会耗费大量的CPU和内存。 可是统计时间时又不会统计进来,导致低估时间成本。
- 可以通过explanin sql语句, 查看extra中是否有using union(a,b)来判断是否有索引合并的情况
如何确定索引列顺序#
- 这里指的是如何确定key(a,b,c)里abc的顺序
- 通用法则:把选择性最高的那个列放前面
- 选择性计算: distinct(列)/count(*) 越大,选择性越好。
- 因为这样的话,可以减少在叶子节点上的遍历。
- 特殊情况: 某场景下突然表里的username都变成了一样的用户名, 然后对username索引做查询时, 就很慢, 因为相当于在叶子节点上遍历去查了,O(n)的复杂度。
- 对于特殊场景,要尽量在数据输入避免, 或者查询避免(例如避免在那个时间段去查询那个统一的username)
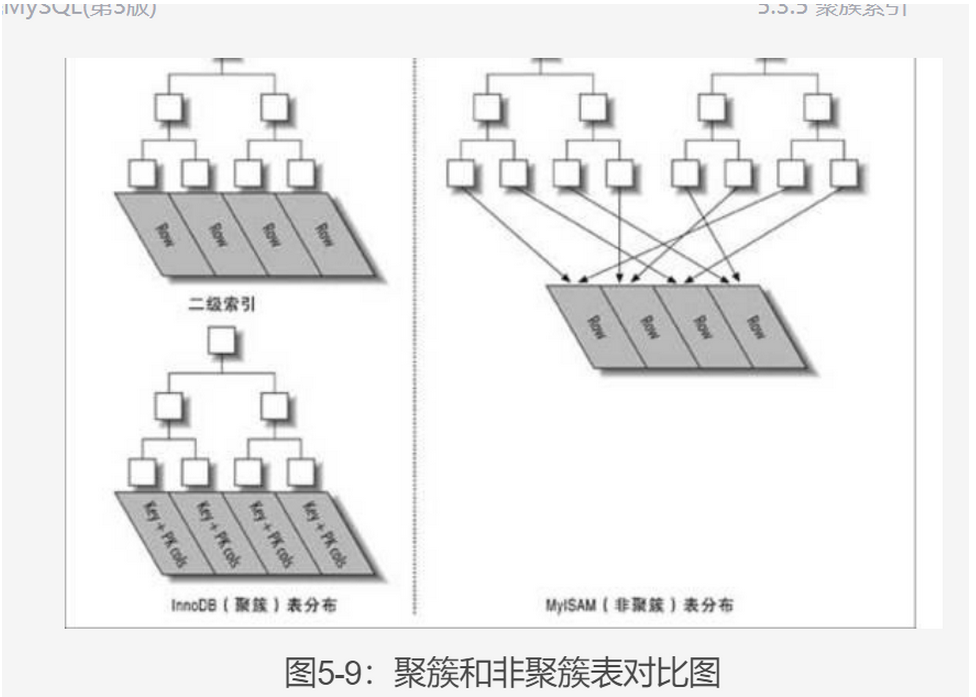
聚簇索引#
- 聚簇索引是一种存储结构,而不是索引类型。
- InnoDb默认使用主键列做聚簇索引
- 如果没有主键,则用第一个非空not NULL unique的索引作为聚簇索引
- 如果没主键没索引,则会创建一个隐藏的行id作为聚簇索引(毕竟他总要搞一个B+树)
聚簇和非聚簇的区别#
- 聚簇索引其实就是指,当你搜索到B+树的叶子之后, 叶子里存的就是数据行了,因此叶子的左右都是与自己索引值相邻的数据行,可以串起来直接一起获取。
- 而非聚簇索引时, 当你搜到叶子时, 叶子里依然只有索引值, 而后面的指针才指向真正的位置, 这意味着数据行的存放是不连续的, 没有办法用一根线串起来。
聚簇的优点#
- 可以一次性读取到 某主键范围的所有行,减少磁盘IO
- 相比非聚簇,少跑一层(就是最后一层)。
聚簇的缺点#
- 如果数据都放在内存中,就没优势了,毕竟非聚簇通过指针一样很快。
- 更新聚簇索引会很慢,因为会重新组织B+树重新移动。
- B+树插入新行时,可能导致叶子节点的页出现分裂,导致更多的空间。(聚簇索引的叶子非常大!)
非聚簇的话都是指针,数据不放在叶子中,也就不会出现那种大叶子的分裂。
聚簇和非聚簇的对比#
Innodb都是聚簇索引,叶子节点一般就是数据,数据按顺序存储了。
MyIsam都是非聚簇索引, 叶子节点还是索引,凌乱指向存储位置。
Q: 什么是回表?#
A:
非聚簇索引查询时, 因为最终只查到的是主键值,最终还需要经过聚簇索引找到数据行
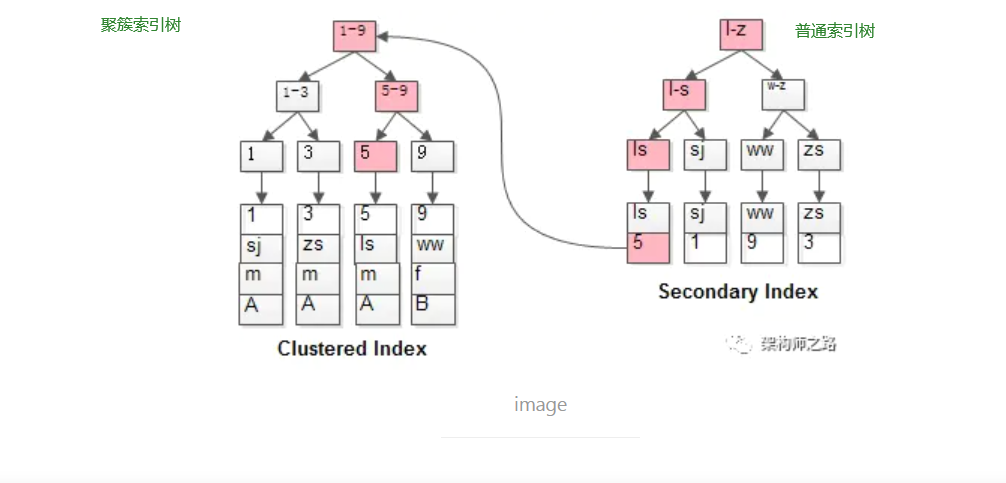
如粉红色路径,需要扫码两遍索引树:
- 先通过普通索引定位到主键值id=5;
- 在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低
Q: 那么当发生回表时,怎么避免呢?#
A:
把普通索引列升级到联合主键中。
例如将单列索引(name)升级为联合索引(name, sex),即可避免回表(代价是name要放到第一个,或者sex in ‘男,女’)
Q: 非主键索引a, 做where a>3时, 能充分利用索引做简单的范围读取么?#
A:
不能。
因为非主键索引最终还是要做回表, 到主键(聚簇)索引树中进行查询。此时a>3是无法直接取出一堆数据的。
mysql5.5之前, 是每个a>3的记录都进行随机回表读取数据。
mysql5.5之后,做了一个MR2优化
- 当a>3的记录不是很多时, 会读取到内存中
- 接着按照主键id(聚簇索引)进行排序
- 然后根据id排序后的情况进行回表, 如果有一堆id都是挤在一起的,就对这一批id进行范围查询。
二级索引和主键#
- 注意, 如果有1个key(xx)加一个primKey(yy), 相当于有2个索引(主键默认索引)
而这2个索引的意思是指:
建立了2个B+树!!
对于主键的B+树, 数据就放在叶子
而对于另一个索引的B+树, 叶子节点是主键+索引, 后面才是指向数据 - 即对于聚簇索引,如果存在主键和二级索引,则选择主键做聚簇, 二级索引和非聚簇索引的B+树没两样。
Q: 主键索引和唯一索引有什么区别呢?#
A:
- 主键索引一定是唯一索引, 但唯一索引不一定是主键。
- 主键索引列默认不支持空值, 而唯一索引本身没有这个限制。
- 主键产生唯一的聚集索引(即聚集索引和主键相关),非主键唯一索引产生唯一的非聚集索引
- 唯一索引可以有多个, 但是主键只能有一个。
Q: 确定不能有多个主键索引吗?那泛式里提到的多个主键是怎么回事呢?#
A:
-
数据库的每张表只能有一个主键,不可能有多个主键。
-
所谓的一张表多个主键,我们称之为联合主键。
注:联合主键:就是用多个字段一起作为一张表的主键。
- 主键的主键的作用是保证数据的唯一性和完整性,同时通过主键检索表能够增加检索速度。
索引的插入#
索引插入的规范#
- 尽量保证在插入时是按索引的顺序插入的
- 如果没按顺序插入,会导致经常性的中间分页,移动数据。性能可以差距四倍以上。
- 所以尽量选用自增的id做索引,尽量不要用随机的UUID做大批量插入的操作。
- 如果用了UUID做插入,插入之后还要要用一个命令
Optimize Table 表名
来重建表并优化页的填充 - 什么时候顺序主键的插入是不好的?
同一时刻并发插入(非单线程插入)的情况
这会导致在 数据表末尾发生激烈的竞争冲突(如果是随机的反而可以避免这个情况) P171
Q: 为什么自增id可能会出现不连续的情况?#
A:
插入时,如果insert语句中不包含id,但是id设成了自增
mysql此时就会从某个自增表中申请一个主键,当申请成功之后,就会拿着这个主键+1去做真实的Insert操作。(注意,是先申请,再插入)
如果主键/唯一键冲突,或者事务回滚, 这个自增id不会回滚。 下一次会继续主键+1使用。
因此
Q: 为什么自增id不能回滚呢?#
A:
为什么不回退,是避免回退导致重复的冲突,也为了避免太大范围的锁
- 避免回退导致多个id同时插入引发重复的冲突,也为了避免太大范围的锁
- 自增主键比较大的作用是避免页分割,我们只需要数据是递增而无需连续
其他索引#
覆盖索引#
指查询语句中 只有索引相关的列。
- 这样的话,可以不需要回表访问聚簇索引树了, 直接拿索引节点里的索引结果返回,效率非常高。
- 全覆盖的情况比较少见,一般用于
先用覆盖索引的查询语句得到一个小表
再利用这个小表的结果对原表做查询(相当于省去了一些条件里的判断) - Explanin 解析时,如果extra显示 using index,则说明使用了覆盖索引。
用索引做排序#
- 索引和排序语句写对的话,可以不需要弄临时表做排序,直接按照顺序取出返回即可。
- 索引列的顺序, 必须和order by中声明的索引顺序一致
- 即你的key是(a,b,c), 那么oder by a b c才行,不能打乱顺序
- order by 索引满足 前缀定理, 即必须是 a 或者 a+b或者 a+b前缀
- 特例: 如果where中定义了a=‘某个常量’, 那么order by中只需要b和c也满足 前缀定义。
- 如果是范围就不行了
压缩(前缀索引)#
- 就是把索引在存储的做压缩,减少字节数
- 例如第一个索引是perform, 第二个是performance, 那么第二个存储的时候就表示为7,ance
- 可以在Create Table语句中指定PACK_KEYS来控制索引压缩
- 压缩索引主要是为了减少磁盘和内存占用量, 但因为压缩了,每次到节点时要先解开压缩再计算(即只有用到才解压),再去查找,会降低性能。
重复索引#
primary key、 unique(key)、 index(key)这3个本质上都会形成索引,很容易有人定义了主键后, 又给主键加个索引, 这就会出现多个相同的B+树。
冗余索引#
- 创建了索引(A,B)之后, 又创建了(A), 那么就是冗余, 因为(A,B) 可以实现单独A的索引功能。
- 所以尽量修改索引,而不是去新增索引, 新增索引容易出现冗余索引。
- 修改索引的缺陷: 可能导致一些老的查询语句的性能下降。
例如本来是用索引(A) + 主键ID排序做查询, 那个脚本一直在跑很正常, 后来改成了索引(A.B) + 主键ID排序, 于是原先的脚本性能GG, 因为A和ID被B分开了(只是我们看不到ID放在我们定义的key里)
未使用的索引#
- 就是定义了但是平时不用的索引!
- 定位未使用索引的方法: 打开userstates变量, 然后让服务器运行几天之后, 查询INFORMATION_SCHEMA.INDEX_STATISTICS用来查看索引的使用频率。
- 具体见P188
索引和锁#
- 索引能够减少访问的行数,从而减少锁的数量
索引应用#
多种过滤条件优化#
- 如果我们的索引是 sex country age, 但是我们的查询里不关心sex,怎么办? 如果不走sex,索引就失效了
可以在where中加入 sex in (‘m’,‘f’) 这样就能用到sex了 - 原则1:
枚举少的放前面, 这样可以用in方式来处理 - 原则2:
经常范围性查询的索引列放后面 ,例如age, 毕竟范围查的话,后面的索引就肯定用不了了。
避免多个范围条件#
- mysql会把in(1,2,3)和 >1 and < 3 都认为是range的type, 不过在索引的使用, in之后还可以接其他索引, 但是大于1小于3就不行了
- 如果出现了 lastoneline > xxx and age between x and y
这种2个范围的索引查询,就会导致age索引失效 - 一种优化的办法: 如果lastoneline > xxx 仅仅是表示 这个用户是否未过期,则可以新增一个经常维护的字段active,来吧lasttime>xxx的这个条件转成true和false这两种值。
- 那么后面就可以改成lastline = true and age between… 了, 用等值的话,就不会影响后面的索引
Q: 写入表的时候, 为什么一般建议自增的主键id来写入?#
A:
因为底层的索引本质上是B+树
有页分裂
如果id随机,则写入时会碎片化,无法做到顺序写