[toc]
垂直分表#
Q: 什么是垂直分表? 一般怎么分的?#
A:
将一个表按照字段分成多表,每个表存储其中一部分字段。
垂直分表原则:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
Q: 什么情况下需要分表, 提升是什么?#
当有些字段内容比较大,且访问频次比较低时, 可能会导致表的大小非常大,但是用途很小。
例如 商品信息表里, 商品详情表可能字段更多文字也更多,倾向于将详情表单独拆一个出来。 这样业务层可以在真正需要用到详情表的时候,再根据商品id去查就行了。
提升:
1.为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
2.充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
Q : 为什么大字段的效率低呢?#
A:
- 由于数据量本身大,读取整行记录需要更长的读取时间;
- 跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好。而大字段占用空间大,单页内存储行数少,因此IO效率较低。
- 数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
水平分表#
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
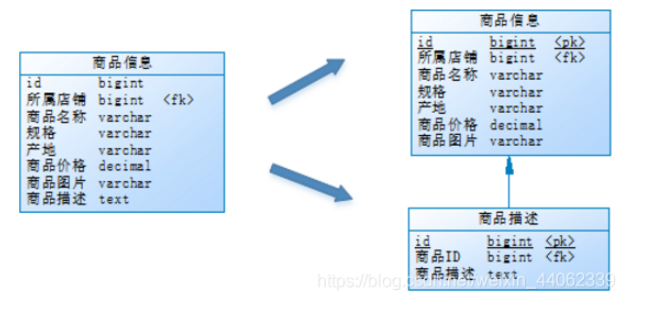
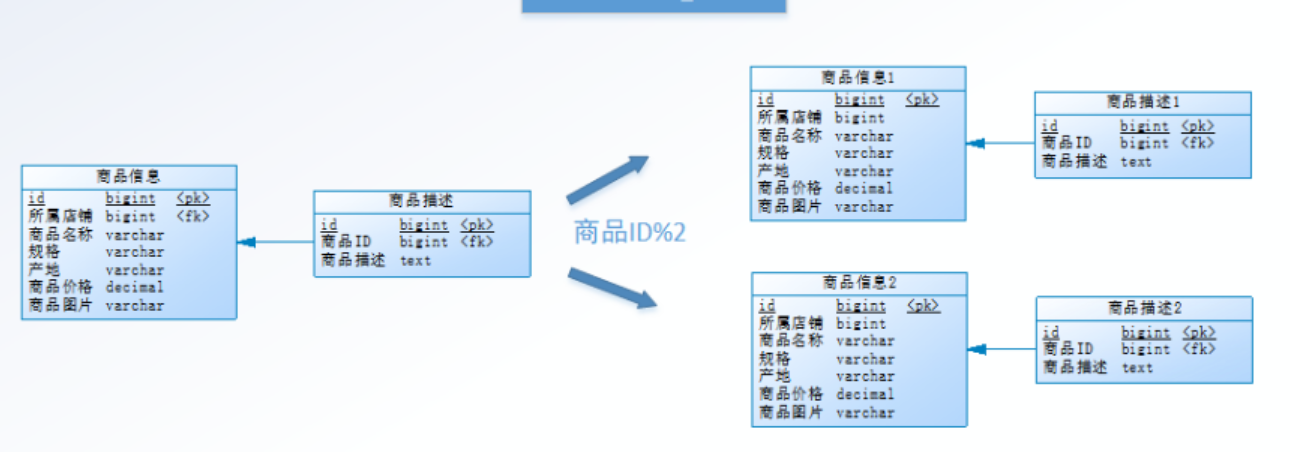
以商品表为例:
商品信息及商品描述被分成了两套表。
- 如果商品ID为双数,将此操作映射至商品信息1表;
- 如果商品ID为单数,将操作映射至商品信息2表。此操作要访问表名称的表达式为商品信息[商品ID%2 + 1]
Q: 垂直分表和水平分表的区别?#
A:
垂直分表,是对字段列做划分。 而水平分表,是对数据行做划分。
其实可以把表成下面这种结构,就明白垂直和水平的区别了
Q: 水平分表的好处?#
A:
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
垂直分库#
和垂直分表类似, 只不过根据业务类型,将不同业务的表放到的不同的数据库
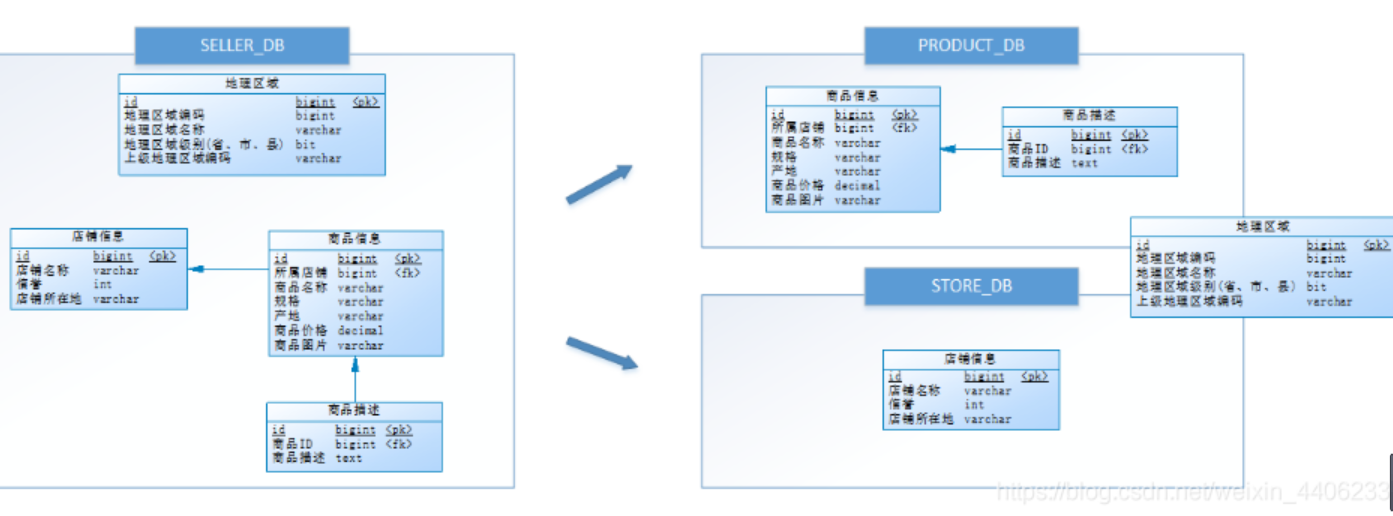
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用
Q: 已经做了垂直分表了,为什么还要垂直分库?#
A:
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求, 当两类表的数据量持续增加时,磁盘空间肯定会不够,毕竟数据还是始终限制在一台服务器(例如用户和商品持续增长)。
即库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
Q: 垂直分库的好处#
A:
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
- 垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库#
当业务上无法再进行垂直拆分时,但是库的容量不够时,就只能水平分库了。
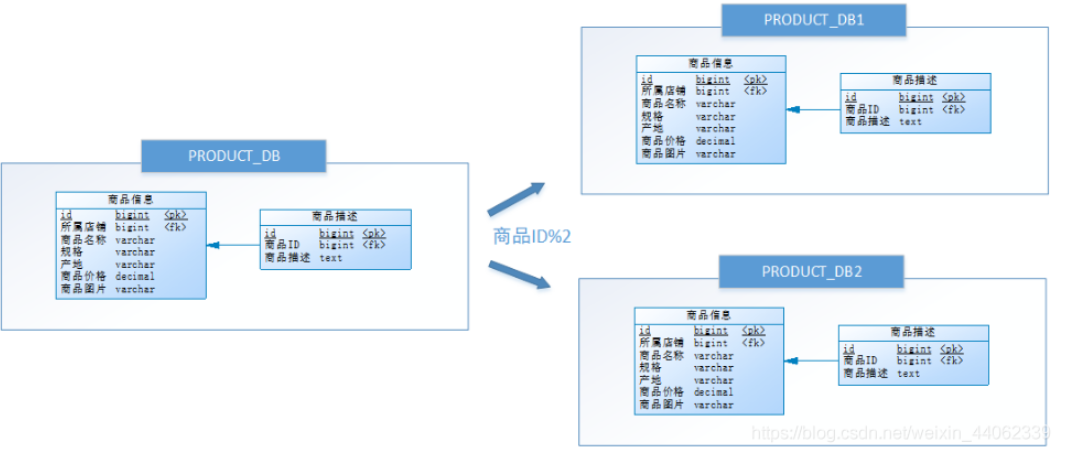
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上,但是不影响表结构
- 例子:
操作某条数据,先分析这条数据所属的店铺ID。如果店铺ID为双数,将此操作映射至RRODUCT_DB1(商品库1);如果店铺ID为单数,将操作映射至RRODUCT_DB2(商品库2)。此操作要访问数据库名称的表达式为RRODUCT_DB[店铺ID%2 + 1]
好处:
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性。
Q: 如果水平分库后,又不够用了,数据要做迁移吗?即怎么做平滑扩展#
A:
水平分库如何做到平滑扩展
- 停服迁移。
适用于特定时间段用户几乎无法登录或者操作的产品,或者有权限控制用户不允许使用的。 - 从库升级。
可以理解为原本作为容灾的从库, 直接升级为可以被哈希映射的主库, 加入到水平分库的哈希映射中。
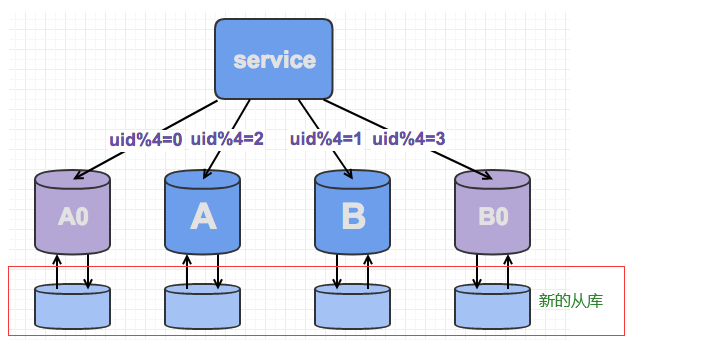
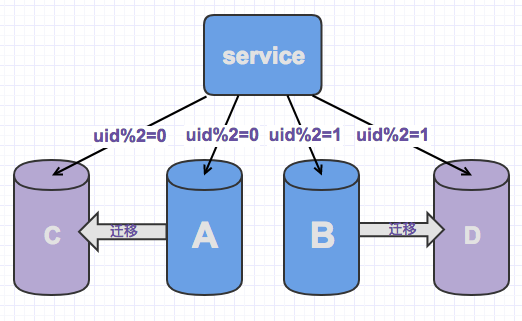
- 双写迁移
用于未设置从库,或者必须新增更多的库时(从库一次只能*2)。
- 设置新的分片库,要求库内为空。 同时记录一下当前时间或者当前记录号。
- 业务层增加逻辑,将相同哈希的数据多写一份到新库(注意此时新库只能被写,但是不能被读)
- 将老记录通过工具迁移到新库,尽量全部迁移
- 迁移完成后,校验,确保两边已经完全一致(其实类似于生成了一个从库)
- 开放新的分片规则。 去除冗余数据。
Q: 从库迁移中, 从库中有之前备份的数据,怎么办?#
A:
备份数据不影响使用,只要哈希正确,冗余数据不会干扰。
但可以安排一个特定时间进行冗余数据清理, 且清理过程不会影响自己所映射的数据一致性。
Q: 一致性哈希有了解吗? 和水平分库有什么关系?#
A:
如果是简单哈希, 上面提到的扩容中,可能一次变动就要所有的库都涉及迁移。
但我可能只想增加一台呢? 也要全部都变动吗?
为了尽可能少迁移,只迁移1-2个库,引入一致性哈希。 这样只要改动哈希空间中相邻的即可
具体原理这里有提到服务缓存设计
分库分表设计问题#
Q: 分库分表会带来什么负面影响?#
A:
- 无法使用部分外键约束
- 多表join连接的sql查询,可能需要改造成多次单表查询(注意,分库分表场景下,尽量都用多次单表查询,可读性提高, 牺牲少数性能而已)
- 无法继续使用数据库自身提供的方法生成全局唯一id。
Q: 那你的产品要引入分库分表的话, 怎么实现? 自己写代码吗?#
A:
不需要,有完善的分库分表中间件。
Shark、mycat、tddl。
以shark为例 , shark依赖于spring, 只需要通过依赖注入方式配置shark的各种属性、分库分表路由算法,即可使用
业务层调用dao的代码不需要任何变化。
基于AOP拦截jdbcTemplate中除了batch()方法以外的所有读/写方法
利用druid的sqlparse完成sql语句的解析工作。
Q: 分库分表之后, 全局且连续的唯一id如何生成?#
A:
如果不考虑连续, 则生成时结合uuid、机器ip、时间戳等多个维度因素生成即可。
如果要考虑连续,有两种方式
- 利用分表中间件的id生成器, 例如shark,可以配置一个单点id数据库, 需要id时, 应用里的shark会去这个id数据库申请一批id, 缓存在本地。
利用了行锁保证了并发环境下的数据一致性。 - 建立一个id生成服务, 需要的时候走这个单点服务去申请(单点服务自身有个mysql),代价比较大。
Q: 分库分表之后, 可能一个表被拆成多个表, 但是原先某个业务查询sql涉及了其中的多个条件, 搜索变得非常慢,应该怎么处理?#
A:
可以把数据导入到solr中, 让solr进行分词搜索。
另外如果有比较耗时的like查询,也可以导入给solr让solr做like模糊查询。
Q: 垂直分表后, 可能会产生 冗余表, 即分成卖家表和买家表后, 他们表里都需要订单信息, 因此订单信息需要同步2次给2个表。 这个过程你会如何设计?#
A:
-
自己在业务层实现双写逻辑。 订单服务写入买家表之前, 把卖家表的请求扔给异步消息队列, 这样就是一边异步一边同步,加快速度。
而卖家表如果插入成功了, 就再发一个响应消息给消息队列, 订单服务消费到这个响应后,才能确认写入成功,短时间内收不到则就进行数据补偿类似于重发。 (也叫线上检测补偿) -
借助某些已经实现的中间件做mysql数据库的binlog增量同步。(阿里的canal)。
它会伪装salve节点,向master节点索要binlog, 然后解析binlog后,完成冗余表的数据增量同步,就不需要业务层写代码了,配置canal中间件即可。
Q: 大表怎么分页查询?#
A:
给时间加索引,然后利用offset+limit即可
select * from t_msg order by time offset 200 limit 100
Q: 分库分表后,怎么做分页查询?#
以offset 900 limit 60, 3个库为例
A:
4种方法。
-
全局视野法
用于数据量不大的情况
每次直接取limit 960, 然后在服务端进行排序后手动算出offset 900的位置。 -
禁止跳页。
只提供下一页。这也可以用全局视野拿到第一页后, 记录此时选到的时间。
下一页的时候, 用3个库里记录的那个时间做排序再去取第二页即可。 -
模糊查询
当数据获取要求的精确度不高,且数据确定是均匀分布的
则直接按offset 300 limit 20去取3份合成一页即可。 -
二次查询法
比较复杂。
- ① 先分别offset 300 limit 60, 得到3份数据。
- ② 得到3份数据中的最小时间tmin, 这个时间的前面300份是可以被“肯定的”
- ③ 记录另外2个库(就是没取到最小时间的那2个)的时间最大值tmax1, tmax2
- ④ 按 time>tmin and time < tmax1 和 time>tmin and time<tmax2 的where索引查询再取2份数据。
- ⑤ 这也就能知道tmin 在3个库里的相对位置是多少了, 例如在库1里排300名,在库2里排250名, 在库3里排270名。
- ⑥ timin排820名,而刚才取的数据合并起来后,再取个80条,就能找到limit 900的位置了。
也有缺点, 就是极端情况下还是不太好用,例如库2和库3的分布机器不均匀。
业界难题-“跨库分页”的四种方案